目录
https://arxiv.org/abs/2409.05591
论文概述:
该论文的标题为《MEMORAG: 向记忆启发的知识发现移动的新一代RAG》。该论文由北京人工智能研究院和中国人民大学高瓴人工智能学院的研究人员撰写,提出了一种新的检索增强生成(RAG)框架,名为MemoRAG。MemoRAG的核心创新在于结合了长时记忆模型,以解决传统RAG在处理隐式信息需求和非结构化知识时的局限性。论文的主要贡献包括:
- 引入全局记忆模块,通过压缩长文本上下文,生成提示线索,提升信息检索的效率和准确性。
- 提出双系统架构,结合轻量级和强大的语言模型,分别负责记忆存储和复杂问题解答。
- 提供了基于多领域复杂任务的基准测试集(ULTRADOMAIN),展示了MemoRAG在复杂问题上的显著性能提升。
方法与原理:
MemoRAG的基础是检索增强生成(RAG),其核心公式为:
其中, 表示生成模型, 表示检索模型, 为输入查询, 为从数据库 中检索出的上下文, 为最终生成的答案。在传统RAG中,检索模块主要依赖显式的查询匹配,难以处理隐式信息需求。
为解决这一问题,MemoRAG引入了记忆模块,通过轻量级的LLM(长上下文处理能力)生成初步的答案草稿。这一过程可以形式化为:
其中, 是通过记忆模块生成的中间答案草稿,作为检索的提示。记忆模型通过上下文压缩技术将数据库中大量的内容进行全局语义存储,并利用这些存储的提示信息进行进一步的精确检索。
记忆模型的实现:
在记忆模块中,MemoRAG使用了一种基于Transformer的注意力机制来实现语义压缩。每个上下文窗口生成少量记忆token,这些记忆token通过附加的权重矩阵进行处理,生成紧凑的全局语义表示,公式如下:
通过这种方式,MemoRAG能够在多个上下文窗口内逐步将短期记忆转换为长期记忆,并在需要时从这些长期记忆中提取关键线索。
实验与结果:
该论文使用了一个名为ULTRADOMAIN的基准测试集,对MemoRAG进行了多方面的评估,测试涵盖了金融、法律、教育等多个领域的复杂任务。这些任务包括隐式查询、多步推理和信息聚合,传统RAG方法在这些任务上表现不佳。实验结果表明,MemoRAG在所有测试任务中均优于现有的RAG方法,特别是在长上下文和多步推理任务上。
例如,在处理金融报告时,MemoRAG可以从数十年的报告中形成全局记忆,并准确找到某一年份的峰值收入。而在多文档问答任务中,MemoRAG通过生成的线索,有效整合了跨文档的信息,实现了更高的问答精度。
讨论与展望:
MemoRAG突破了传统RAG的局限,能够处理更加复杂的隐式查询和长上下文任务。未来的研究方向可能包括:
- 提升记忆模块的效率,使其适应更大规模的数据集。
- 拓展MemoRAG的应用场景,如个性化助手和跨领域知识整合。
总体而言,MemoRAG通过全局记忆和线索生成机制,显著提高了RAG在复杂任务中的性能,为构建智能知识发现系统提供了新的方向。
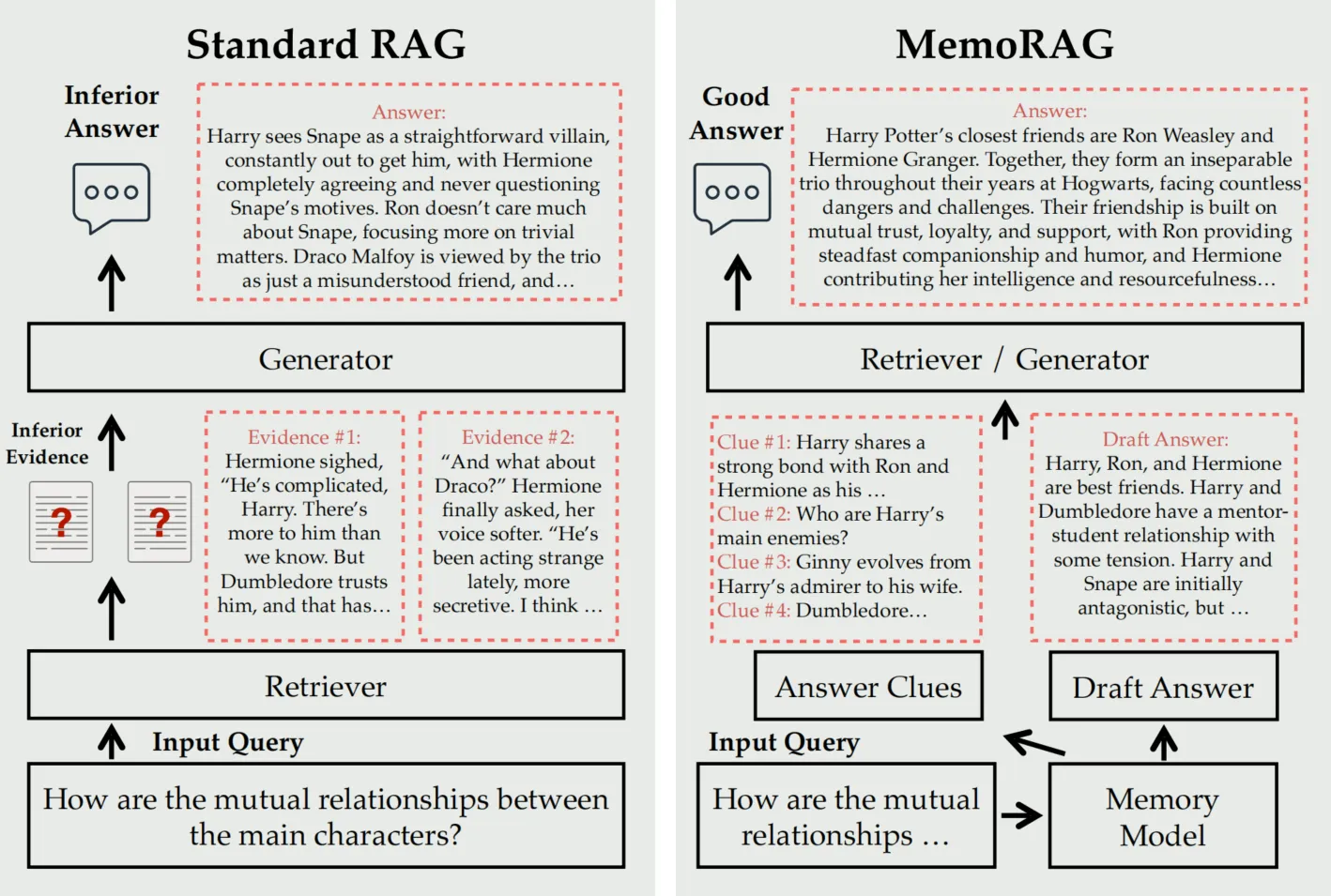
这张图展示了标准RAG(左侧)与MemoRAG(右侧)在处理复杂查询时的区别。
左侧:标准RAG
- 输入查询:用户提出一个问题,例如“主角之间的相互关系是怎样的?”
- 检索器:标准RAG系统会根据输入查询,从数据库中检索相关的证据(Evidence)。
- 证据1 和 证据2:这些是系统从数据库中找到的片段,但它们可能与问题不完全匹配,无法精确地回答问题。
- 生成器:生成器基于检索到的证据生成答案。由于证据不足或不相关,生成的答案也会出现问题。
- 劣质答案:生成的答案并未全面或准确地回答用户的问题,导致信息缺失或不准确。
右侧:MemoRAG
- 输入查询:同样是“主角之间的相互关系是怎样的?”
- 记忆模型:MemoRAG引入了一个记忆模型,该模型会通过对数据库进行全局理解,生成初步的答案草稿。
- 草稿答案:草稿提供了一个初步的结构,展示了关键人物之间的基本关系,例如“Harry、Ron和Hermione是好朋友”。
- 检索线索:MemoRAG利用生成的草稿答案提供了一系列的线索,这些线索帮助检索器在数据库中找到更加精确的证据。
- 线索1到线索4:这些线索明确了哪些信息是检索过程中需要重点关注的,例如“Harry的主要敌人是谁?”或“Ginny如何从崇拜者变为妻子”。
- 检索器/生成器:利用这些线索,检索器可以找到更加相关的证据,生成器基于这些证据生成优质答案。
- 优质答案:最终生成的答案更加全面和准确,回答了问题中的复杂关系,例如Harry、Ron和Hermione的紧密友谊,以及他们在故事中的相互支持。
总结:
- 标准RAG依赖直接的检索和生成,容易导致不准确的答案,特别是在面对复杂问题时。
- MemoRAG通过引入记忆模型,先生成草稿答案并提供线索,优化了检索和生成过程,生成的答案更为准确和相关。
这展示了MemoRAG如何通过全局记忆和线索机制,显著提高复杂任务的性能。


本文作者:Dong
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 CC BY-NC。本作品采用《知识共享署名-非商业性使用 4.0 国际许可协议》进行许可。您可以在非商业用途下自由转载和修改,但必须注明出处并提供原作者链接。 许可协议。转载请注明出处!