目录
代码:https://github.com/simon20010923/DDAMFN/tree/main
此算法是当前的第一名:https://paperswithcode.com/paper/a-dual-direction-attention-mixed-feature
介绍
面部表情在人类交流中起着重要作用,是理解情绪和态度的关键信号。因此,计算机需要获得辨识和解释面部表情的能力。[1–3]已经清楚地阐明了视觉感知、环境映射算法与基于生物识别认证计算机视觉的面部表情识别(FER)之间的关系,因此使用深度学习方法解决FER问题是有意义的。FER网络的主流架构通常由主干和头部组成。然而,最近的方法主要集中在头部或颈部区域,并仅使用VGG [4]或ResNet [5]作为其主干。值得注意的是,这些主干最初是为更大的数据集而设计的,可能会从图像中提取冗余信息,在相对较小的数据集中导致过度拟合。本文提出了一种创新的主干网络,称为混合特征网络(MFN)。MFN建立在MobileFaceNets [6]的基础上,这是一个专门为面部验证任务量身定制的轻量级网络。通过引入混合深度卷积核 [7]来增强MFN,这些卷积核利用了不同尺寸卷积核的优势。此外,坐标注意 [8]被引入到MFN架构中,以促进对长距离依赖的捕捉。因此,提取了用于FER的有意义的特征。
此外,FER面临着两个重要挑战:类间差异小和类内差异大。要解决这些挑战,建立各种面部区域之间的连接,如嘴巴、眼睛、鼻子等,至关重要。在这方面,注意机制提供了潜在的解决方案。具体来说,提出了双向注意(DDA)头,该头应用于所提出的方法,旨在根据提取的特征信息构建注意图。根据以前的工作 [8],设计了从垂直和水平方向生成注意图的注意头。随后,将从双向注意网络(DDAN)获得的注意图与输入特征图相乘,得到一个新的特征图。该特征图经过线性全局深度卷积(GDConv)层 [6],然后进行重塑操作。采用全连接层生成最终结果。通过集成所提出的DDA头和后续处理步骤,可以增强模型的能力。
最后,本文将MFN和DDAN集成在一起,提出了一种名为双向注意混合特征网络(DDAMFN)的新模型。
为了直观地展示DDAMFN的有效性,进行了涉及ResNet_50、MFN和DDAMFN模型的比较分析。所有模型都在AffectNet-7数据集上进行了训练,并在相同的测试数据上进行了测试。Grad-CAM [9]被应用于捕获各自主干架构提取的特征的见解。该技术通过基于梯度的定位,促进了通过热图突出显示图像中的重要区域进行预测。该分析的结果在图1中呈现。对结果的综合评估展示了模型之间注意焦点的明显模式。很明显,MFN关注的区域比ResNet_50更特定。对于DDAMFN,DDAN允许MFN定位更合适的区域。
图1。七张图像的热图:中性(第1行),快乐(第2行),悲伤(第3行),惊讶(第4行),恐惧(第5行),厌恶(第6行)和愤怒(第7行)。列1:原始图像。列2:ResNet_50。列3:MFN。列4:DDAMFN(MFN + DDAN)。很明显,MFN关注的区域比ResNet_50更特定。DDAN允许MFN定位更合适的区域。
此外,当在各种基准数据集上进行了大量实验时,DDAMFN模型表现出了显着的性能,将其确立为FER领域的当前最先进网络。我们研究的贡献可以总结如下:
(1)为了增强FER的提取特征的质量,本研究提出了一种名为MFN的新型主干网络。MFN利用不同内核尺寸的利用,从而有助于获得强大的特征。此外,在MFN架构中包含坐标注意层,可以捕捉长距离依赖性,进一步增强了其在FER任务中的有效性。
(2)为了有效检测不同面部表情之间的细微变化,引入了DDAN。通过从两个不同方向生成关注,DDAN旨在全面捕捉相关的面部区域,并提高FER的区分能力。
(3)应用了一种新颖的注意力损失机制,以确保DDAN的注意头聚焦在不同区域,从而显著提高了模型的整体性能和区分能力。
(4)对著名的FER数据集进行了广泛的评估,包括A
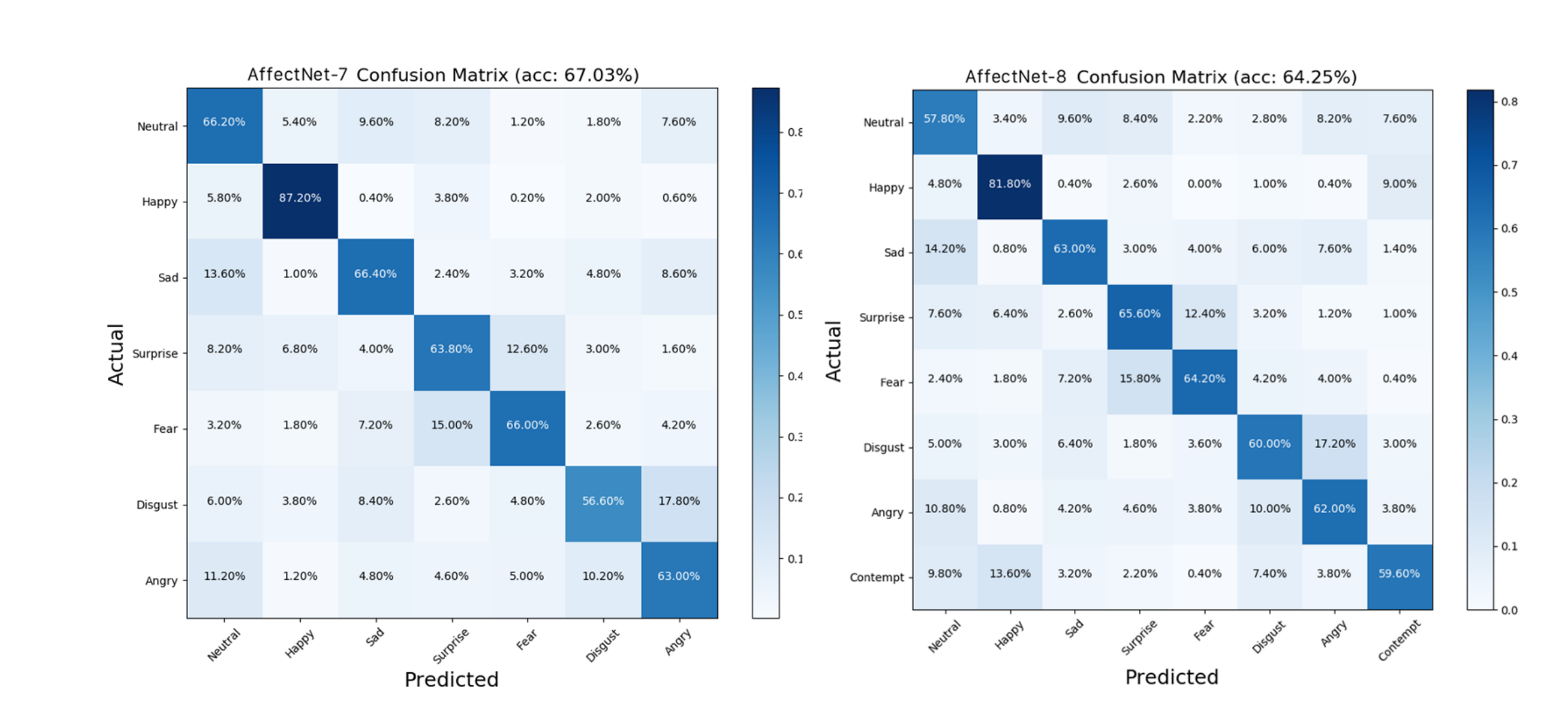
ffectNet、RAF-DB和FERPlus,以评估DDAMFN的性能。实验结果表明,其在AffectNet-7上的准确率为67.03%,在AffectNet-8上为64.25%,在RAF-DB上为91.35%,在FERPlus上为90.74%。这些出色的结果突显了DDAMFN在FER领域的有效性和优越性。
网络结构
DDAMFN的架构概述如图2所示,包括两个主要组件:MFN和DDAN。首先,面部图像被输入到MFN中,产生基本的特征图作为输出。随后,通过DDAN在垂直和水平方向生成注意力图。最终,注意力图被重塑为特定维度,并通过全连接层预测图像的表情类别。
DDAMFN框架有效地结合了MFN的特征提取能力和DDAN的注意机制的判别力。通过整合这些组件,DDAMFN可以在FER任务中实现改善的性能。
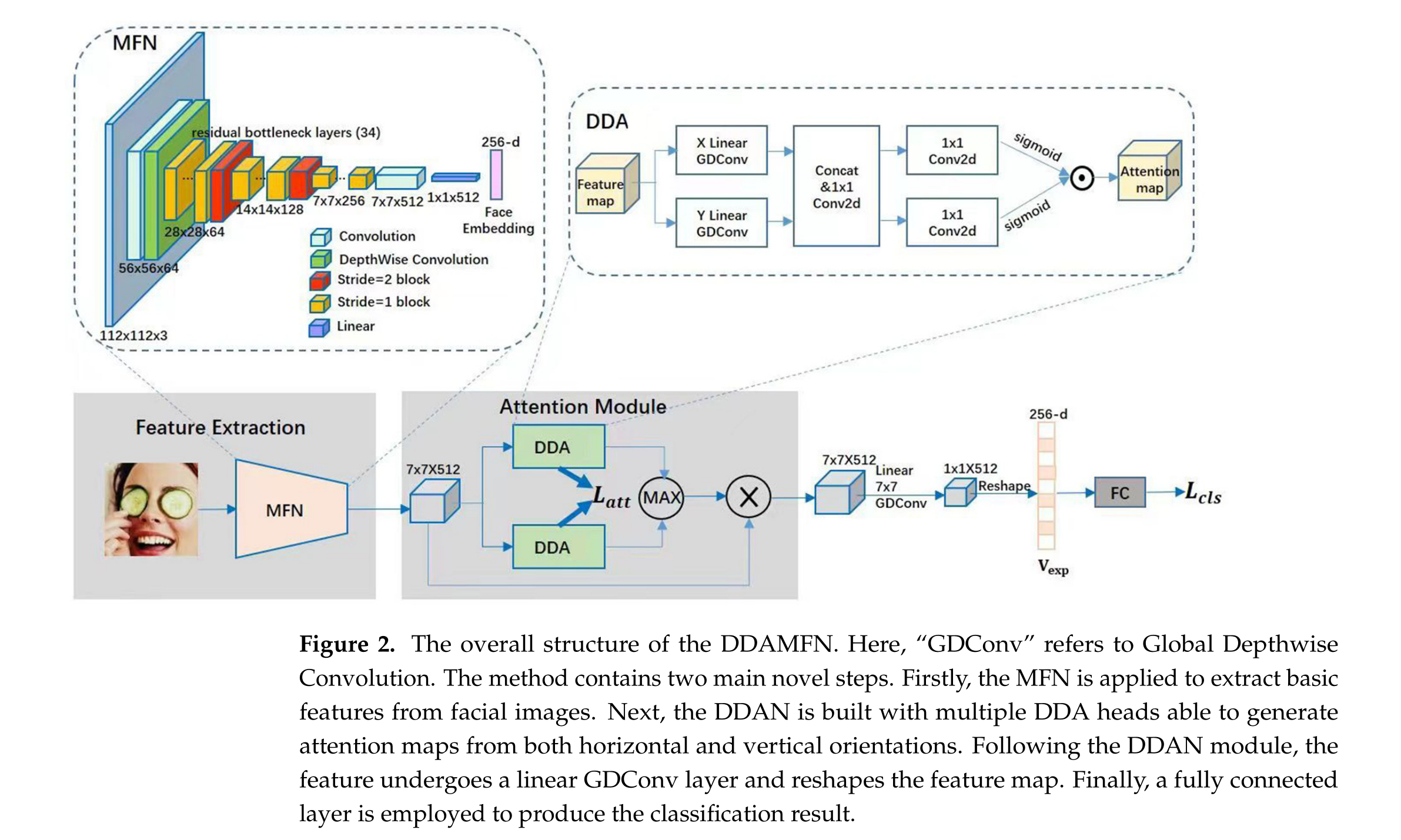
MFN结构:
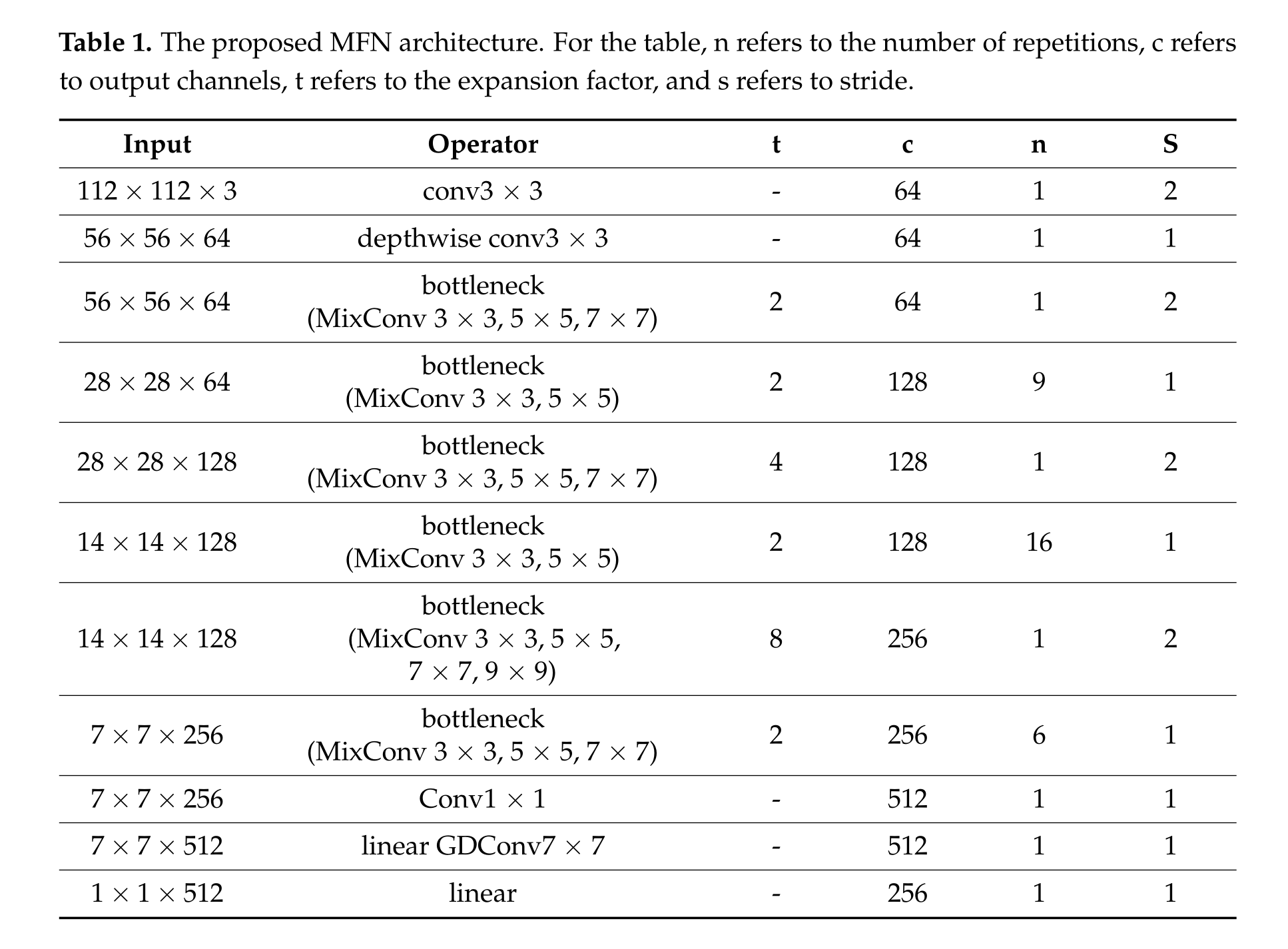
损失
如图2所示,从DDAN获得的大小为7×7×512的特征图经过线性GDConv层和线性层处理。然后,将转换后的特征图重新形状为一个512维的向量。通过全连接层获得类别置信度。在损失函数方面,训练过程中采用标准的交叉熵损失。该损失函数有效地衡量了预测类别概率与真实标签之间的差异,有助于优化模型的参数。整体损失函数可以表示为:
L = L_cls + λ_a * L_att,(3)
其中,L_cls代表标准交叉熵损失,L_att是注意力损失。λ_a是一个超参数,默认值为0.1。
指标比较
处理数据
在DDAMFN中,只有前8个类别是重要的。我将后面三个类别都归位负样本类别。
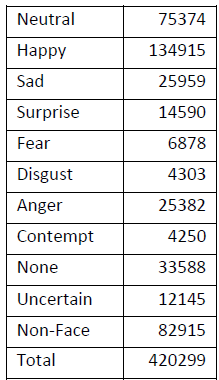
使用此代码处理数据,将原始数据集进行转换:
python展开代码import os
import shutil
import pandas as pd
from tqdm import tqdm
root = r"/ssd/xd/src_data/Manually_Annotated_Images/"
# training.csv
training_csv = r"/ssd/xd/src_data/training.csv"
# validation.csv
validation_csv = r"/ssd/xd/src_data/validation.csv"
dst_train = r"/ssd/xd/src_data/new_datasets_ImageFolder/train"
os.makedirs(dst_train, exist_ok=True)
dst_val = r"/ssd/xd/src_data/new_datasets_ImageFolder/val"
os.makedirs(dst_val, exist_ok=True)
# subDirectory_filePath列是图片的路径,expression列是标签
# 用标签创建子文件夹,然后对应图片移动到对应文件夹
df_train = pd.read_csv(training_csv)
df_train = df_train[["subDirectory_filePath", "expression"]]
for i in tqdm(range(len(df_train))):
img_path = os.path.join(root, df_train.iloc[i, 0])
label = df_train.iloc[i, 1]
dst = os.path.join(dst_train, str(label))
os.makedirs(dst, exist_ok=True)
if os.path.exists(img_path):
shutil.copy(img_path, dst)
df_val = pd.read_csv(validation_csv)
df_val = df_val[["subDirectory_filePath", "expression"]]
for i in tqdm(range(len(df_val))):
img_path = os.path.join(root, df_val.iloc[i, 0])
label = df_val.iloc[i, 1]
dst = os.path.join(dst_val, str(label))
os.makedirs(dst, exist_ok=True)
if os.path.exists(img_path):
shutil.copy(img_path, dst)
# 0到7的类别标签保留,其余的都转为一个标签8
dst_train_8 = r"/ssd/xd/src_data/new_datasets_ImageFolder/train/8"
dst_train_9 = r"/ssd/xd/src_data/new_datasets_ImageFolder/train/9"
dst_train_10 = r"/ssd/xd/src_data/new_datasets_ImageFolder/train/10"
# 将9和10类别的图片移动到8类别文件夹,然后删除9和10文件夹
files_9 = os.listdir(dst_train_9)
files_10 = os.listdir(dst_train_10)
for file in files_9:
shutil.move(os.path.join(dst_train_9, file), os.path.join(dst_train_8, file))
for file in files_10:
shutil.move(os.path.join(dst_train_10, file), os.path.join(dst_train_8, file))
shutil.rmtree(dst_train_9)
shutil.rmtree(dst_train_10)
dst_val_8 = r"/ssd/xd/src_data/new_datasets_ImageFolder/val/8"
dst_val_9 = r"/ssd/xd/src_data/new_datasets_ImageFolder/val/9"
dst_val_10 = r"/ssd/xd/src_data/new_datasets_ImageFolder/val/10"
# 将9和10类别的图片移动到8类别文件夹,然后删除9和10文件夹
files_9 = os.listdir(dst_val_9)
files_10 = os.listdir(dst_val_10)
for file in files_9:
shutil.move(os.path.join(dst_val_9, file), os.path.join(dst_val_8, file))
for file in files_10:
shutil.move(os.path.join(dst_val_10, file), os.path.join(dst_val_8, file))
shutil.rmtree(dst_val_9)
shutil.rmtree(dst_val_10)
得到:
文件夹 0 中的文件数量为: 74874
文件夹 1 中的文件数量为: 134415
文件夹 2 中的文件数量为: 25459
文件夹 3 中的文件数量为: 14090
文件夹 4 中的文件数量为: 6378
文件夹 5 中的文件数量为: 3803
文件夹 6 中的文件数量为: 24882
文件夹 7 中的文件数量为: 3750
文件夹 8 中的文件数量为: 127148
文件夹 0 中的文件数量为: 500
文件夹 1 中的文件数量为: 500
文件夹 2 中的文件数量为: 500
文件夹 3 中的文件数量为: 500
文件夹 4 中的文件数量为: 500
文件夹 5 中的文件数量为: 500
文件夹 6 中的文件数量为: 500
文件夹 7 中的文件数量为: 500
文件夹 8 中的文件数量为: 1500
下载代码训练
https://github.com/simon20010923/DDAMFN/tree/main

效果
垂直领域模型比通用分类模型强多了,这3轮直接干到道心破碎:
(py310_torch) Tue Mar 19 # 15:54:01 # /ssd/src_data/eff_train/DDAMFN-main # python affectnet_train.py
Whole train set size: 414798
Validation set size: 5500
[Epoch 1] Training accuracy: 0.4141. Loss: 3.846. LR 0.000100
[Epoch 1] Validation accuracy:0.4827. Loss:7.671
best_acc:0.4827
Model saved.
[Epoch 2] Training accuracy: 0.5221. Loss: 2.075. LR 0.000060
[Epoch 2] Validation accuracy:0.5035. Loss:5.648
best_acc:0.5035
Model saved.
[Epoch 3] Training accuracy: 0.5471. Loss: 1.810. LR 0.000036
[Epoch 3] Validation accuracy:0.5105. Loss:4.621
best_acc:0.5105
Model saved.
[Epoch 4] Training accuracy: 0.5606. Loss: 1.685. LR 0.000022
[Epoch 4] Validation accuracy:0.5198. Loss:3.784
best_acc:0.5198
Model saved.
[Epoch 5] Training accuracy: 0.5674. Loss: 1.618. LR 0.000013
[Epoch 5] Validation accuracy:0.5220. Loss:3.048
best_acc:0.522
Model saved.
12%|██████████████▌
最后结果:
[Epoch 38] Training accuracy: 0.5799. Loss: 1.502. LR 0.000000
[Epoch 38] Validation accuracy:0.5225. Loss:2.505
best_acc:0.5245
Model saved.
[Epoch 39] Training accuracy: 0.5784. Loss: 1.505. LR 0.000000
[Epoch 39] Validation accuracy:0.5235. Loss:2.513
best_acc:0.5245
Model saved.
[Epoch 40] Training accuracy: 0.5799. Loss: 1.504. LR 0.000000
[Epoch 40] Validation accuracy:0.5215. Loss:2.496
best_acc:0.5245
Model saved.
试试8个类别的训练
8个类别表情少了一些数据干扰,结果好多了:
训练结果:
Model saved.
[Epoch 33] Training accuracy: 0.5960. Loss: 1.590. LR 0.000000
[Epoch 33] Validation accuracy:0.6235. Loss:2.621
best_acc:0.6265
Model saved.
[Epoch 34] Training accuracy: 0.5939. Loss: 1.596. LR 0.000000
[Epoch 34] Validation accuracy:0.6258. Loss:2.589
best_acc:0.6265
Model saved.
[Epoch 35] Training accuracy: 0.5967. Loss: 1.593. LR 0.000000
[Epoch 35] Validation accuracy:0.6263. Loss:2.558
best_acc:0.6265
Model saved.
[Epoch 36] Training accuracy: 0.5963. Loss: 1.593. LR 0.000000
[Epoch 36] Validation accuracy:0.6263. Loss:2.578
best_acc:0.6265
Model saved.
[Epoch 37] Training accuracy: 0.5951. Loss: 1.593. LR 0.000000
[Epoch 37] Validation accuracy:0.6252. Loss:2.576
best_acc:0.6265
Model saved.
[Epoch 38] Training accuracy: 0.5960. Loss: 1.591. LR 0.000000
[Epoch 38] Validation accuracy:0.6272. Loss:2.607
best_acc:0.6272
Model saved.
[Epoch 39] Training accuracy: 0.5957. Loss: 1.592. LR 0.000000
[Epoch 39] Validation accuracy:0.6255. Loss:2.612
best_acc:0.6272
Model saved.
[Epoch 40] Training accuracy: 0.5969. Loss: 1.592. LR 0.000000
[Epoch 40] Validation accuracy:0.6235. Loss:2.588
best_acc:0.6272
Model saved.
100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████| 40/40 [3:58:59<00:00, 358.48s/it]
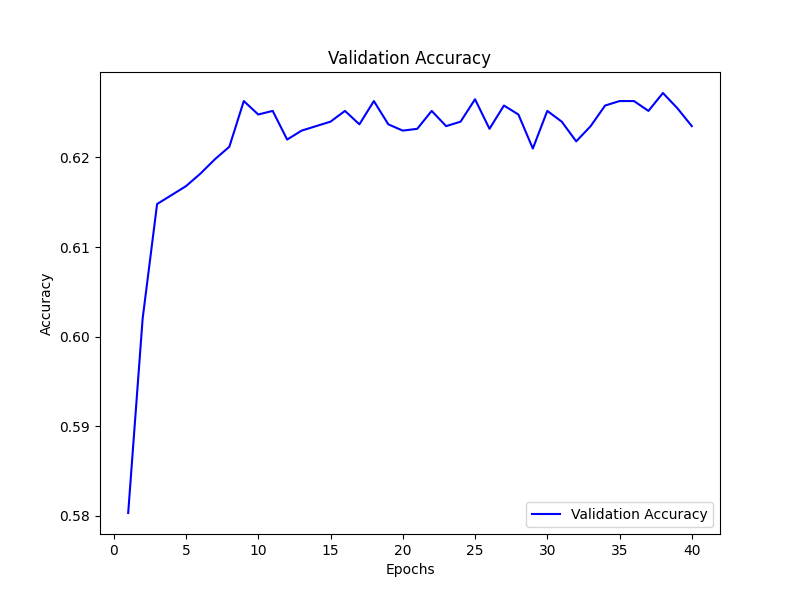
8类验证精度
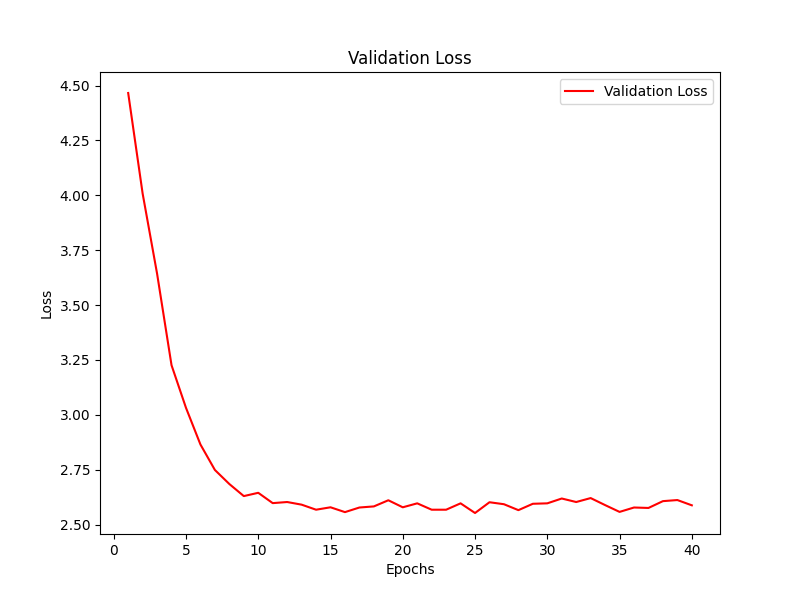
8类训练损失变化
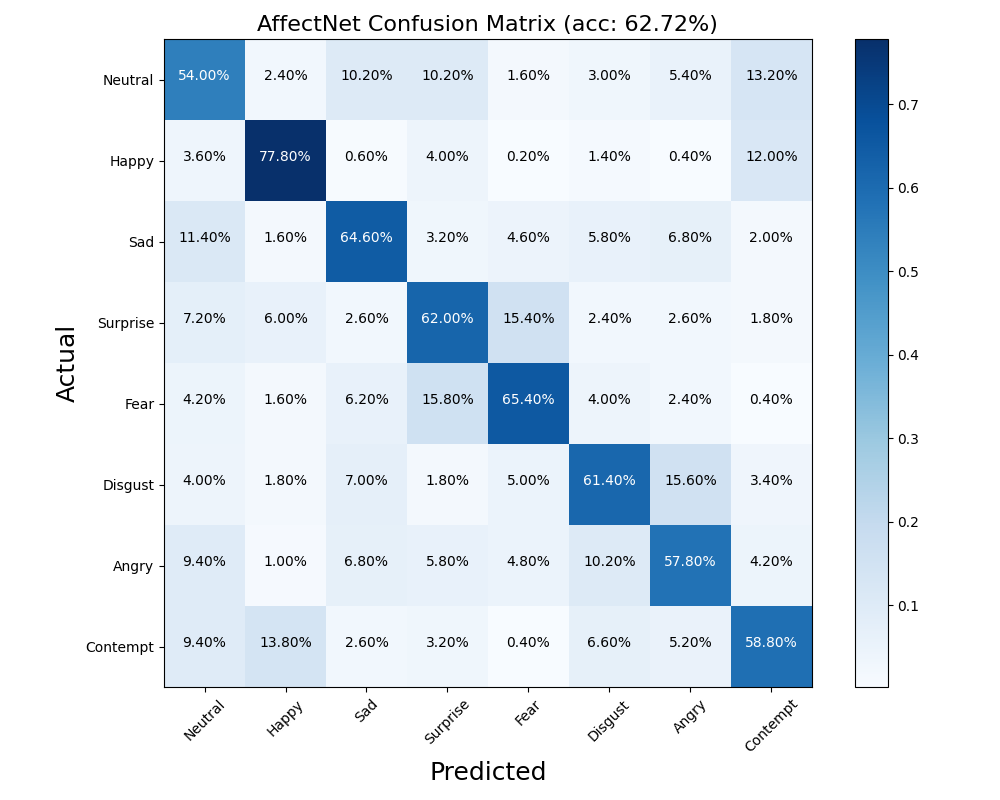
8类混淆矩阵
混淆矩阵很容易看出,本身是某个类别的数据,被误判为哪个类别去了,可以看出某两个类别容易混淆。
推理测试
推理这张图:

a100显卡CUDA推理:
用时0.029578685760498047秒
Class Neutral: 0.0000
Class Happy: 0.0001
Class Sad: 0.0000
Class Surprise: 0.0008
Class Fear: 0.0125
Class Disgust: 0.0001
Class Angry: 0.9865
Class Contempt: 0.0000
转onnx模型
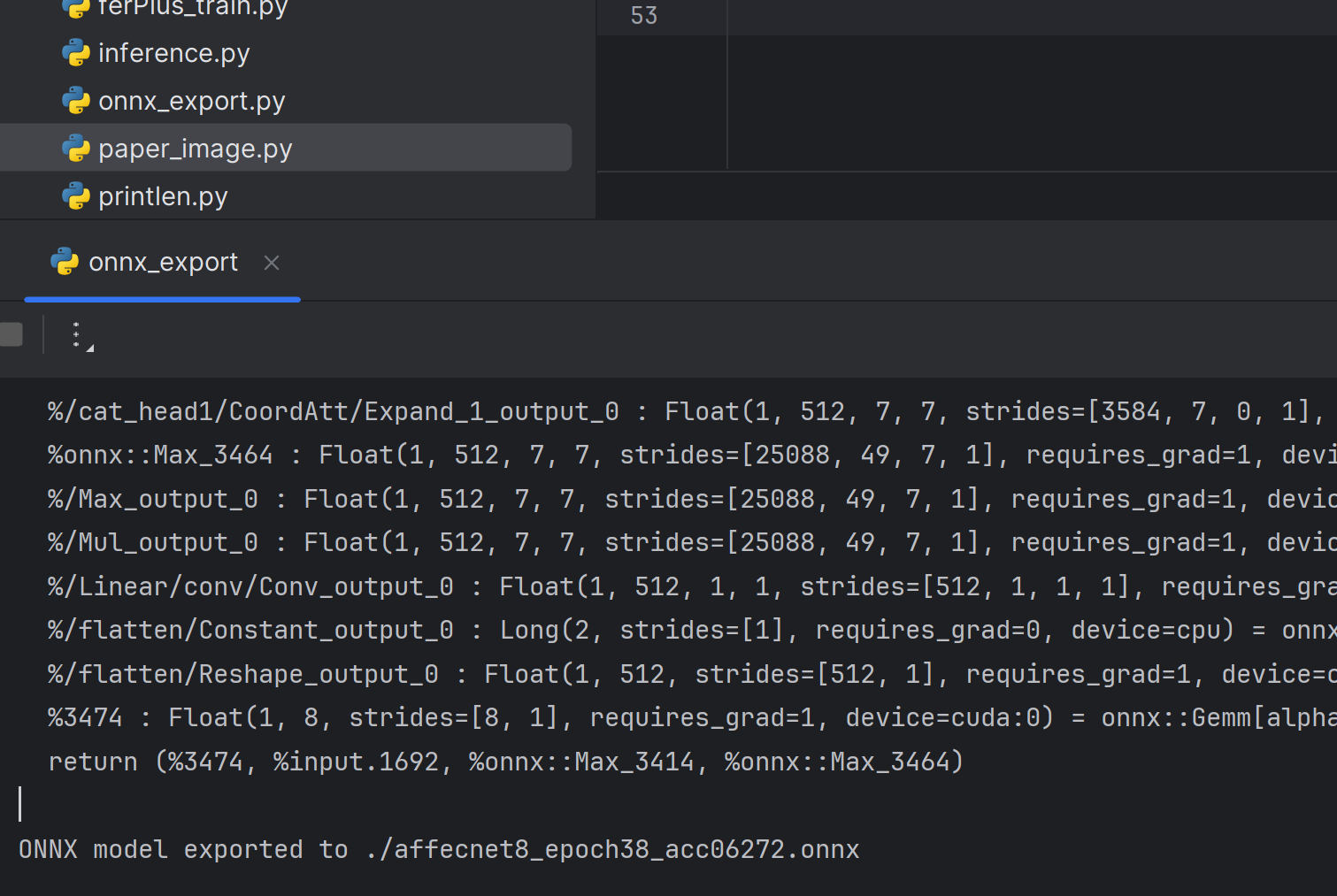
cpp展开代码 # Define input example
dummy_input = torch.randn(1, 3, 112, 112, device=device)
# Perform inference to capture dynamic computation graph
with torch.no_grad():
output, _, _ = model(dummy_input)
# Export the model to ONNX
torch.onnx.export(model, dummy_input, args.output_path, verbose=True,opset_version=10)
print(f"ONNX model exported to {args.output_path}")
onnx推理
cpp展开代码def inference(args):
# Load ONNX model
ort_session = onnxruntime.InferenceSession(args.onnx_model_path)
time1 = time.time()
# Preprocess input image
image_transform = transforms.Compose([
transforms.Resize((112, 112)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
])
image = Image.open(args.image_path).convert('RGB')
image_tensor = image_transform(image).unsqueeze(0).numpy()
# Perform inference
ort_inputs = {ort_session.get_inputs()[0].name: image_tensor}
ort_outs = ort_session.run(None, ort_inputs)
logits = np.squeeze(ort_outs[0])
# Apply softmax
probabilities = np.exp(logits) / np.sum(np.exp(logits), axis=0)
time2 = time.time()
print(f"Inference time: {time2 - time1} seconds")
return probabilities
Inference time: 0.08892297744750977 seconds
Class Neutral: 0.0000
Class Happy: 0.0001
Class Sad: 0.0000
Class Surprise: 0.0008
Class Fear: 0.0125
Class Disgust: 0.0001
Class Angry: 0.9865
Class Contempt: 0.0000
结合一些别的项目
本文的分类器只是针对方形图像进行分类的,所以一些日常图片要进行人脸检测,可以参看项目:
https://github.com/derronqi/yolov8-face
https://github.com/hpc203/yolov8-face-landmarks-opencv-dnn/tree/main
跑完后的一些图鉴






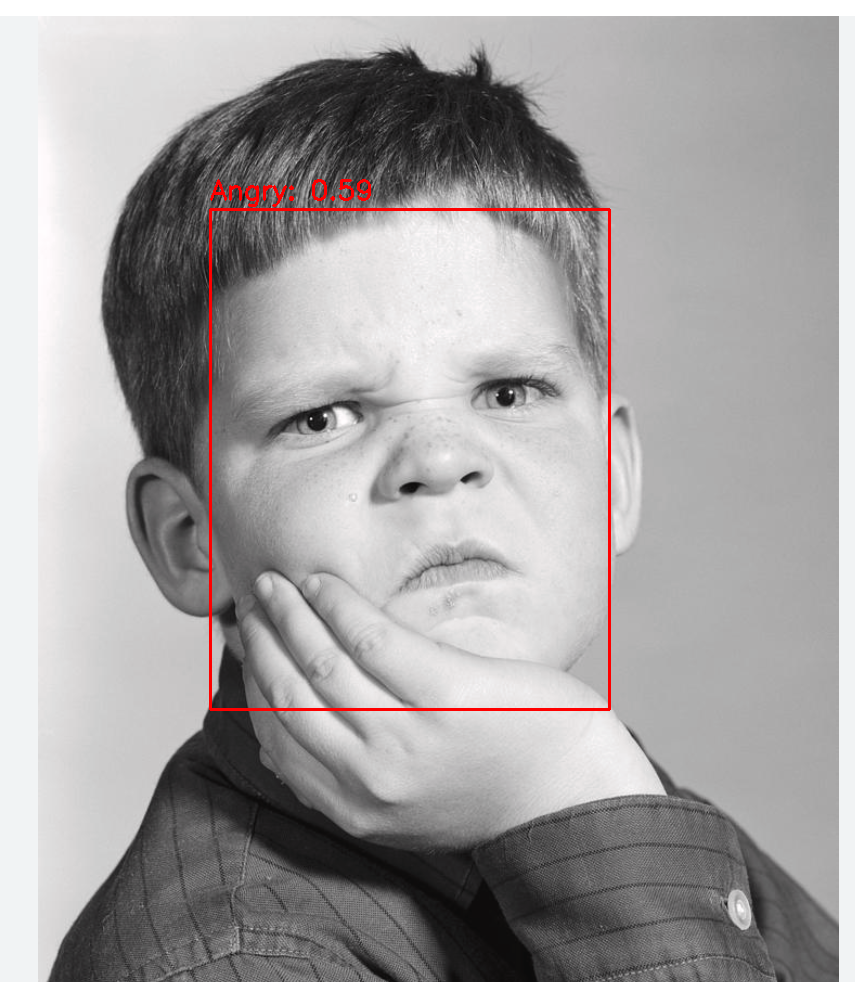

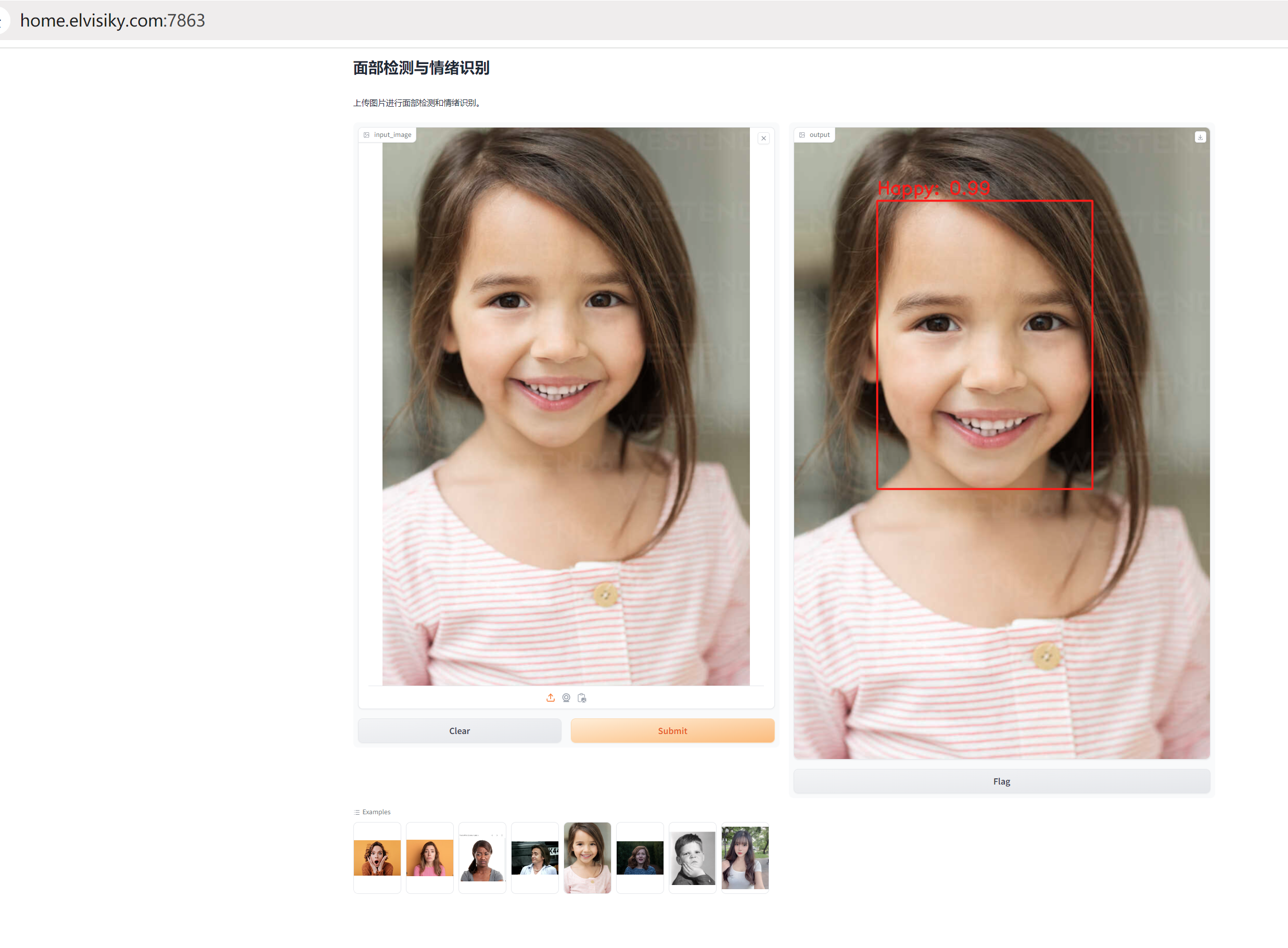
做个gradio的web app
用gradio做了个页面,可以上传图片后,对图片进行人脸检测,然后进行人脸推理,效果如下:
代码、训练、权重、帮助
如果想获取帮助:
bash展开代码https://docs.qq.com/sheet/DUEdqZ2lmbmR6UVdU?tab=BB08J2


本文作者:Dong
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 CC BY-NC。本作品采用《知识共享署名-非商业性使用 4.0 国际许可协议》进行许可。您可以在非商业用途下自由转载和修改,但必须注明出处并提供原作者链接。 许可协议。转载请注明出处!