目录
优化算法服务:从单进程到并行化
在实际应用中,单个算法服务的并发能力可能无法满足需求。为了提高性能和并发处理能力,我们可以使用Gunicorn和Docker来实现算法服务的并行化部署。
单个服务架构
首先,让我们来看看单个服务的架构:
python展开代码from fastapi import FastAPI
app = FastAPI()
alg_model = xxxx() # Initialize your algorithm model
@app.post("/alginfer")
def alginfer(xxxx):
# Perform inference using alg_model
result = alg_model.predict(xxxx)
return result
在这个架构下,服务拓扑图如下:
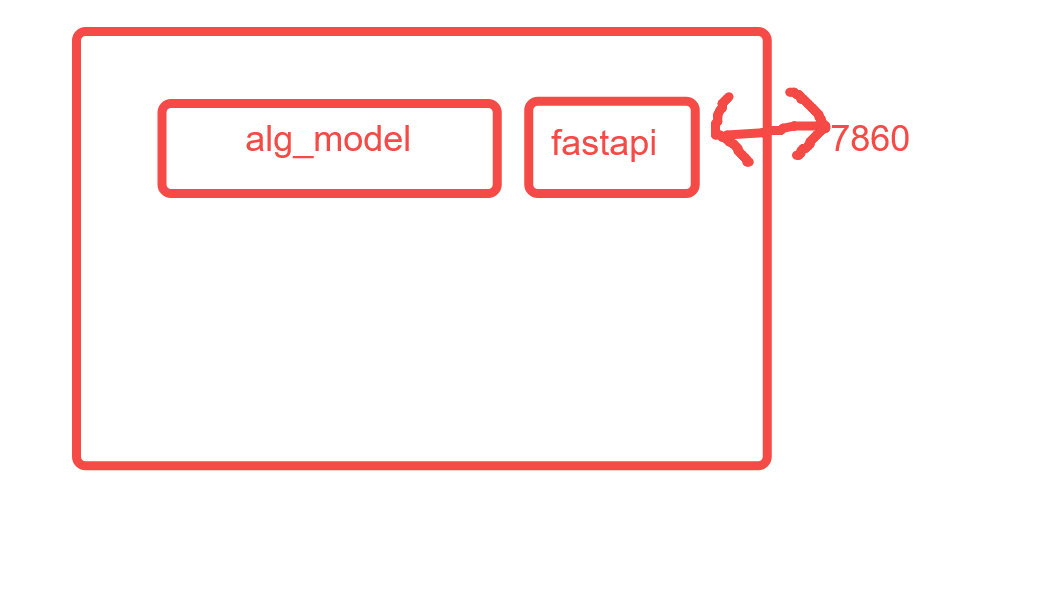
多并行服务架构
为了提高服务并发能力,我们可以使用Gunicorn来启动多个并行的算法服务。以下是如何使用Gunicorn进行多并行服务的部署:
bash展开代码pip install gunicorn
bash展开代码gunicorn -w 2 -b 0.0.0.0:7860 -k uvicorn.workers.UvicornWorker sdxl_app:app
在这个架构下,服务拓扑图变为:
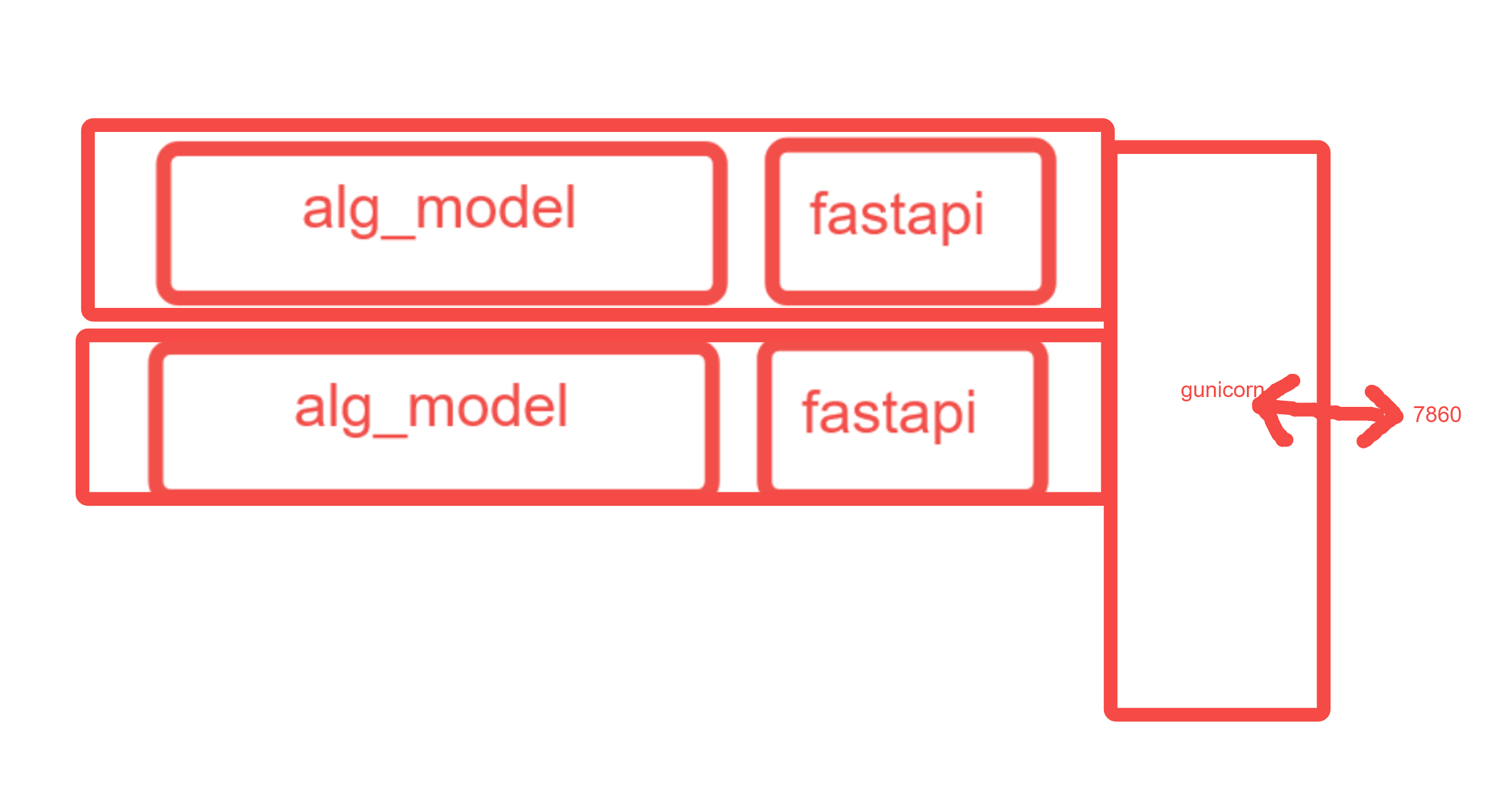
Docker化并指定并行服务数量
通过Docker容器化算法服务,并通过环境变量来指定并行服务的数量,可以进一步简化部署和管理。以下是实现这一目标的步骤:
首先,创建一个gunicorn_config.py文件:
python展开代码import os
bind = '0.0.0.0:7860' # Listen address and port
workers = int(os.environ.get('GUNICORN_WORKERS', '1')) # Number of workers
worker_class = 'uvicorn.workers.UvicornWorker' # Worker type
然后,编写Dockerfile:
Dockerfile展开代码FROM kevinchina/xxxx:xxxx EXPOSE 7860 ENTRYPOINT gunicorn -c /workspace/gunicorn_config.py sdxl_app:app
最后,通过docker run命令启动容器,并指定环境变量来设置并行服务的数量:
bash展开代码docker run -e GUNICORN_WORKERS=2 -p 7860:7860 -d --gpus all kevinchina/xxxx:tttt
通过这些优化,我们可以轻松地实现算法服务的并行化部署,提高系统的性能和可伸缩性。
扩展知识
当你使用 Gunicorn 启动服务时,-k 参数用于指定使用的 worker 类型。不同的 worker 类型适用于不同的场景和需求。以下是一些常见的 worker 类型以及它们的用途:
-
sync:同步 worker,每个请求都会在一个独立的线程或进程中处理。适用于开发环境或者对并发要求不高的场景。 -
eventlet:基于事件驱动的并发库,可以实现高并发。适用于 I/O 密集型的应用程序。 -
gevent:基于 libev 的并发库,也是事件驱动的。与 eventlet 类似,适用于 I/O 密集型的应用程序。 -
uvicorn.workers.UvicornWorker:使用 Uvicorn worker,适用于 ASGI 应用程序。
你可以根据你的应用程序类型和需求选择合适的 worker 类型。例如,如果你的应用程序是基于 ASGI 的,你可以使用 Uvicorn worker。以下是一个使用 -k 参数指定 worker 类型的示例:
bash展开代码gunicorn -w 4 -b 0.0.0.0:7860 -k uvicorn.workers.UvicornWorker sdxl_app:app
在这个示例中:
-
-w 4指定了 4 个 worker 进程。 -
-b 0.0.0.0:7860指定了绑定的主机和端口。 -
-k uvicorn.workers.UvicornWorker指定了使用 Uvicorn worker。
根据你的实际情况选择适合的 worker 类型,并根据需要调整其他参数。


本文作者:Dong
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 CC BY-NC。本作品采用《知识共享署名-非商业性使用 4.0 国际许可协议》进行许可。您可以在非商业用途下自由转载和修改,但必须注明出处并提供原作者链接。 许可协议。转载请注明出处!