【深度学习】Qwen2-VL最强开源OCR模型,手写字体识别、印章识别
目录
Qwen2-VL效果之强
不得不说,Qwen2-VL在OCR、手写字体识别和印章识别上的表现相当出色。它自带文档信息排版功能,特别擅长识别图片中的内容。以下是模型仓库的链接:
- Qwen2-VL GitHub项目:Qwen2-VL
- Qwen2-VL-7B-Instruct Hugging Face模型仓库:Qwen2-VL-7B-Instruct
如何在本地运行Qwen2-VL
-
获取模型文件:
你可以使用以下命令将模型文件克隆到本地:
bash展开代码# 确保已安装 git-lfs (https://git-lfs.com) git lfs install git clone https://huggingface.co/Qwen/Qwen2-VL-7B-Instruct # 如果只想克隆文件指针而不下载大文件 GIT_LFS_SKIP_SMUDGE=1 git clone https://huggingface.co/Qwen/Qwen2-VL-7B-Instruct -
获取Web代码:
接下来,将Qwen2-VL的Web代码克隆到本地:
bash展开代码git clone https://github.com/QwenLM/Qwen2-VL.git -
修改配置文件:
编辑
docker目录下的docker_web_demo.sh文件,并根据你的环境调整以下几个变量:bash展开代码IMAGE_NAME=qwenllm/qwenvl:2-cu121 QWEN_CHECKPOINT_PATH=/root/xiedong/Qwen2-VL-7B-Instruct/ PORT=8902 CONTAINER_NAME=qwen2-vlx如果需要指定显卡使用,可以增加以下配置:
bash展开代码--gpus device=1 -
启动Docker容器:
使用以下脚本启动容器,这将自动从DockerHub拉取镜像并运行Qwen2-VL的Web Demo:
bash展开代码#!/usr/bin/env bash # # 此脚本将从DockerHub拉取镜像并启动一个Qwen-Chat Web Demo容器。 IMAGE_NAME=qwenllm/qwenvl:2-cu121 QWEN_CHECKPOINT_PATH=/root/xiedong/Qwen2-VL-7B-Instruct/ PORT=8902 CONTAINER_NAME=qwen2-vlx # 省略部分代码... sudo docker pull ${IMAGE_NAME} || { echo "拉取镜像 ${IMAGE_NAME} 失败,退出。" exit 1 } sudo docker run --gpus device=1 -d --restart always --name ${CONTAINER_NAME} \ -v /var/run/docker.sock:/var/run/docker.sock -p ${PORT}:80 \ --mount type=bind,source=${QWEN_CHECKPOINT_PATH},target=/data/shared/Qwen/Qwen2-VL-Instruct \ -it ${IMAGE_NAME} \ python web_demo_mm.py --server-port 80 --server-name 0.0.0.0 -c /data/shared/Qwen/Qwen2-VL-Instruct/ && { echo "Web demo启动成功!打开 'http://localhost:${PORT}' 体验! 使用 \`docker logs ${CONTAINER_NAME}\` 检查Demo状态。 使用 \`docker rm -f ${CONTAINER_NAME}\` 停止并移除Demo。" } -
执行脚本:
运行脚本后,即可在浏览器中访问Web Demo界面。以下是一些运行效果截图:
-
显存占用情况:

-
图片识别示例:

-
模型回复示例:
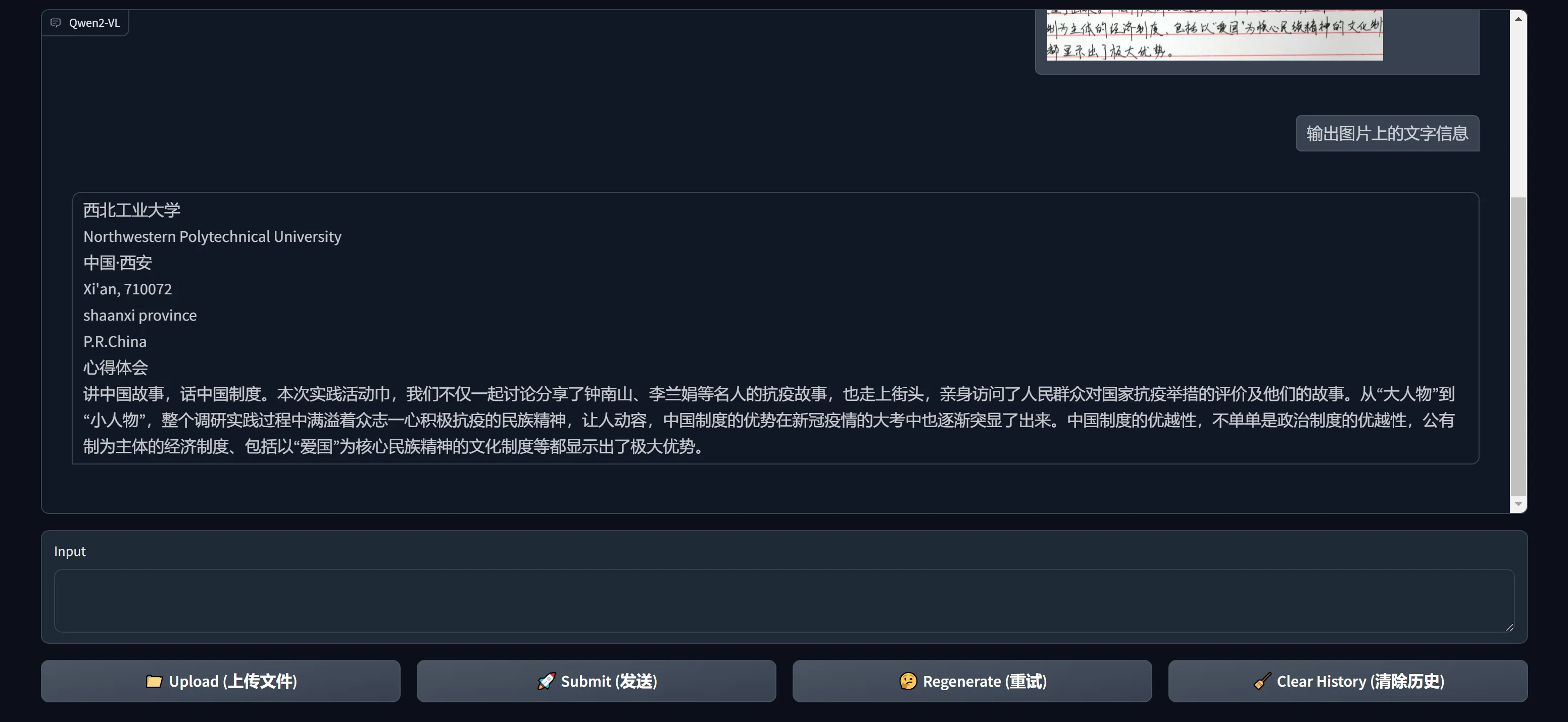
-
印章识别示例:
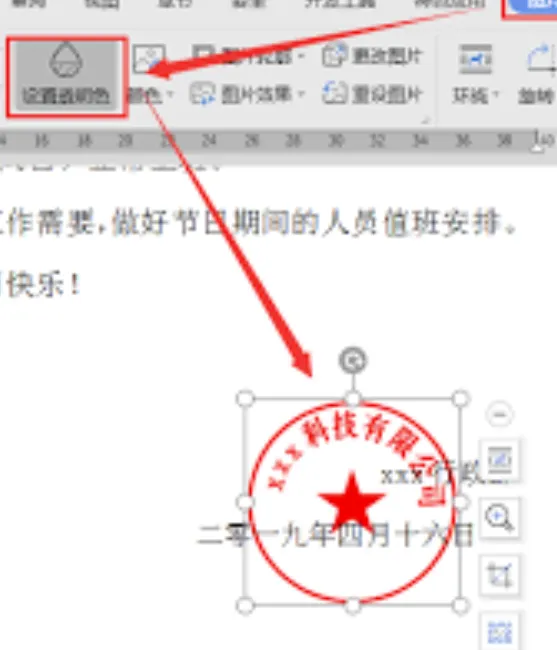
-
模型回复示例:
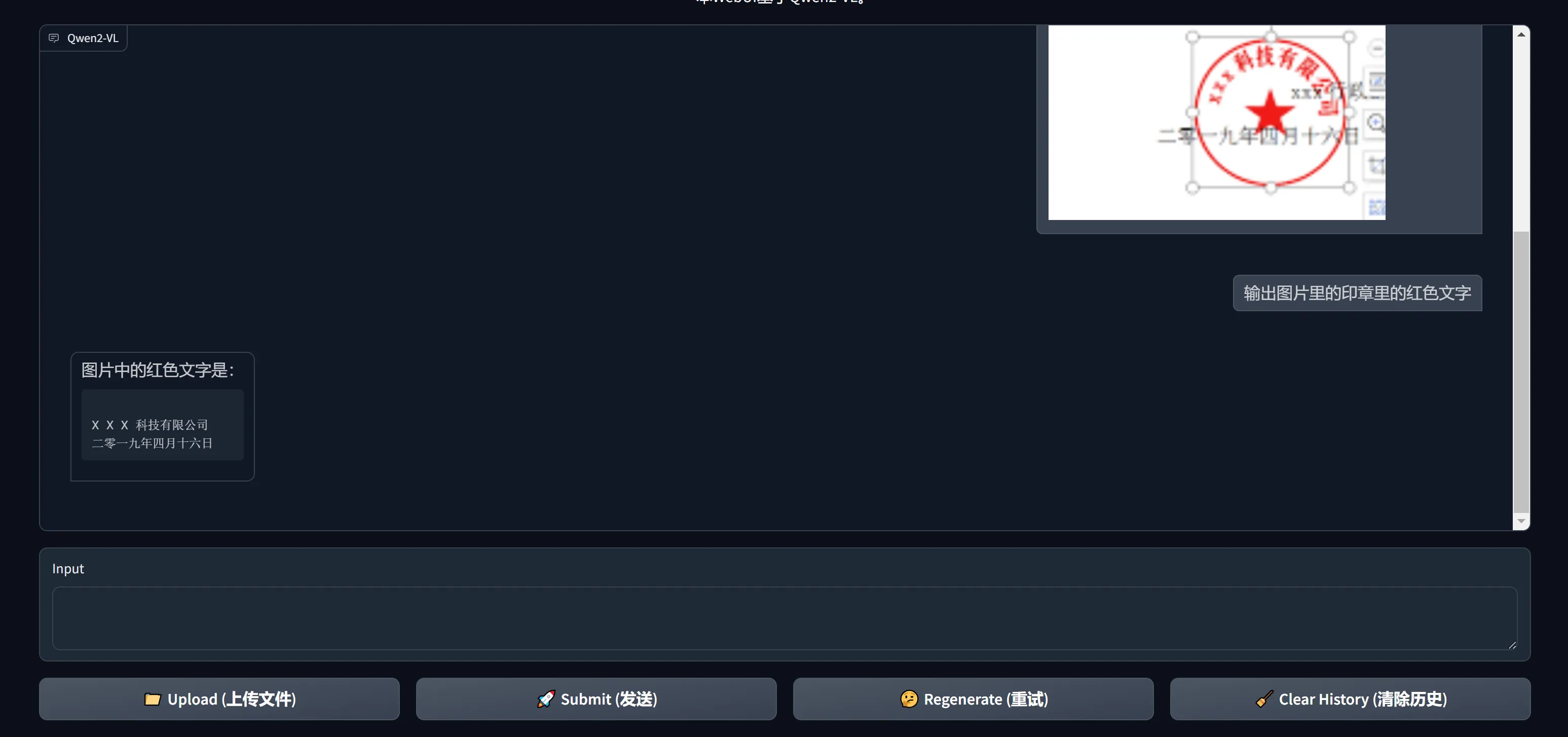
-
直接dockerrun执行的办法
bash展开代码docker run --gpus=all -d --rm --name qwen2-vlx2 \
-v /var/run/docker.sock:/var/run/docker.sock -p 8903:80 \
--mount type=bind,source=/root/xiedong/Qwen2-VL-7B-Instruct/,target=/data/shared/Qwen/Qwen2-VL-Instruct \
qwenllm/qwenvl:2-cu121 \
python web_demo_mm.py --server-port 80 --server-name 0.0.0.0 -c /data/shared/Qwen/Qwen2-VL-Instruct/
bash展开代码docker run --gpus=all -d --rm --name qwen2-vlx2 \
-v /var/run/docker.sock:/var/run/docker.sock -p 8903:80 \
--mount type=bind,source=/root/xiedong/Qwen2-VL-72B-Instruct/,target=/data/shared/Qwen/Qwen2-VL-Instruct \
qwenllm/qwenvl:2-cu121 \
python web_demo_mm.py --server-port 80 --server-name 0.0.0.0 -c /data/shared/Qwen/Qwen2-VL-Instruct/
如果对你有用的话,可以打赏哦
打赏


本文作者:Dong
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 CC BY-NC。本作品采用《知识共享署名-非商业性使用 4.0 国际许可协议》进行许可。您可以在非商业用途下自由转载和修改,但必须注明出处并提供原作者链接。 许可协议。转载请注明出处!
目录