目录
有用的信息
https://huggingface.co/Qwen/Qwen2-VL-7B-Instruct/discussions/2
https://github.com/hiyouga/LLaMA-Factory/blob/main/examples/train_lora/qwen2vl_lora_sft.yaml
https://qwen.readthedocs.io/en/latest/training/SFT/llama_factory.html
官网教程: https://zhuanlan.zhihu.com/p/695287607
官方文档:https://llamafactory.readthedocs.io/zh-cn/latest/
数据集如何构建:https://llamafactory.readthedocs.io/zh-cn/latest/getting_started/data_preparation.html
常用指令查询:https://github.com/hiyouga/LLaMA-Factory/tree/main/examples
Qwen2-VL,支持了利用LLaMA-Factory微调Qwen2-VL的语言模型。
构建LLaMA-Factory镜像
镜像环境比较方便,LLaMA-Factory项目更新很快,我以后用日期来标识。
LLaMA-Factory项目:
https://github.com/hiyouga/LLaMA-Factory
拉取:
bash展开代码git clone https://github.com/hiyouga/LLaMA-Factory.git
Build without Docker Compose For CUDA users:
这里要等很久,2~3个小时:
bash展开代码docker build --progress=plain -f ./docker/docker-cuda/Dockerfile \
--network=host --build-arg http_proxy=101.136.19.26:10829 --build-arg https_proxy=101.136.19.26:10829 \
--build-arg INSTALL_BNB=false \
--build-arg INSTALL_VLLM=true \
--build-arg INSTALL_DEEPSPEED=true \
--build-arg INSTALL_FLASHATTN=false \
--build-arg PIP_INDEX=https://pypi.org/simple \
-t kevinchina/deeplearning:llamafactory20240911 .
docker push kevinchina/deeplearning:llamafactory20240911
INSTALL_BNB : BNB没啥用,是qlora训练的。 INSTALL_VLLM:看你模型是否想要vllm部署。 INSTALL_FLASHATTN:这个b安装最耗时,节省点显存,降低一点训练数据。不安装这个build就会快的多。10分钟吧。
把模型路径映射进去:
bash展开代码cd /root/xiedong/LLaMA-Factory
docker run -dit --rm --gpus=all \
-v ./hf_cache:/root/.cache/huggingface \
-v ./ms_cache:/root/.cache/modelscope \
-v ./data:/app/data \
-v ./output:/app/output \
-v ./examples:/app/examples \
-v /root/xiedong/:/xiedong/ \
-p 7861:7860 \
-p 8001:8000 \
--shm-size 16G \
--name llamafactory4 \
kevinchina/deeplearning:llamafactory20240911
进容器:
bash展开代码docker exec -it llamafactory4 bash
pip install git+https://github.com/huggingface/transformers
pip install qwen-vl-utils
LLaMA-Factory基础信息
快速开始
下面三行命令分别对 Llama3-8B-Instruct 模型进行 LoRA 微调、推理和合并。
llamafactory-cli train examples/train_lora/llama3_lora_sft.yaml
llamafactory-cli chat examples/inference/llama3_lora_sft.yaml
llamafactory-cli export examples/merge_lora/llama3_lora_sft.yaml
webui启动:
bash展开代码llamafactory-cli webui
qwen2vl_lora_sft.yaml: 使用的阶段是 sft (Supervised Fine-Tuning),这是标准的监督微调过程,用来通过标注数据对模型进行训练。
qwen2vl_lora_dpo.yaml: 使用的阶段是 dpo (Direct Preference Optimization),这是优化偏好的直接训练方法,常用于强化学习和人类反馈(RLHF)相关的微调。
bash展开代码cd /app/examples/train_lora
-rw-r--r-- 1 root root 757 Sep 4 09:34 qwen2vl_lora_dpo.yaml
-rw-r--r-- 1 root root 694 Sep 4 09:34 qwen2vl_lora_sft.yaml
看一眼sft的配置文件:
yaml展开代码### model
model_name_or_path: Qwen/Qwen2-VL-7B-Instruct
### method
stage: sft
do_train: true
finetuning_type: lora
lora_target: all
### dataset
dataset: mllm_demo,identity
template: qwen2_vl
cutoff_len: 1024
max_samples: 1000
overwrite_cache: true
preprocessing_num_workers: 16
### output
output_dir: saves/qwen2_vl-7b/lora/sft
logging_steps: 10
save_steps: 500
plot_loss: true
overwrite_output_dir: true
### train
per_device_train_batch_size: 1
gradient_accumulation_steps: 8
learning_rate: 1.0e-4
num_train_epochs: 3.0
lr_scheduler_type: cosine
warmup_ratio: 0.1
bf16: true
ddp_timeout: 180000000
### eval
val_size: 0.1
per_device_eval_batch_size: 1
eval_strategy: steps
eval_steps: 500
webui配置一下后可以预览命令:
bash展开代码llamafactory-cli train \ --stage sft \ --do_train True \ --model_name_or_path /root/xiedong/Qwen2-VL-7B-Instruct \ --preprocessing_num_workers 16 \ --finetuning_type lora \ --template qwen2_vl \ --flash_attn auto \ --dataset_dir data \ --dataset mllm_demo \ --cutoff_len 1024 \ --learning_rate 5e-05 \ --num_train_epochs 3.0 \ --max_samples 100000 \ --per_device_train_batch_size 2 \ --gradient_accumulation_steps 8 \ --lr_scheduler_type cosine \ --max_grad_norm 1.0 \ --logging_steps 5 \ --save_steps 100 \ --warmup_steps 0 \ --optim adamw_torch \ --packing False \ --report_to none \ --output_dir saves/Qwen2VL-7B-Chat/lora/train_2024-09-11-07-12-00 \ --bf16 True \ --plot_loss True \ --ddp_timeout 180000000 \ --include_num_input_tokens_seen True \ --lora_rank 32 \ --lora_alpha 128 \ --lora_dropout 0 \ --lora_target all
在LLaMA-Factory中进行多机多卡训练时,可以使用以下命令:
-
节点1:
bash展开代码FORCE_TORCHRUN=1 NNODES=2 RANK=0 MASTER_ADDR=192.168.0.1 MASTER_PORT=29500 llamafactory-cli train examples/train_full/llama3_full_sft_ds3.yaml -
节点2:
bash展开代码FORCE_TORCHRUN=1 NNODES=2 RANK=1 MASTER_ADDR=192.168.0.1 MASTER_PORT=29500 llamafactory-cli train examples/train_full/llama3_full_sft_ds3.yaml
这会启动多节点训练,使用 DeepSpeed 的ZeRO-3分片技术来优化大模型的训练。
单节点使用 DeepSpeed:
bash展开代码FORCE_TORCHRUN=1 llamafactory-cli train examples/train_lora/llama3_lora_sft_ds3.yaml
查看我这里的文章:https://www.dong-blog.fun/post/1682 , 里面也有DeepSpeed的使用。
自定义数据集的样子
如何构建多模态的数据集呢?
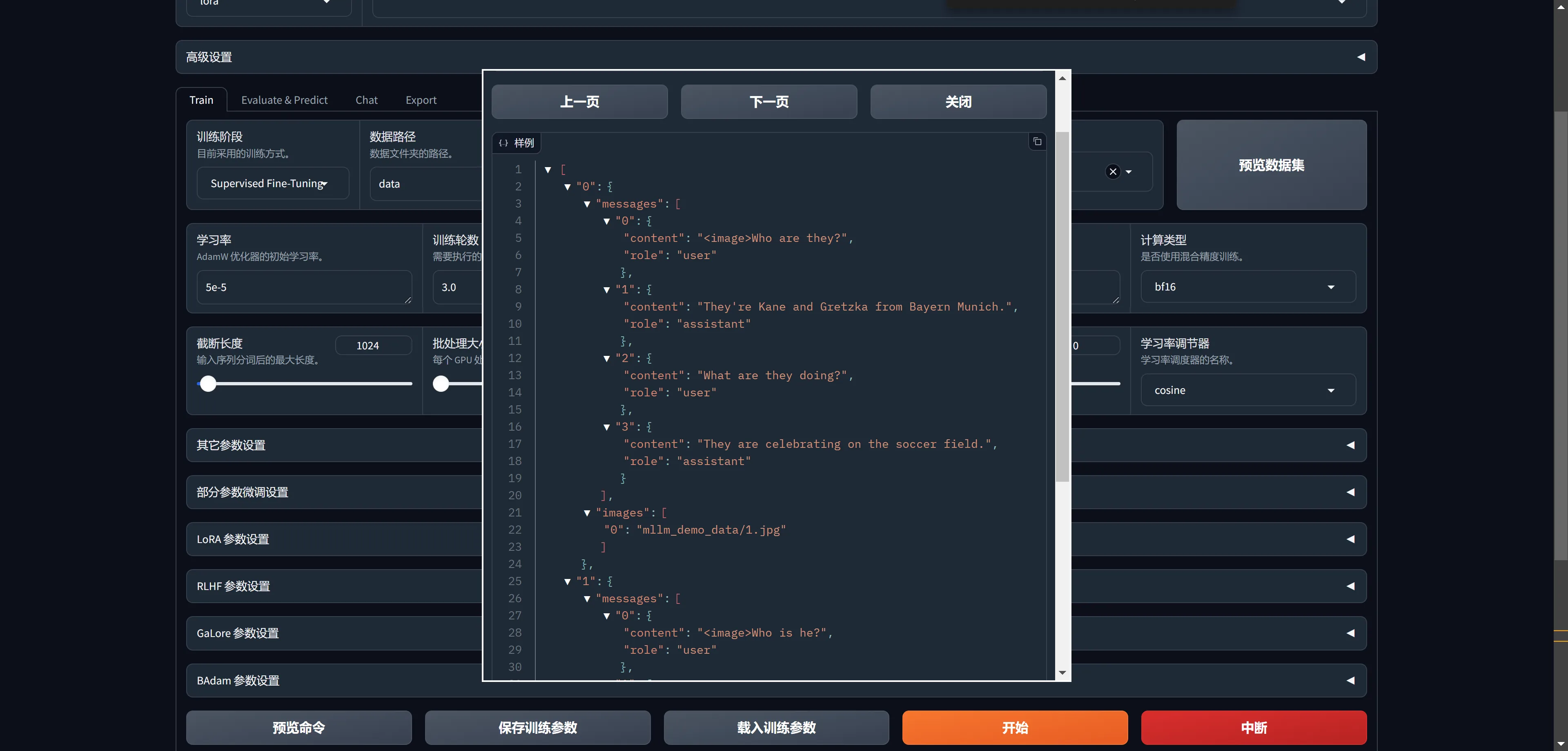
mllm_demo 的样子是这个样子的:
系统目前支持 alpaca 和sharegpt两种数据格式,以alpaca为例,整个数据集是一个json对象的list,具体数据格式为
json展开代码[
{
"instruction": "用户指令(必填)",
"input": "用户输入(选填)",
"output": "模型回答(必填)",
"system": "系统提示词(选填)",
"history": [
["第一轮指令(选填)", "第一轮回答(选填)"],
["第二轮指令(选填)", "第二轮回答(选填)"]
]
}
]
identity.json 里就是这样的格式:
json展开代码[
{
"instruction": "hi",
"input": "",
"output": "Hello! I am {{name}}, an AI assistant developed by {{author}}. How can I assist you today?"
},
{
"instruction": "hello",
"input": "",
"output": "Hello! I am {{name}}, an AI assistant developed by {{author}}. How can I assist you today?"
},
{
"instruction": "Who are you?",
"input": "",
"output": "I am {{name}}, an AI assistant developed by {{author}}. How can I assist you today?"
},
{
"instruction": "What is your name?",
"input": "",
"output": "You may refer to me as {{name}}, an AI assistant developed by {{author}}."
}
]
数据集如何构建:https://llamafactory.readthedocs.io/zh-cn/latest/getting_started/data_preparation.html
Qwen2-VL的mllm_demo数据集是这个样子,看起来多模态的数据集是这样的方式:
json展开代码[
{
"messages": [
{
"content": "<image>Who are they?",
"role": "user"
},
{
"content": "They're Kane and Gretzka from Bayern Munich.",
"role": "assistant"
},
{
"content": "What are they doing?",
"role": "user"
},
{
"content": "They are celebrating on the soccer field.",
"role": "assistant"
}
],
"images": [
"mllm_demo_data/1.jpg"
]
}
]
dataset_info.json里这么写mllm_demo数据集信息的:
json展开代码 "mllm_demo": {
"file_name": "mllm_demo.json",
"formatting": "sharegpt",
"columns": {
"messages": "messages",
"images": "images"
},
"tags": {
"role_tag": "role",
"content_tag": "content",
"user_tag": "user",
"assistant_tag": "assistant"
}
}
dataset_info.json
dataset_info.json 如何给:
json展开代码"数据集名称": {
"hf_hub_url": "Hugging Face 的数据集仓库地址(若指定,则忽略 script_url 和 file_name)",
"ms_hub_url": "ModelScope 的数据集仓库地址(若指定,则忽略 script_url 和 file_name)",
"script_url": "包含数据加载脚本的本地文件夹名称(若指定,则忽略 file_name)",
"file_name": "该目录下数据集文件夹或文件的名称(若上述参数未指定,则此项必需)",
"formatting": "数据集格式(可选,默认:alpaca,可以为 alpaca 或 sharegpt)",
"ranking": "是否为偏好数据集(可选,默认:False)",
"subset": "数据集子集的名称(可选,默认:None)",
"split": "所使用的数据集切分(可选,默认:train)",
"folder": "Hugging Face 仓库的文件夹名称(可选,默认:None)",
"num_samples": "该数据集所使用的样本数量。(可选,默认:None)",
"columns(可选)": {
"prompt": "数据集代表提示词的表头名称(默认:instruction)",
"query": "数据集代表请求的表头名称(默认:input)",
"response": "数据集代表回答的表头名称(默认:output)",
"history": "数据集代表历史对话的表头名称(默认:None)",
"messages": "数据集代表消息列表的表头名称(默认:conversations)",
"system": "数据集代表系统提示的表头名称(默认:None)",
"tools": "数据集代表工具描述的表头名称(默认:None)",
"images": "数据集代表图像输入的表头名称(默认:None)",
"videos": "数据集代表视频输入的表头名称(默认:None)",
"chosen": "数据集代表更优回答的表头名称(默认:None)",
"rejected": "数据集代表更差回答的表头名称(默认:None)",
"kto_tag": "数据集代表 KTO 标签的表头名称(默认:None)"
},
"tags(可选,用于 sharegpt 格式)": {
"role_tag": "消息中代表发送者身份的键名(默认:from)",
"content_tag": "消息中代表文本内容的键名(默认:value)",
"user_tag": "消息中代表用户的 role_tag(默认:human)",
"assistant_tag": "消息中代表助手的 role_tag(默认:gpt)",
"observation_tag": "消息中代表工具返回结果的 role_tag(默认:observation)",
"function_tag": "消息中代表工具调用的 role_tag(默认:function_call)",
"system_tag": "消息中代表系统提示的 role_tag(默认:system,会覆盖 system column)"
}
}
Sharegpt 格式
相比 alpaca 格式的数据集,sharegpt 格式支持更多的角色种类,例如 human、gpt、observation、function 等等。它们构成一个对象列表呈现在 conversations 列中。
注意其中 human 和 observation 必须出现在奇数位置,gpt 和 function 必须出现在偶数位置。
尝试训练
尝试训练一下,看看流程是否畅通。
修改 examples/train_lora/qwen2vl_lora_sft.yaml ,一些部分修改一下:
yaml展开代码### model
model_name_or_path: /xiedong/Qwen2-VL-7B-Instruct # 模型的路径,指定你自己的模型路径。如果你有自定义模型,这里需要改成相应的路径。
### method
stage: sft # 指定训练阶段为 SFT(Supervised Fine-Tuning),这是一个监督微调的阶段。
do_train: true # 表示开始进行训练。
finetuning_type: lora # 使用 LoRA (Low-Rank Adaptation) 方法进行微调。建议避免使用 QLoRA 等其他复杂微调方法,因为 LoRA 效率更高且较为简单。
lora_target: all # 这里指定所有的模型层都将被 LoRA 处理,确保微调应用到整个模型。
deepspeed: examples/deepspeed/ds_z3_config.json # 这个是很猛的降低显存的办法,我加的!!!记住,这么加就行!!!
lora_rank: 32 # 数据多就多给点
lora_alpha: 128 # 数据多就多给点
### dataset
dataset: mllm_demo,identity # 使用的数据集。这里包含两个数据集:mllm_demo 和 identity。你可以使用这些默认数据集或者替换成自己的数据集。
template: qwen2_vl # 数据集的模板,用于定义如何处理输入和输出。
cutoff_len: 1024 # 输入文本的最大长度,超过这个长度的文本将被截断。
max_samples: 1000 # 最多处理的数据样本数量,这里限制为 1000 样本。
overwrite_cache: true # 是否覆盖预处理的数据缓存。如果之前缓存有数据,这里会强制覆盖。
preprocessing_num_workers: 16 # 数据预处理时使用的 CPU 核心数量,指定为 16 个核心以加速处理。
### output
output_dir: output/saves/qwen2_vl-7b/lora/sft_xd # 训练输出的保存路径,所有训练结果将保存到这个目录。可以根据需要修改此路径。
logging_steps: 10 # 每隔 10 步进行一次日志记录,方便跟踪训练进度。
save_steps: 500 # 每 500 步保存一次模型检查点,确保可以在训练中途恢复。
plot_loss: true # 是否绘制损失曲线,开启此选项可以帮助你可视化训练损失的变化。
overwrite_output_dir: true # 是否覆盖之前的输出目录,如果之前有训练结果,这里会将其覆盖。
### train
per_device_train_batch_size: 1 # 每个设备(如 GPU)上的训练批次大小为 1,适合显存有限的设备。
gradient_accumulation_steps: 8 # 梯度累积步数为 8,这意味着每 8 个小批次的梯度将累积后再进行一次更新,等效于增加了有效批次大小。
learning_rate: 1.0e-4 # 学习率设置为 1.0e-4,这是一个较小的学习率,适合微调任务。
num_train_epochs: 3.0 # 训练的总轮数为 3,数据量多的话可以适当增加训练轮次。官方示例中默认使用 3 轮。
lr_scheduler_type: cosine # 使用余弦学习率调度器,学习率将根据余弦函数逐渐减少。
warmup_ratio: 0.1 # 热身比例为 0.1,这意味着前 10% 的训练步骤用于热身,逐渐增大学习率。
bf16: true # 使用 bf16 混合精度训练,能够在不损失太多精度的情况下加速训练。
ddp_timeout: 180000000 # DDP(分布式数据并行)超时设置,确保在分布式环境下不会因为超时导致训练中断。
### eval
val_size: 0.1 # 验证集占数据集的比例为 0.1,表示使用 10% 的数据集进行验证。
per_device_eval_batch_size: 1 # 每个设备上评估的批次大小为 1,与训练的批次大小一致。
eval_strategy: steps # 评估策略为按步评估,意味着每隔一定步数进行一次评估。
eval_steps: 500 # 每 500 步进行一次评估,确保训练期间可以监控模型性能。
执行LLaMA-Factory的指令在/app路径执行,免得遇到问题:
bash展开代码llamafactory-cli train examples/train_lora/qwen2vl_lora_sft.yaml
一会就能跑出结果来:
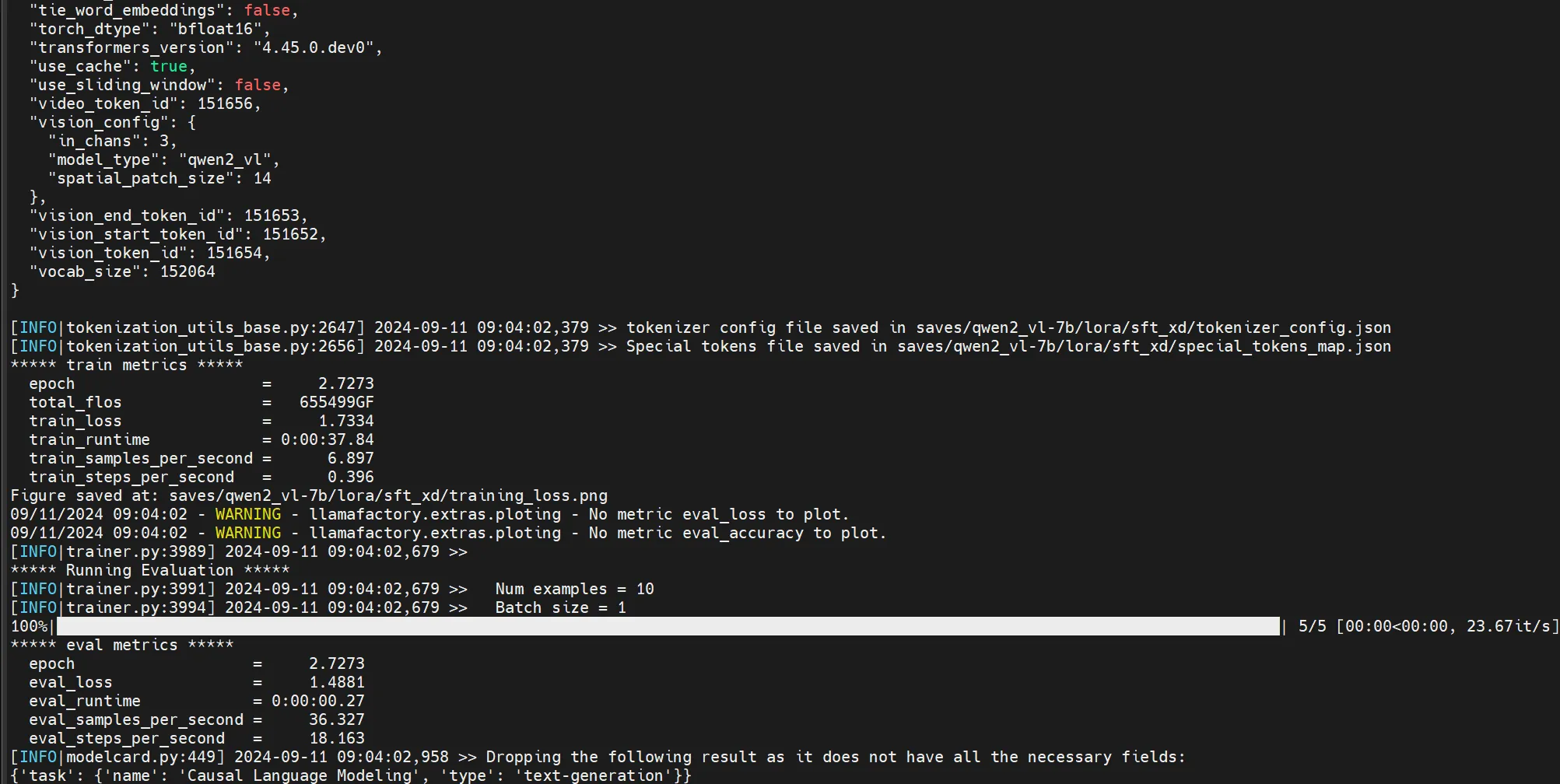
日志里会有一些东西:
- Using torch SDPA for faster training and inference. SDPA其实就是torch的flash att 2技术的实现。
- Upcasting trainable params to float32. 参数类型提升(Upcasting trainable params to float32):可训练参数被提升到 float32 类型。这是为了在训练过程中保证数值稳定性,尤其是当涉及到较低精度(如混合精度训练)时。
- 模型参数统计09/11/2024 09:03:23 - INFO - llamafactory.model.loader - trainable params: 20,185,088 || all params: 8,311,560,704 || trainable%: 0.2429
- 自动混合精度[INFO|trainer.py:668] 2024-09-11 09:03:23,783 >> Using auto half precision backend自动混合精度:表示训练过程使用了自动半精度(FP16)后端。这种技术通常被用来加快训练速度,同时减少内存使用,尤其是在处理大型模型时。半精度训练通过使用16位浮点数来代替32位浮点数进行计算,从而降低计算需求。
- 模型检查点保存[INFO|trainer.py:3673] 2024-09-11 09:04:01,485 >> Saving model checkpoint to saves/qwen2_vl-7b/lora/sft_xd/checkpoint-15
- 训练损失和其他度量指标{'loss': 1.9337, 'grad_norm': 1.3161745071411133, 'learning_rate': 3.226975564787322e-05, 'epoch': 1.82}
- 损失值(loss = 1.9337):训练过程中某一时刻的损失值为1.9337。损失值越低,表示模型性能越好。
- 梯度范数(grad_norm = 1.316):这表示梯度的L2范数,用来衡量梯度的大小,过大的梯度可能会导致梯度爆炸,需要使用梯度裁剪。
- 学习率(learning_rate = 3.226975564787322e-05):当前的学习率为 3.2269e-05,这是优化器更新模型权重的步幅。
- 训练周期(epoch = 1.82):表明当前训练进度是第1.82个epoch。
- 训练结果总结{'train_runtime': 37.8424, 'train_samples_per_second': 6.897, 'train_steps_per_second': 0.396, 'train_loss': 1.7334253629048666, 'epoch': 2.73}
- 训练运行时间(train_runtime = 37.8424s):训练过程总共花费了大约37.84秒。
- 每秒处理的训练样本数(train_samples_per_second = 6.897):平均每秒处理约6.897个样本。
- 每秒训练步数(train_steps_per_second = 0.396):每秒约执行0.396个训练步骤。
- 训练损失(train_loss = 1.7334):最终的训练损失为1.7334。
- 训练周期(epoch = 2.73):模型已经完成了2.73个训练周期。
- 评估结果
bash展开代码***** eval metrics *****
epoch = 2.7273
eval_loss = 1.4881
eval_runtime = 0:00:00.27
eval_samples_per_second = 36.327
eval_steps_per_second = 18.163
定义印章数据集
OpenAI 格式仅仅是 sharegpt 格式的一种特殊情况,其中第一条消息可能是系统提示词。
我估计可以这么定义数据集:
json展开代码[
{
"messages": [
{
"content": "你是一个擅长识别印章上文字的助手,输出json字符串给用户。",
"role": "system"
},
{
"content": "<image>识别图片里红色印章上的公司名称或单位名称(印章主文字)。",
"role": "user"
},
{
"content": "{\"印章主文字\": \"饮酒太原近似收益有限公司\"}",
"role": "assistant"
}
],
"images": [
"/xiedong/yinzhang/save_dst/010155.jpg"
]
}
]
dataset_info.json里这么写:
json展开代码 "seal": {
"file_name": "seal.json",
"formatting": "sharegpt",
"columns": {
"messages": "messages",
"images": "images"
},
"tags": {
"role_tag": "role",
"content_tag": "content",
"user_tag": "user",
"assistant_tag": "assistant",
"system_tag": "system"
}
}
训练印章识别
vim examples/train_lora/qwen2vl_lora_sft_seal.yaml
yaml展开代码### model
model_name_or_path: /xiedong/Qwen2-VL-7B-Instruct # 模型的路径,指定你自己的模型路径。如果你有自定义模型,这里需要改成相应的路径。
### method
stage: sft # 指定训练阶段为 SFT(Supervised Fine-Tuning),这是一个监督微调的阶段。
do_train: true # 表示开始进行训练。
finetuning_type: lora # 使用 LoRA (Low-Rank Adaptation) 方法进行微调。建议避免使用 QLoRA 等其他复杂微调方法,因为 LoRA 效率更高且较为简单。
lora_target: all # 这里指定所有的模型层都将被 LoRA 处理,确保微调应用到整个模型。
deepspeed: examples/deepspeed/ds_z3_config.json # 这个是很猛的降低显存的办法,我加的!!!记住,这么加就行!!!
lora_rank: 32 # 数据多就多给点
lora_alpha: 128 # 数据多就多给点
### dataset
dataset: seal # 使用的数据集。这里包含两个数据集:mllm_demo 和 identity。你可以使用这些默认数据集或者替换成自己的数据集。
template: qwen2_vl # 数据集的模板,用于定义如何处理输入和输出。
cutoff_len: 1024 # 输入文本的最大长度,超过这个长度的文本将被截断。
max_samples: 1000 # 最多处理的数据样本数量,这里限制为 1000 样本。
overwrite_cache: true # 是否覆盖预处理的数据缓存。如果之前缓存有数据,这里会强制覆盖。
preprocessing_num_workers: 16 # 数据预处理时使用的 CPU 核心数量,指定为 16 个核心以加速处理。
### output
output_dir: output/saves/qwen2_vl-7b/lora/sft_xd # 训练输出的保存路径,所有训练结果将保存到这个目录。可以根据需要修改此路径。
logging_steps: 10 # 每隔 10 步进行一次日志记录,方便跟踪训练进度。
save_steps: 500 # 每 500 步保存一次模型检查点,确保可以在训练中途恢复。
plot_loss: true # 是否绘制损失曲线,开启此选项可以帮助你可视化训练损失的变化。
overwrite_output_dir: true # 是否覆盖之前的输出目录,如果之前有训练结果,这里会将其覆盖。
### train
per_device_train_batch_size: 1 # 每个设备(如 GPU)上的训练批次大小为 1,适合显存有限的设备。
gradient_accumulation_steps: 8 # 梯度累积步数为 8,这意味着每 8 个小批次的梯度将累积后再进行一次更新,等效于增加了有效批次大小。
learning_rate: 1.0e-4 # 学习率设置为 1.0e-4,这是一个较小的学习率,适合微调任务。
num_train_epochs: 30.0 # 训练的总轮数为 3,数据量多的话可以适当增加训练轮次。官方示例中默认使用 3 轮。
lr_scheduler_type: cosine # 使用余弦学习率调度器,学习率将根据余弦函数逐渐减少。
warmup_ratio: 0.1 # 热身比例为 0.1,这意味着前 10% 的训练步骤用于热身,逐渐增大学习率。
bf16: true # 使用 bf16 混合精度训练,能够在不损失太多精度的情况下加速训练。
ddp_timeout: 180000000 # DDP(分布式数据并行)超时设置,确保在分布式环境下不会因为超时导致训练中断。
### eval
val_size: 0.1 # 验证集占数据集的比例为 0.1,表示使用 10% 的数据集进行验证。
per_device_eval_batch_size: 1 # 每个设备上评估的批次大小为 1,与训练的批次大小一致。
eval_strategy: steps # 评估策略为按步评估,意味着每隔一定步数进行一次评估。
eval_steps: 500 # 每 500 步进行一次评估,确保训练期间可以监控模型性能。
执行LLaMA-Factory的指令在/app路径执行,免得遇到问题:
bash展开代码llamafactory-cli train examples/train_lora/qwen2vl_lora_sft_seal.yaml
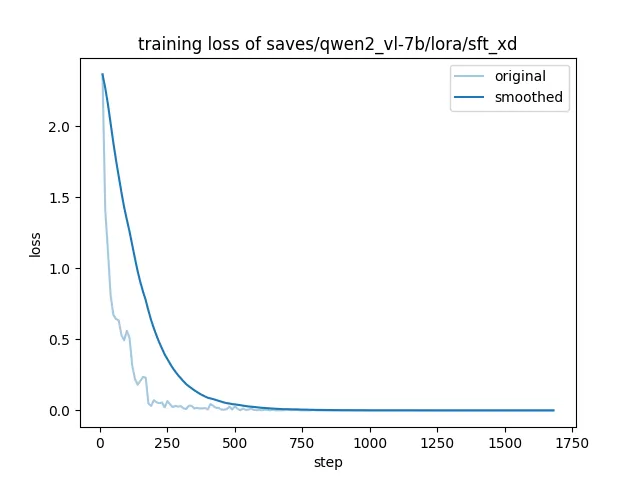
训练损失变化曲线:
webui run模型
bash展开代码/app# llamafactory-cli webui
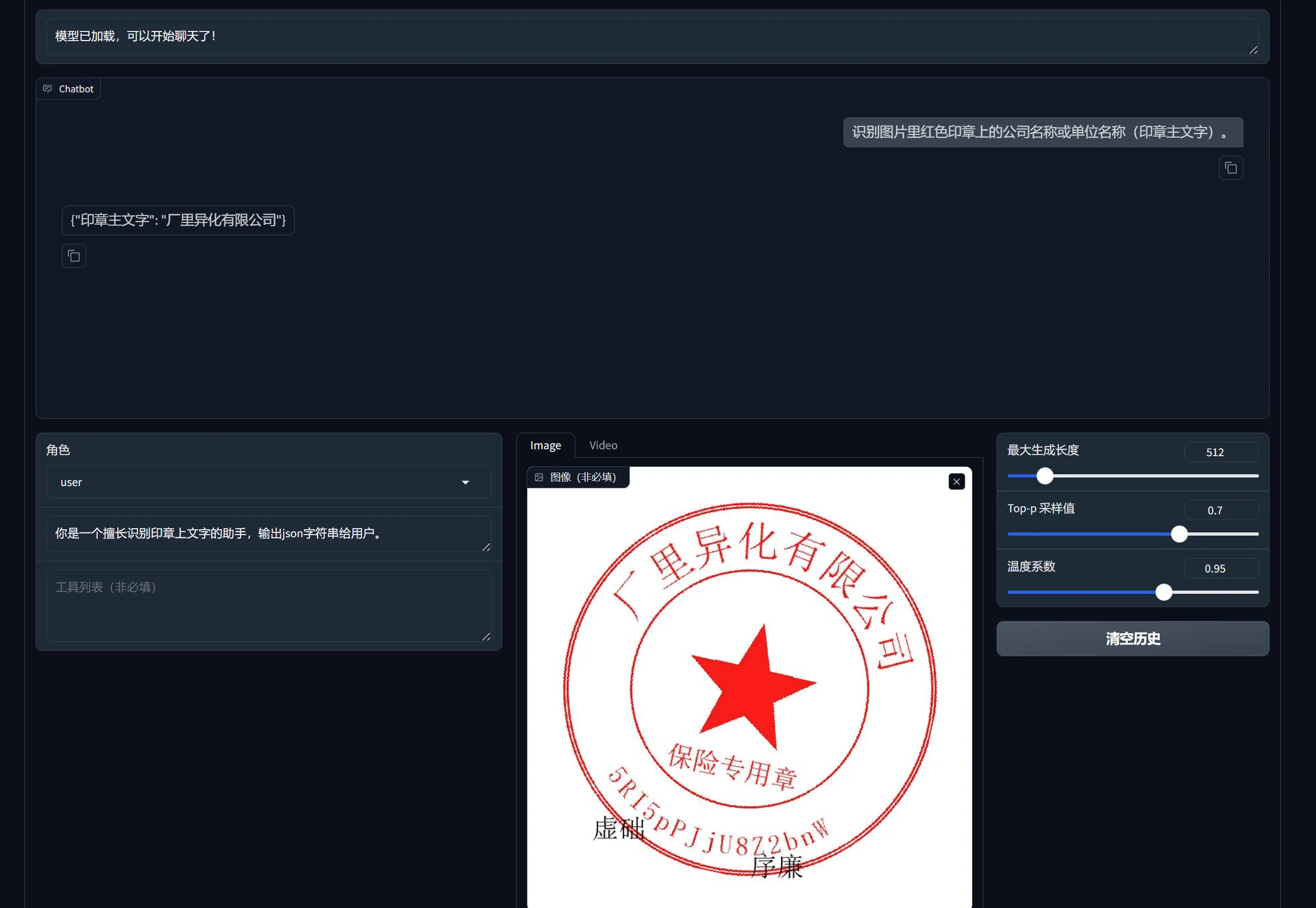
CLI run模型
vim examples/inference/sft_xd_seal.yaml
yaml展开代码model_name_or_path: /xiedong/Qwen2-VL-7B-Instruct
adapter_name_or_path: output/saves/qwen2_vl-7b/lora/sft_xd
template: qwen2_vl
finetuning_type: lora
开启CLI服务:
llamafactory-cli chat examples/inference/sft_xd_seal.yaml
OpenAI-style API run模型
vim examples/inference/sft_xd_seal.yaml
yaml展开代码model_name_or_path: /xiedong/Qwen2-VL-7B-Instruct
adapter_name_or_path: output/saves/qwen2_vl-7b/lora/sft_xd
template: qwen2_vl
finetuning_type: lora
开启:
bash展开代码llamafactory-cli api examples/inference/sft_xd_seal.yaml
容器内部端口8000,被docker run的时候定到8001:



本文作者:Dong
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 CC BY-NC。本作品采用《知识共享署名-非商业性使用 4.0 国际许可协议》进行许可。您可以在非商业用途下自由转载和修改,但必须注明出处并提供原作者链接。 许可协议。转载请注明出处!