目录
学习 清华大学 尊敬的邓俊辉老师的C++数据结构与算法课程 第10章 优先级队列,本文旨在摘要和心得体会。
1 优先级队列需求
计算机系统里CPU的任务调度,。
不同于队列结构的先进先出,找队列里最大值先出。
约定:优先级队列里的每个数据项目都有一个关键码key,可以进行比较大小(可依靠重载比较操作符实现),关键码越大,优先级越高。
操作接口描述:
| 操 作 接 口 | 功 能 描 述 |
-------- | -----
size() | 报告优先级队列的规模,即其中词条的总数
insert() | 将指定词条插入优先级队列
getMax() | 返回优先级最大的词条(若优先级队列非空)
delMax() |删除优先级最大的词条(若优先级队列非空)
借助无序列表、有序列表、无序向量或有序向量,都难以同时兼顾insert()和
delMax()操作的高效率。而采用一些树结构如平衡二叉搜索树BBST又有点牛刀杀鸡,需要一种轻量级的数据结构,只需要考虑最大值,无需全部排序(无需维护全序,只需要关心“偏序”),使得我们能在效率和消耗上有一个平均,能完成我们需要的ADT接口。
2 完全二叉堆
2.1 定义
何为堆?
-
堆中某个节点的值总是不大于或不小于其父节点的值;
-
堆总是一棵完全二叉树。
常见的堆有完全二叉堆。
由于完全二叉树性质,n个词条组成的堆的高度h = = O(logn)。
基于向量的紧凑表示:
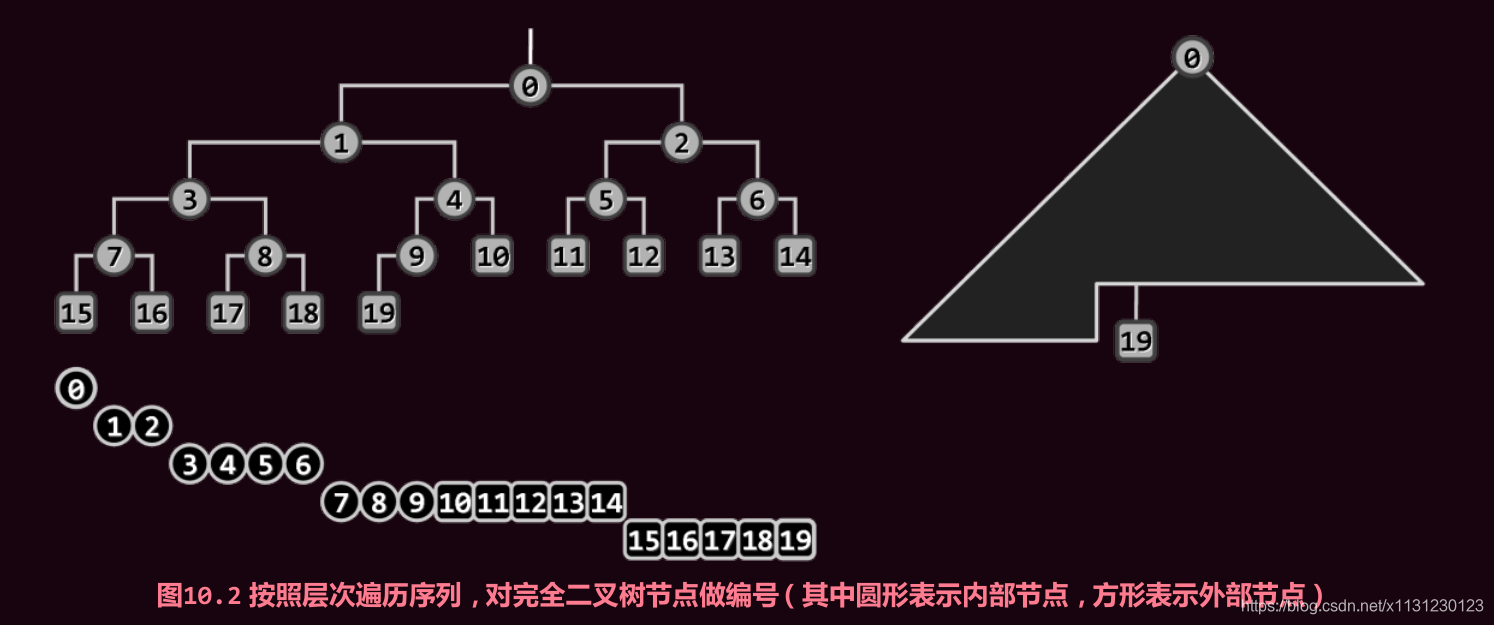
2.2 getMax()
取出最顶端元素的操作即是返回向量的首单元_elem[0]。
2.3 insert() 插入与上滤
插入算法分为两个步骤:
首先将新词条接至向量末尾;
再对该词条实现上滤调整。
cpp展开代码template <typename T> void PQ_ComplHeap<T>::insert ( T e ) {
Vector<T>::insert ( e ); //首先将新词条接至向量末尾
percolateUp ( _size - 1 ); //再对该词条实现上滤调整
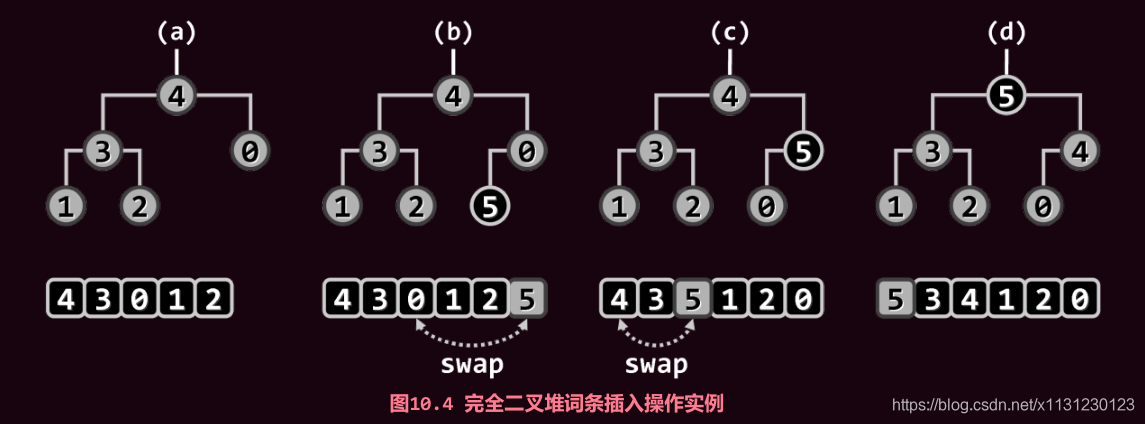
:将插入的新节点与其父节点比较,若大于父节点值,则进行节点交换,交换后再次将这个新插入节点与新的父节点比较;若小于父节点值,则算是完成上滤过程。若来插入的新节点来到堆顶,也算是完成了上滤过程。
整体时间复杂度:O(logn)。
代码里每次需要交换swap需要三次赋值操作,时间复杂度就是3*logn。
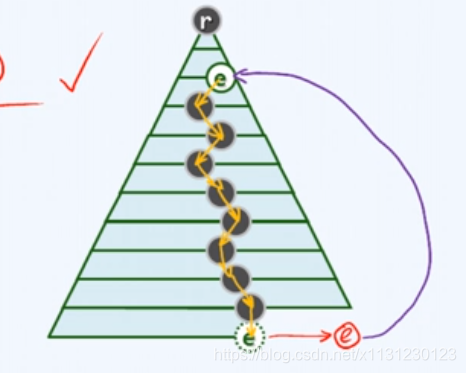
改进后步骤:
(1)插入新节点后,新节点数值赋值给一个副本;
(2)进行不断比较,新节点值大于父节点则需要一次赋值操作(只将父节点值往下移);
(3)直到找到一个父节点比自身大,停止比较,将新节点数值赋值给上次的父节点。
如下图的表示,时间复杂度就是2+logn。
2.4 delMax() 删除与下滤
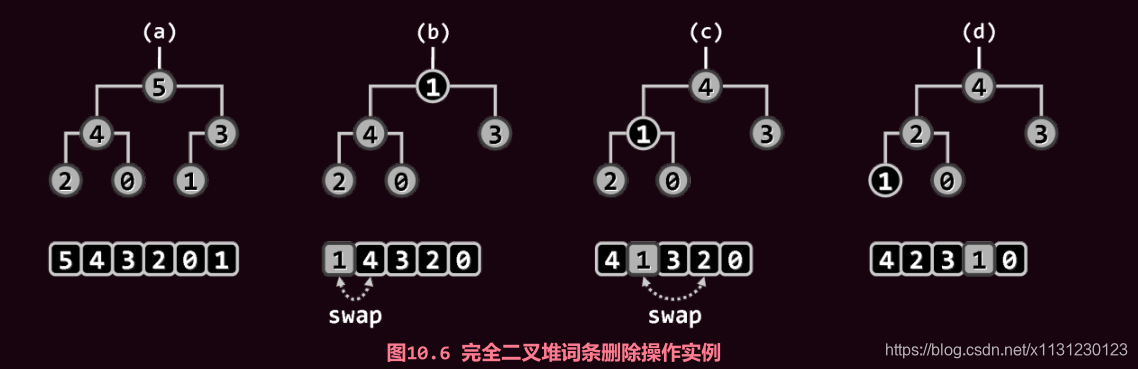
删除算法分为两个步骤:
对新堆顶实施下滤;
返回此前备份的最大词条。
cpp展开代码 template <typename T> T PQ_ComplHeap<T>::delMax() { //删除非空完全二叉堆中优先级最高的词条
T maxElem = _elem[0]; _elem[0] = _elem[ --_size ]; //删除堆顶(首词条),代之以末词条
percolateDown ( _size, 0 ); //对新堆顶实施下滤
return maxElem; //返回此前备份的最大词条
}
:
父节点与子节点的不断的比较与交换,直到下滤完成。
2.5 heapification 建堆
给定一组无序词条,如何快速组建成堆结构?
蛮力算法(自上而下的上滤):
从空堆开始,不断调用insert(),将词条插入。时间复杂度大。
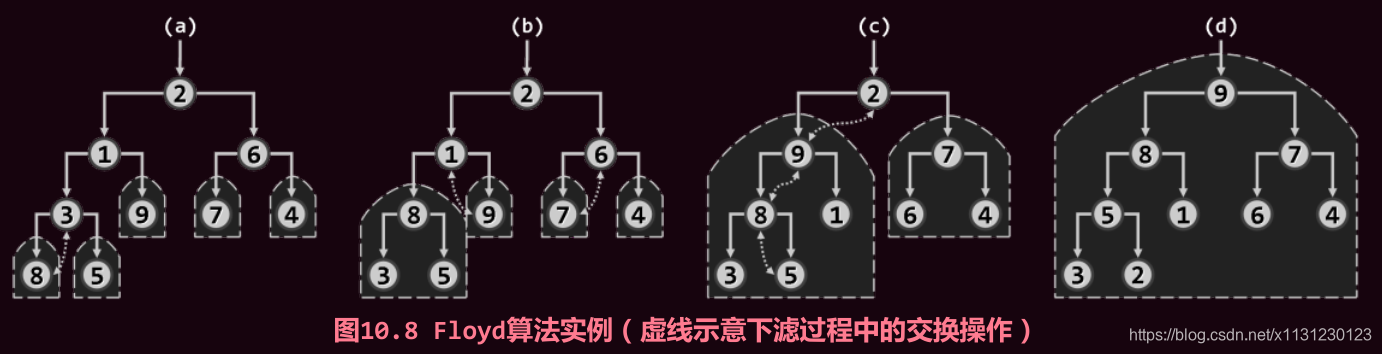
Floyd 建堆算法(自下而上的下滤):
依照层次遍历顺序找到最后一个子节点,不断通过下滤来合并堆(和父节点比较和交换过程)。
时间复杂度
cpp展开代码template <typename T> void PQ_ComplHeap<T>::heapify ( Rank n ) { //Floyd建堆算法,O(n)时间
for ( int i = LastInternal ( n ); InHeap ( n, i ); i-- ) //自底而上,依次
percolateDown ( n, i ); //下滤各内部节点
}
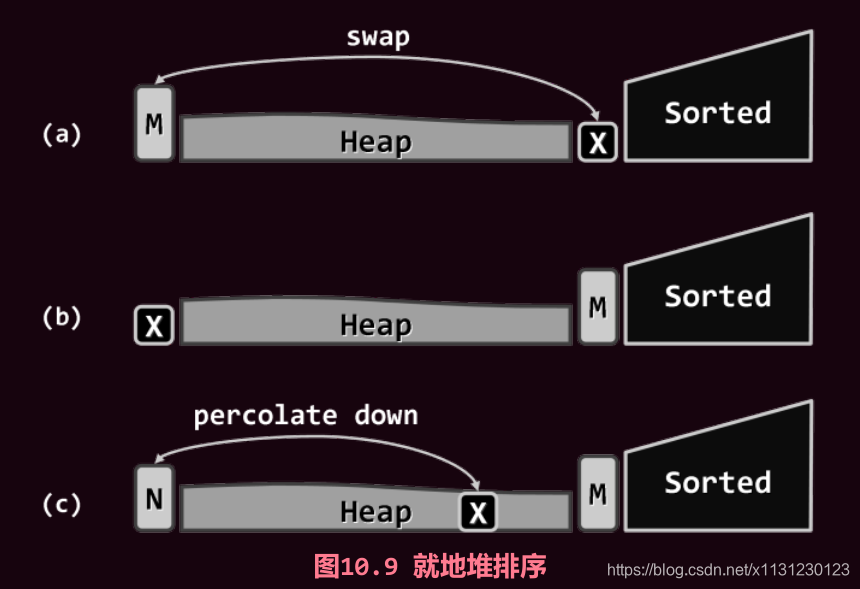
2.6 就地堆排序
M是堆顶元素,和堆尾元素交换,然后对x进行下滤再次将剩余部分组建成堆;重复取出堆顶元素的操作和下滤操作,直至空堆后结束。
cpp展开代码 template <typename T> void Vector<T>::heapSort ( Rank lo, Rank hi ) { //0 <= lo < hi <= size
PQ_ComplHeap<T> H ( _elem + lo, hi - lo ); //将待排序匙间建成一个完全二叉堆,O(n)
while ( !H.empty() ) //反复地摘除最大元并归入已排序癿后缀,直至堆空
_elem[--hi] = H.delMax(); //等效于堆顶不末元素对换后下滤
}
时间复杂度O(nlogn),空间复杂度几乎就地。但算法不稳定。
| 排序方法 | 平均时间 |最好时间 |最坏时间
-------- | -----| -----| -----
桶排序(不稳定) |O(n) |O(n) | O(n)
基数排序(稳定) |O(n) |O(n) |O(n)
归并排序(稳定) |O(nlogn) | O(nlogn) |O(nlogn)
快速排序(不稳定) | O(nlogn) |O(nlogn) | O(n^2)
堆排序(不稳定) | O(nlogn) | O(nlogn) | O(nlogn)
希尔排序(不稳定) | O(n^1.25)
冒泡排序(稳定) | O(n^2) |O(n) |O(n^2)
选择排序(不稳定) | O(n^2) |O(n^2) |O(n^2)
直接插入排序(稳定) |O(n^2) |O(n) |O(n^2)
3 左式堆
3.1 堆合并
有两个堆A和B,需要合并。
不理想的方法一:
反复取出堆B的最大词条并插入堆A中;当堆B为空时,堆A即为所需的堆H。O(mlogn)
不理想的方法二:
用Floyd 建堆算法直接将所有元素重建。O(n)
3.2 左式堆
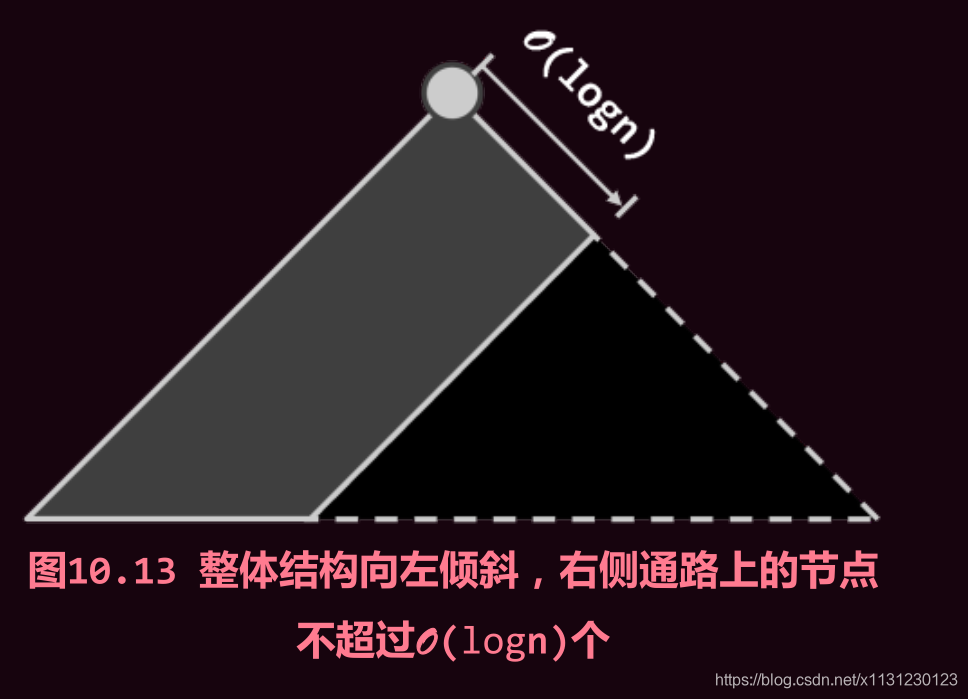
左式堆(leftist heap)是优先级队列的另一实现方式,可高效地支持堆合并操作。
左式堆的节点的分布均偏向左侧,不再满足堆的结构性,故不再使用向量实现,而是采用二叉树。
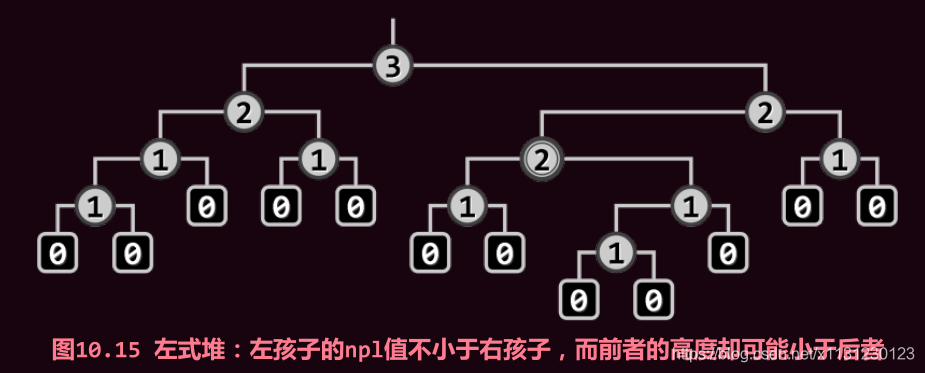
节点x的空节点路径长度(null path length),记作npl(x)。若x为外部节点,则约定
npl(x) = npl(null) = 0。反之若x为内部节点,则npl(x)可递归地定义为:
npl(x) = 1 + min( npl(lc(x)), npl(rc(x)) )
也就是说,节点x的npl值取决于其左、右孩子npl值中的小者。
左式堆是处处满足“左倾性”的二叉堆,即任一内部节点x都满足
npl(lc(x)) >= npl(rc(x))
也就是说,就npl指标而言,任一内部节点的左孩子都不小于其右孩子。
3.3 左式堆合并算法
一言以蔽之:递归地去维护一个左倾。
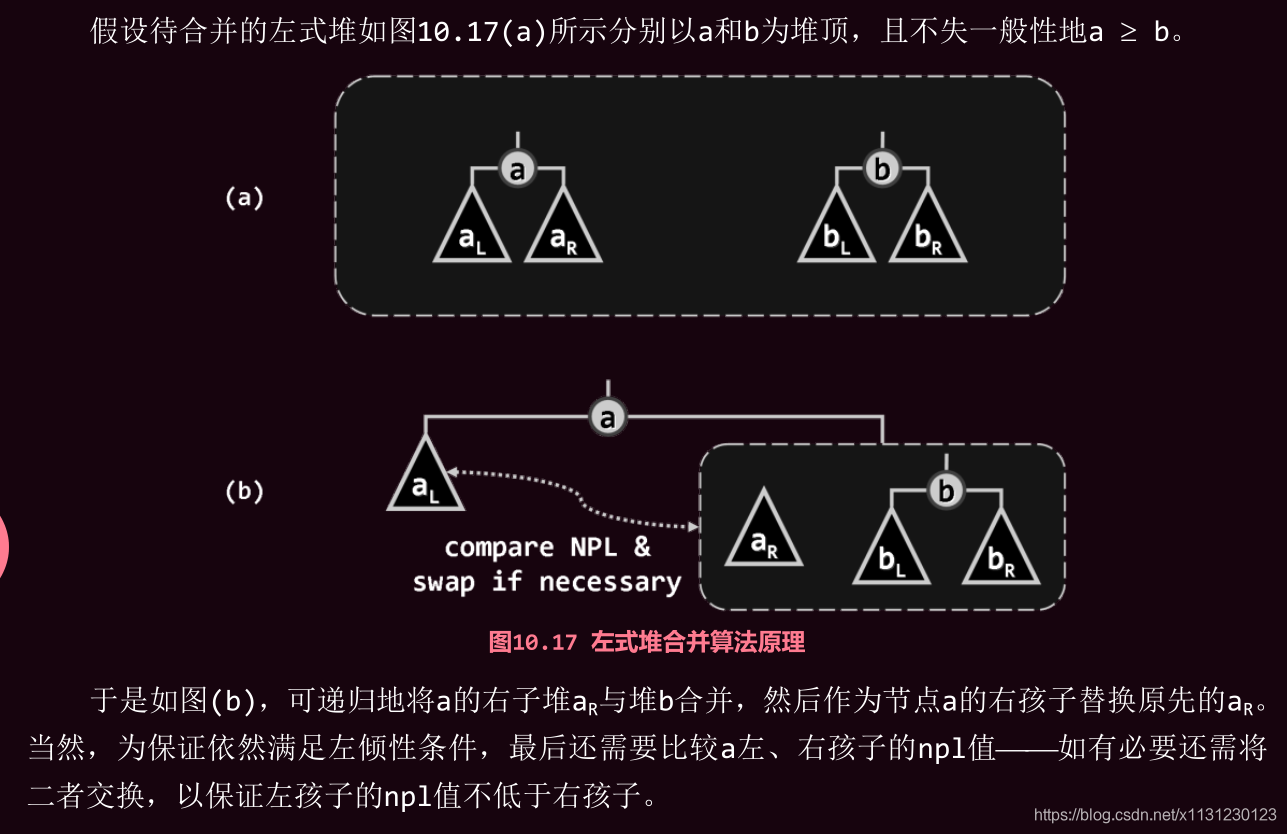
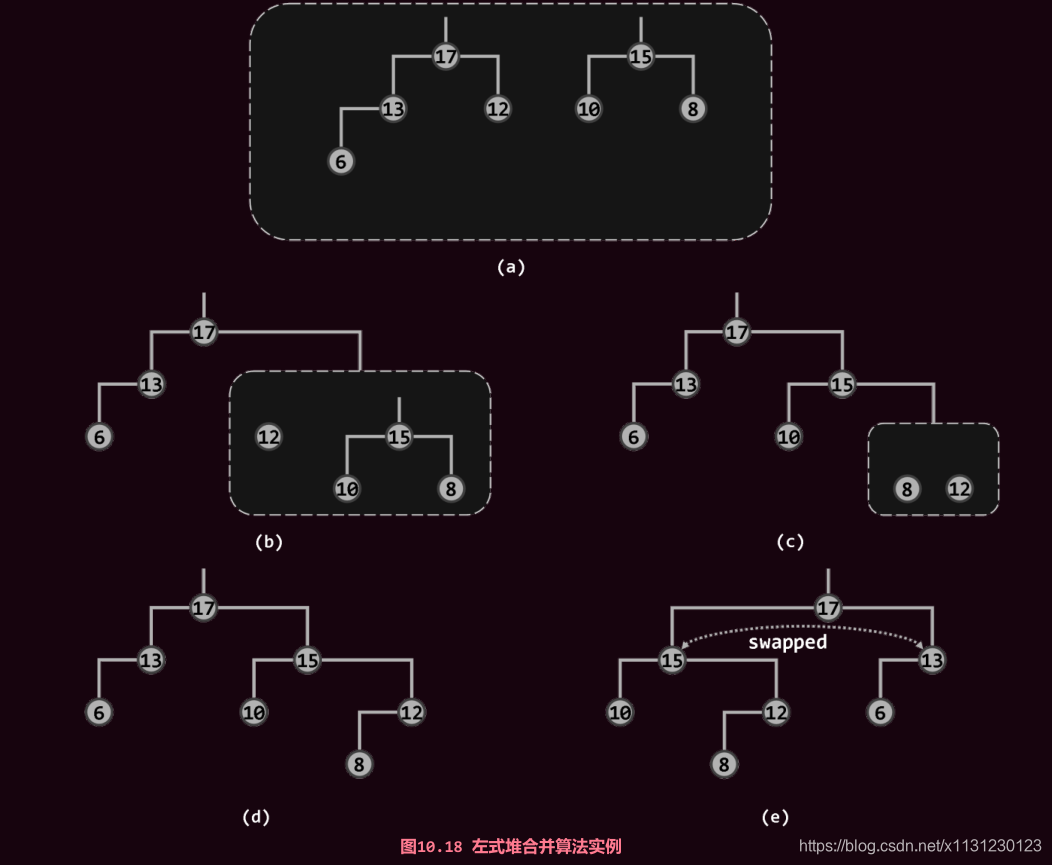


3.4 左式堆 插入
等效于合并:新元素自成一个堆,原来的堆一个堆,两个堆合并。
3.5 左式堆 删除
等效于合并:删除了顶元素,剩下的两个堆合并在一起。
4 python里的heapq
https://docs.python.org/zh-cn/3/library/heapq.html
heapq实现的是最小堆。
Heaps are arrays for which a[k] <= a[2k+1] and a[k] <= a[2k+2] for all k, counting elements from 0.
python展开代码Usage:
heap = [] # creates an empty heap
heappush(heap, item) # pushes a new item on the heap
item = heappop(heap) # pops the smallest item from the heap
item = heap[0] # smallest item on the heap without popping it
heapify(x) # transforms list into a heap, in-place, in linear time
item = heapreplace(heap, item) # pops and returns smallest item, and adds
# new item; the heap size is unchanged
接口:
python展开代码__all__ = ['heappush', 'heappop', 'heapify', 'heapreplace', 'merge',
'nlargest', 'nsmallest', 'heappushpop']
简单使用:
python展开代码import heapq
import random
h = [random.randint(2,100) for i in range(10)]
print("heap is", h)
heapq.heapify(h)
print("heap is", h)
print([heapq.heappop(h) for i in range(len(h))])
print(list(heapq.merge([1,33,5,7], [0,2,4,8], [5,10,15,20], [], [25])))
5 python里的heapq 第二话
https://docs.python.org/zh-cn/3/library/heapq.html
堆是一个二叉树。
层次遍历,为每个节点编号如下。
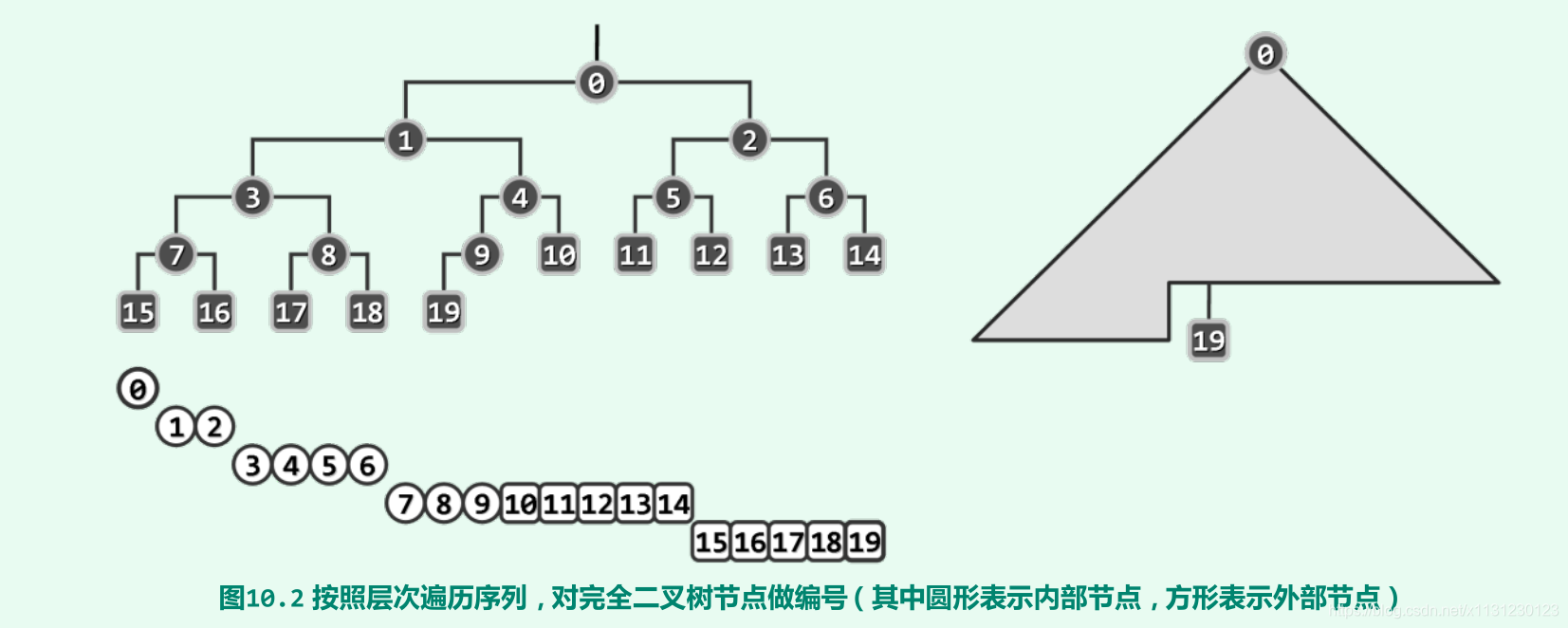
可见,根节点root编号 i(root)=0
如果一个普通节点v的编号记作是 i(v)
那么,节点v的左孩子编号是2*i(v)+1,
节点v的右孩子编号是2*i(v)+2。
python实现的是小顶堆,满足:
heap[v] <= heap[2v+1] 和 heap[k] <= heap[2v+2]。
这个API与教材的堆算法实现有所不同,具体区别有两方面:(a)我们使用了从零开始的索引。这使得节点和其孩子节点索引之间的关系不太直观但更加适合,因为 Python 使用从零开始的索引。 (b)我们的 pop 方法返回最小的项而不是最大的项(这在教材中称为“最小堆”;而“最大堆”在教材中更为常见,因为它更适用于原地排序)。


本文作者:Dong
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 CC BY-NC。本作品采用《知识共享署名-非商业性使用 4.0 国际许可协议》进行许可。您可以在非商业用途下自由转载和修改,但必须注明出处并提供原作者链接。 许可协议。转载请注明出处!