目录
https://arxiv.org/abs/2410.13863
摘要
论文研究了文本生成图像背景下的缩放问题,主要关注两个关键因素:模型使用离散还是连续的标记,以及标记是以随机顺序还是固定光栅顺序生成,使用的是类似于BERT还是GPT的转换器架构。
基于连续标记的模型相比于使用离散标记的模型,在视觉质量上显著更佳。
此外,生成顺序和注意力机制显著影响GenEval分数:随机顺序模型相比于光栅顺序模型获得了显著更好的GenEval分数。
受这些发现的启发,我们训练了Fluid,一个基于连续标记的随机顺序自回归模型。
Fluid 10.5B模型在MS-COCO 30K数据集上实现了新的零样本FID的最先进成绩6.16,并在GenEval基准测试中获得了0.69的总分。
我们希望我们的发现和结果能够鼓励未来的研究工作进一步弥合视觉和语言模型之间的扩展差距。
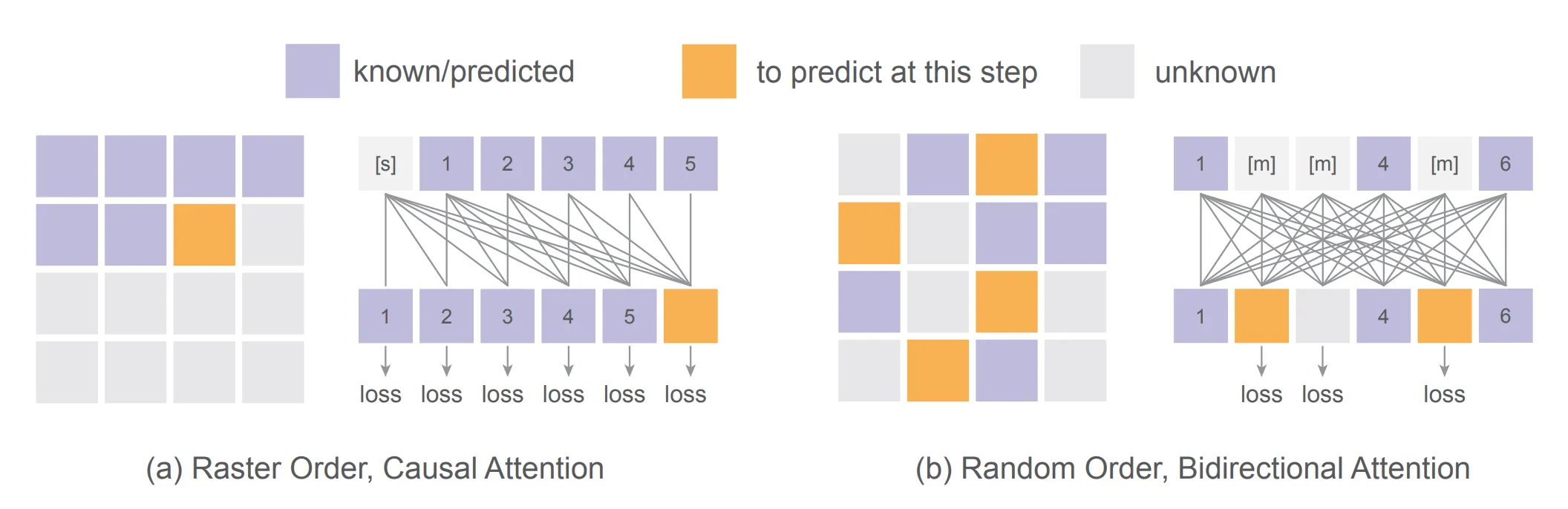
不同顺序的自回归模型
不同顺序的自回归模型。(a) 栅格顺序自回归模型基于已知的标记预测下一个标记,使用具有因果注意力机制的类似 GPT 的 Transformer 实现。(b) 随机顺序自回归模型在给定随机顺序的情况下同时预测一个或多个标记,使用具有双向注意力机制的类似 BERT 的 Transformer 实现。
Fluid 模型架构
架构如下:
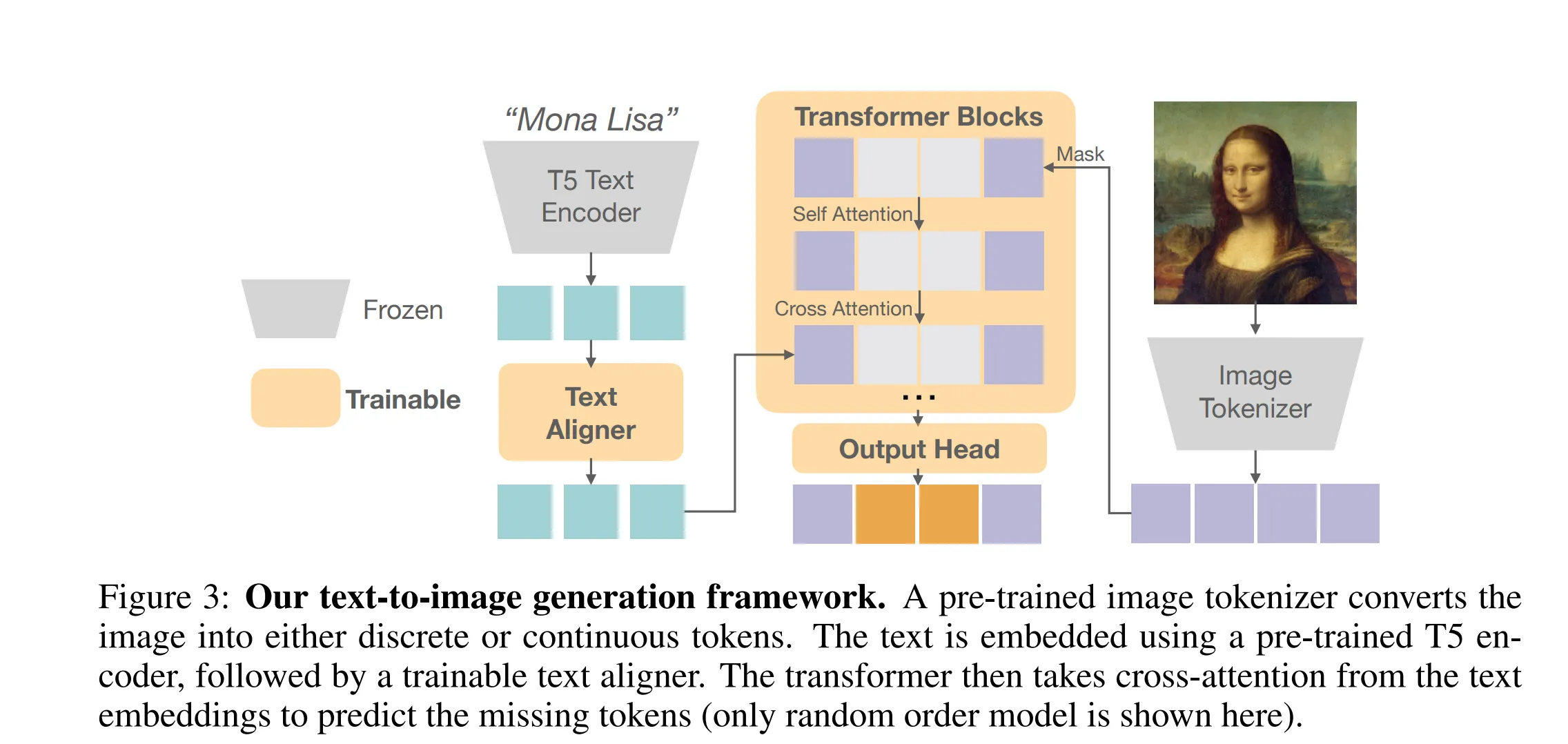

组件介绍:
图像标记器。我们使用预训练的图像标记器将256×256图像编码到一个标记空间中。这个标记器可以是离散的或连续的,以便于自回归模型的不同训练目标。在我们的实验中,离散标记器是一个VQGAN模型(Esser等,2021),它在WebLI数据集(Chen等,2022)上进行了预训练。我们遵循Muse(Chang等,2023)的做法,将每张图像编码为16×16的离散令牌,词汇大小为8192。对于连续标记器,我们采用了来自Stable Diffusion(Rombach等,2022b)的广泛使用的模型,该模型将图像编码为32×32的连续令牌,每个令牌包含4个通道。为了在序列长度上与离散标记器保持一致,我们进一步将每个2×2的连续令牌块分组为一个单一的令牌,最终序列长度为256,每个令牌包含16个通道。如图4所示,连续标记器可以比离散标记器实现显著更高的重建质量。
文本编码器。原始文本(最大长度为128)通过SentencePiece(Kudo,2018)进行标记化,并通过预训练的T5-XXL编码器(Raffel等,2020)嵌入,该编码器拥有47亿参数,并且在训练期间被冻结。为了进一步对齐图像生成的文本嵌入,我们在T5嵌入之上添加了一个由六个可训练的Transformer块组成的小型文本对齐器,以提取最终的文本表示。
Transformer。在将原始图像编码为令牌序列后,我们使用标准的仅解码器Transformer模型(Vaswani等,2017)进行自回归生成。每个块由三个连续层组成——自注意力、交叉注意力和MLP层。自注意力和MLP层仅应用于视觉令牌,而交叉注意力层则分别将视觉和文本令牌作为查询和关键。如图2所示,对于光栅顺序模型,Transformer使用因果注意力机制在自注意力块中基于前面的令牌预测下一个令牌,类似GPT。在随机顺序模型中,未知的令牌由可学习标记掩盖,Transformer使用双向注意力机制预测这些被掩盖的令牌,类似BERT。
输出头。对于离散令牌,我们遵循自回归模型的常见做法。输出通过线性层后的softmax转换为分类分布,其权重从输入嵌入层重新使用。对于连续令牌,我们应用六层轻量级MLP作为扩散头(Li等,2024)来建模每个令牌的分布。该头的嵌入维度与骨干Transformer相同。每个令牌的扩散过程遵循(Nichol & Dhariwal,2021;Li等,2024)。噪声计划呈余弦形状,在训练时有1000步;在推理时,它被重新采样为100步。
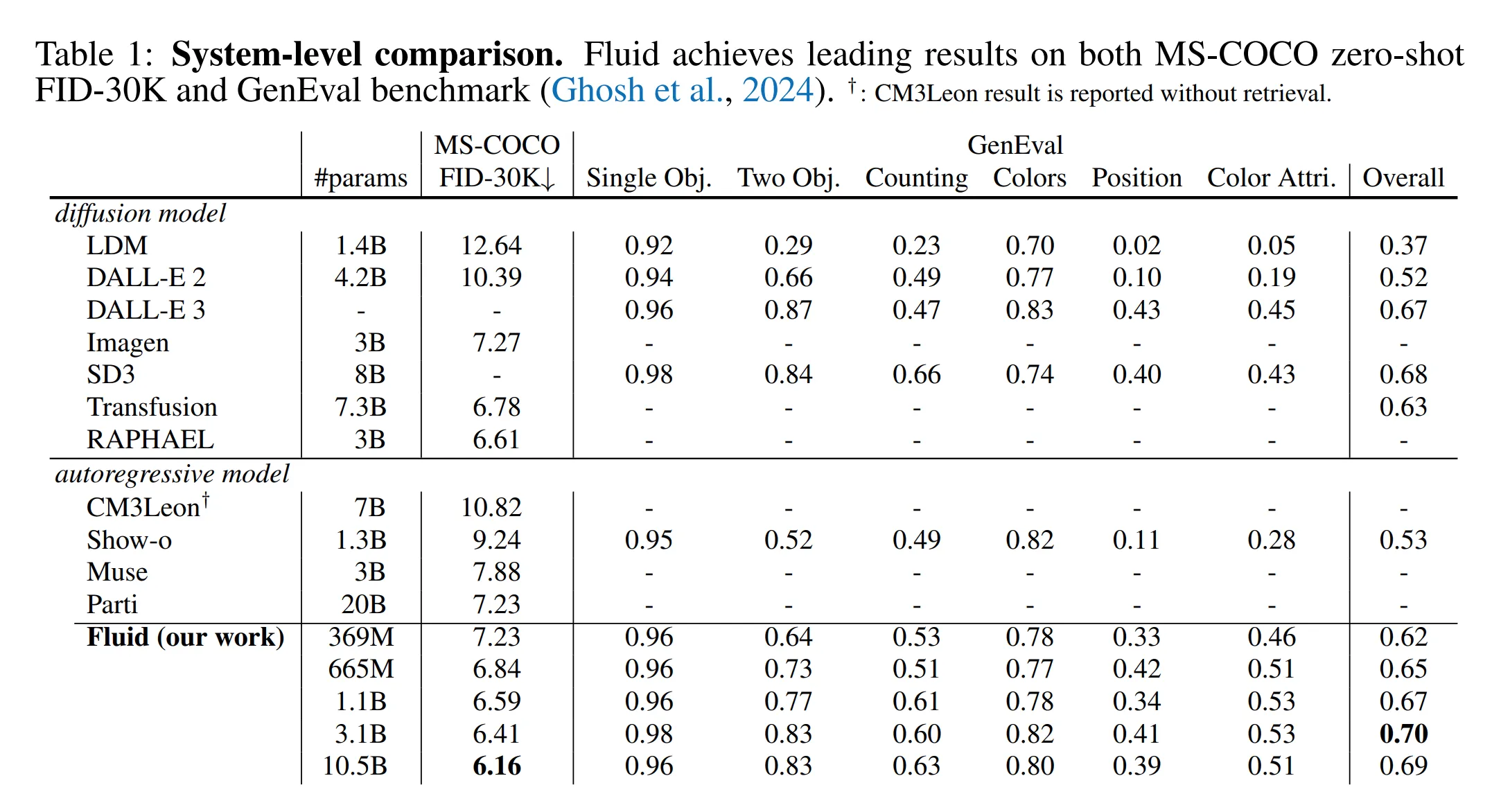
结果对比
栅格顺序模型(raster-order models)+ 离散标记(discrete tokens):在 10 亿参数(1B)左右,FID 和 GenEval 分数达到性能瓶颈(plateau)。
随机顺序模型(random-order models)+ 连续标记(continuous tokens)(即 Fluid 模型):FID 和 GenEval 分数在参数规模增加到 30 亿(3B)时持续改进,展现了最佳性能。


本文作者:Dong
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 CC BY-NC。本作品采用《知识共享署名-非商业性使用 4.0 国际许可协议》进行许可。您可以在非商业用途下自由转载和修改,但必须注明出处并提供原作者链接。 许可协议。转载请注明出处!