目录
1 香农墒 量化信息 信息量大小
https://baike.baidu.com/item/%E9%A6%99%E5%86%9C%E7%86%B5/1649961?fr=aladdin
1948 年,香农提出了“信息熵”(shāng) 的概念,解决了对信息的量化度量问题。
实质就是:信息不确定性的多少。
对于任意一个随机变量 X,它的熵定义如下:
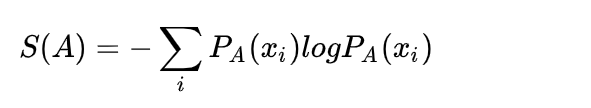
变量的不确定性越大,熵也就越大,把它搞清楚所需要的信息量也就越大。
2 交叉熵
https://www.cnblogs.com/wangguchangqing/p/12068084.html
非常好的解释:https://www.zhihu.com/question/65288314/answer/244557337
KL散度(度量2个概率分布之间的距离差异)公式:
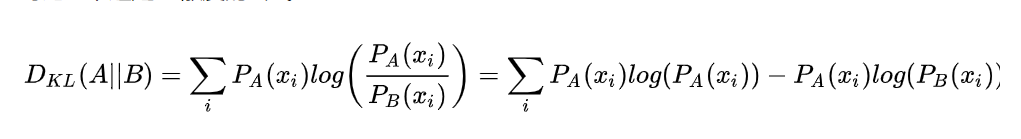
交叉熵公式:
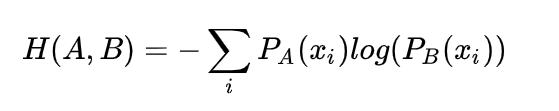
交叉熵=KL散度-熵
KL散度是非负的。
最小化KL散度 等价于 最小化交叉熵。
3 交叉熵损失函数
https://zhuanlan.zhihu.com/p/35709485
https://zhuanlan.zhihu.com/p/35707643
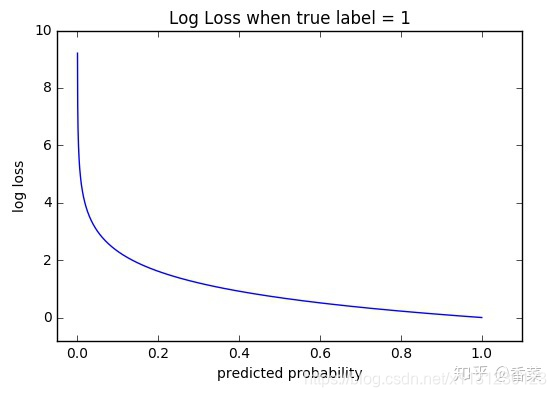
为什么它会在分类问题中这么有效呢?
主要原因是逻辑回归配合MSE损失函数时,采用梯度下降法进行学习时,会出现模型一开始训练时,学习速率非常慢的情况。
使用MSE的一个缺点就是其偏导值在输出概率值接近0或者接近1的时候非常小,这可能会造成模型刚开始训练时,偏导值几乎消失。

Cross Entropy Error Function(交叉熵损失函数)该函数是凸函数,求导时能够得到全局最优值。




本文作者:Dong
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 CC BY-NC。本作品采用《知识共享署名-非商业性使用 4.0 国际许可协议》进行许可。您可以在非商业用途下自由转载和修改,但必须注明出处并提供原作者链接。 许可协议。转载请注明出处!