目录
管理 Schema
本主题介绍了Milvus中的Schema。Schema用于定义集合及其中字段的属性。
字段 Schema
字段 Schema 是字段的逻辑定义。在定义集合 Schema 和管理集合之前,需要首先定义字段 Schema。
Milvus 在一个集合中仅支持一个主键字段。
字段 Schema 属性
| 属性 | 描述 | 备注 |
|---|---|---|
name | 集合中字段的名称 | 数据类型:字符串。必填项 |
dtype | 字段的数据类型 | 必填项 |
description | 字段的描述 | 数据类型:字符串。可选项 |
is_primary | 是否设置字段为主键字段 | 数据类型:布尔值(true 或 false)。主键字段必填 |
auto_id (主键字段必填) | 启用或禁用自动分配 ID(主键) | True 或 False |
max_length (VARCHAR字段必填) | 插入字符串的最大字节长度,注意多字节字符(如Unicode字符)可能占用多个字节,需要确保插入的字符串字节长度不超过指定的限制 | [1, 65,535] |
dim | 向量的维度 | 数据类型:整数 ∈[1, 32768]。密集向量字段必填,稀疏向量字段不需要填写 |
is_partition_key | 是否为分区键字段 | 数据类型:布尔值(true 或 false)。 |
创建字段 Schema
为简化数据插入,Milvus 允许在创建字段 Schema 时为每个标量字段指定默认值(不包括主键字段)。这意味着如果在插入数据时留空字段,将使用为该字段指定的默认值。
创建常规字段 Schema:
python展开代码from pymilvus import FieldSchema
id_field = FieldSchema(name="id", dtype=DataType.INT64, is_primary=True, description="primary id")
age_field = FieldSchema(name="age", dtype=DataType.INT64, description="age")
embedding_field = FieldSchema(name="embedding", dtype=DataType.FLOAT_VECTOR, dim=128, description="vector")
# 以下创建字段并将其作为分区键
position_field = FieldSchema(name="position", dtype=DataType.VARCHAR, max_length=256, is_partition_key=True)
创建带默认值的字段 Schema:
python展开代码from pymilvus import FieldSchema
fields = [
FieldSchema(name="id", dtype=DataType.INT64, is_primary=True),
# 为字段 `age` 配置默认值 `25`
FieldSchema(name="age", dtype=DataType.INT64, default_value=25, description="age"),
embedding_field = FieldSchema(name="embedding", dtype=DataType.FLOAT_VECTOR, dim=128, description="vector")
]
支持的数据类型
DataType 定义了字段包含的数据类型。不同的字段支持不同的数据类型。
主键字段支持:
- INT64: numpy.int64
- VARCHAR: VARCHAR
标量字段支持:
- BOOL: 布尔值(true 或 false)
- INT8: numpy.int8
- INT16: numpy.int16
- INT32: numpy.int32
- INT64: numpy.int64
- FLOAT: numpy.float32
- DOUBLE: numpy.double
- VARCHAR: VARCHAR
- JSON: JSON
- Array: 数组
JSON作为复合数据类型可用。JSON字段由键值对组成,每个键是字符串,值可以是数字、字符串、布尔值、数组或列表。详细信息请参见JSON: 新数据类型。
向量字段支持:
- BINARY_VECTOR: 存储二进制数据作为一系列0和1,通常用于图像处理和信息检索中的紧凑特征表示。
- FLOAT_VECTOR: 存储32位浮动点数,通常用于科学计算和机器学习中表示实数。
- FLOAT16_VECTOR: 存储16位半精度浮动点数,常用于深度学习和GPU计算,以提高内存和带宽效率。
- BFLOAT16_VECTOR: 存储16位浮动点数,精度较低,但指数范围与Float32相同,深度学习中常用于减少内存和计算要求,同时不显著影响精度。
- SPARSE_FLOAT_VECTOR: 存储非零元素及其对应的索引,用于表示稀疏向量。更多信息请参见稀疏向量。
Milvus支持集合中的多个向量字段。有关更多信息,请参见混合搜索。
集合 Schema
集合 Schema 是集合的逻辑定义。通常需要先定义字段 Schema,然后再定义集合 Schema 和管理集合。
集合 Schema 属性
| 属性 | 描述 | 备注 |
|---|---|---|
field | 要创建的集合中的字段 | 必填项 |
description | 集合的描述 | 数据类型:字符串。可选项 |
partition_key_field | 作为分区键的字段名称 | 数据类型:字符串。可选项 |
enable_dynamic_field | 是否启用动态 Schema | 数据类型:布尔值(true 或 false)。可选项,默认值为 False。 |
创建集合 Schema
在定义集合 Schema 之前,先定义字段 Schema。
python展开代码from pymilvus import FieldSchema, CollectionSchema
id_field = FieldSchema(name="id", dtype=DataType.INT64, is_primary=True, description="primary id")
age_field = FieldSchema(name="age", dtype=DataType.INT64, description="age")
embedding_field = FieldSchema(name="embedding", dtype=DataType.FLOAT_VECTOR, dim=128, description="vector")
# 如果需要基于分区键字段实现多租户,启用分区键字段
position_field = FieldSchema(name="position", dtype=DataType.VARCHAR, max_length=256, is_partition_key=True)
# 如果需要使用动态字段,请将 enable_dynamic_field 设置为 True。
schema = CollectionSchema(fields=[id_field, age_field, embedding_field], auto_id=False, enable_dynamic_field=True, description="desc of a collection")
使用指定的 Schema 创建集合:
python展开代码from pymilvus import Collection, connections
conn = connections.connect(host="127.0.0.1", port=19530)
collection_name1 = "tutorial_1"
collection1 = Collection(name=collection_name1, schema=schema, using='default', shards_num=2)
你可以通过 shards_num 定义分片数量。
你可以通过指定 using 中的别名来定义 Milvus 服务器。
如果需要在字段上启用分区键功能,可以将字段的 is_partition_key 设置为 True。
如果需要启用动态 Schema,可以在集合 Schema 中将 enable_dynamic_field 设置为 True。
你还可以使用 Collection.construct_from_dataframe 从 DataFrame 自动生成集合 Schema 并创建集合:
python展开代码import pandas as pd
df = pd.DataFrame({
"id": [i for i in range(nb)],
"age": [random.randint(20, 40) for i in range(nb)],
"embedding": [[random.random() for _ in range(dim)] for _ in range(nb)],
"position": "test_pos"
})
collection, ins_res = Collection.construct_from_dataframe(
'my_collection',
df,
primary_field='id',
auto_id=False
)
主键字段与自动ID
主键字段用于唯一标识一个实体。本页介绍了如何添加两种不同数据类型的主键字段,以及如何启用Milvus自动分配主键值。
概述
在一个集合中,每个实体的主键应该是全局唯一的。当添加主键字段时,必须显式设置其数据类型为VARCHAR或INT64。将数据类型设置为INT64表示主键应为整数,例如12345;将数据类型设置为VARCHAR表示主键应为字符串,例如my_entity_1234。
您还可以启用AutoID,让Milvus自动分配主键给传入的实体。一旦启用了AutoID,插入数据时无需提供主键。
集合中的主键字段没有默认值,且不能为空。
使用 INT64 主键
若要使用INT64类型的主键,需将字段的数据类型设置为DataType.INT64并将is_primary设置为True。如果您还希望Milvus自动为传入的实体分配主键,则需要将auto_id设置为True。
python展开代码from pymilvus import MilvusClient, DataType
schema = MilvusClient.create_schema()
schema.add_field(
field_name="my_id",
datatype=DataType.INT64,
is_primary=True,
auto_id=True,
)
使用 VARCHAR 主键
若要使用VARCHAR类型的主键,除了将data_type参数设置为DataType.VARCHAR外,还需要为字段设置max_length参数。
python展开代码schema.add_field(
field_name="my_id",
datatype=DataType.VARCHAR,
is_primary=True,
auto_id=True,
max_length=512,
)
密集向量(Dense Vector)
密集向量是机器学习和数据分析中广泛使用的数值数据表示形式。它们由包含实数的数组组成,其中大多数或所有元素都是非零的。与稀疏向量相比,密集向量在相同的维度级别上包含更多信息,因为每个维度都包含有意义的值。这种表示方法能够有效地捕捉复杂的模式和关系,使数据在高维空间中更易于分析和处理。
应用场景
密集向量通常用于需要理解数据语义的场景,如语义搜索和推荐系统。在语义搜索中,密集向量帮助捕捉查询与文档之间的潜在关联,提高搜索结果的相关性;在推荐系统中,它们帮助识别用户与物品之间的相似性,提供更个性化的推荐。
概述
密集向量通常表示为一个具有固定长度的浮动点数数组,例如:[0.2, 0.7, 0.1, 0.8, 0.3, ..., 0.5]。这些向量的维度通常从几十到几百甚至几千不等,如128、256、768或1024。每个维度捕捉了对象的特定语义特征,使其通过相似性计算能够适用于各种场景。
2D 空间中的密集向量
尽管在现实应用中,密集向量的维度通常更高,2D示意图有效地传达了几个关键概念:
- 多维表示:每个点代表一个概念对象(如 Milvus、向量数据库、检索系统等),其位置由维度值决定。
- 语义关系:点之间的距离反映了概念之间的语义相似性。距离较近的点表示概念之间更为相关。
- 聚类效应:相关的概念(如 Milvus、向量数据库、检索系统)在空间中位置接近,形成语义集群。
以下是一个表示文本 "Milvus 是一个高效的向量数据库" 的实际密集向量示例:
展开代码[ -0.013052909, 0.020387933, -0.007869, -0.11111383, -0.030188112, -0.0053388323, 0.0010654867, 0.072027855, // ... 更多维度 ]
密集向量的生成
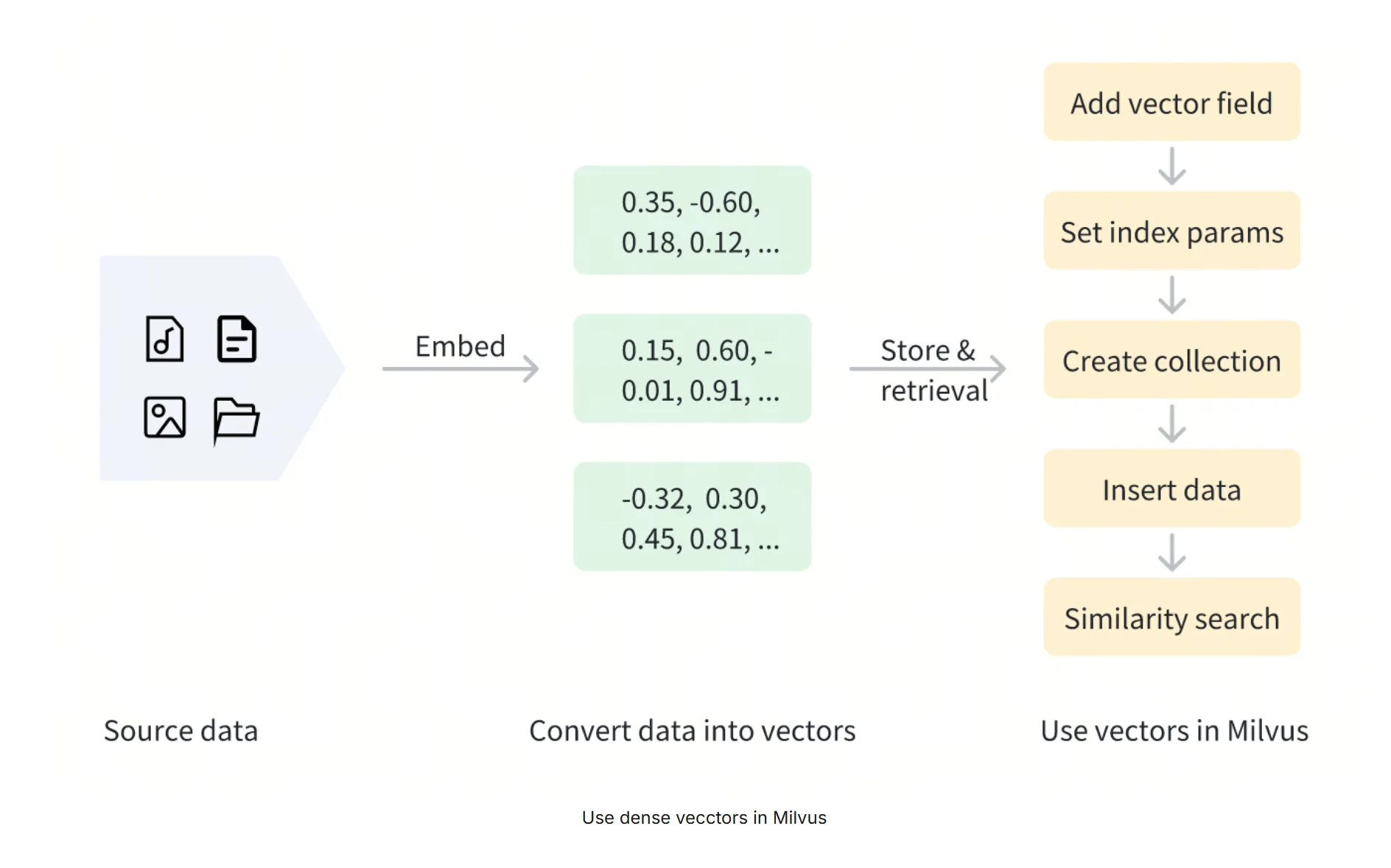
密集向量可以通过多种嵌入模型生成,如用于图像的CNN模型(如ResNet、VGG)和用于文本的语言模型(如BERT、Word2Vec)。这些模型将原始数据转化为高维空间中的点,捕捉数据的语义特征。此外,Milvus也提供了方便的方法来帮助用户生成和处理密集向量,如[嵌入功能]。
一旦数据向量化,就可以存储到Milvus中进行管理和向量检索。下图展示了基本的处理流程。
在Milvus中使用密集向量
除了密集向量,Milvus还支持稀疏向量和二进制向量。稀疏向量适用于基于特定词汇的精确匹配,如关键词搜索和术语匹配;而二进制向量常用于高效处理二值化数据,如图像模式匹配和某些哈希应用。
添加向量字段
要在Milvus中使用密集向量,首先需要在创建集合时定义一个向量字段来存储密集向量。此过程包括:
- 将数据类型设置为支持的密集向量数据类型(参见数据类型)。
- 使用
dim参数指定密集向量的维度。
以下是一个示例,展示如何添加名为dense_vector的向量字段以存储密集向量,数据类型为FLOAT_VECTOR,维度为4。
python展开代码from pymilvus import MilvusClient, DataType
client = MilvusClient(uri="http://localhost:19530")
schema = client.create_schema(
auto_id=True,
enable_dynamic_fields=True,
)
schema.add_field(field_name="pk", datatype=DataType.VARCHAR, is_primary=True, max_length=100)
schema.add_field(field_name="dense_vector", datatype=DataType.FLOAT_VECTOR, dim=4)
支持的密集向量数据类型:
| 类型 | 描述 |
|---|---|
FLOAT_VECTOR | 存储32位浮动点数,通常用于表示科学计算和机器学习中的实数。适用于需要高精度的场景,如区分相似向量。 |
FLOAT16_VECTOR | 存储16位半精度浮动点数,通常用于深度学习和GPU计算。在精度要求不高的场景(如推荐系统的低精度召回阶段)中,节省存储空间。 |
BFLOAT16_VECTOR | 存储16位Brain浮动点数(bfloat16),具有与Float32相同的指数范围,但精度降低。适用于需要快速处理大量向量的场景,如大规模图像检索。 |
设置向量字段的索引参数
为了加速语义搜索,必须为向量字段创建索引。索引能显著提高大规模向量数据的检索效率。
python展开代码index_params = client.prepare_index_params()
index_params.add_index(
field_name="dense_vector",
index_name="dense_vector_index",
index_type="IVF_FLAT",
metric_type="IP",
params={"nlist": 128}
)
在上述示例中,为dense_vector字段创建了一个名为dense_vector_index的索引,使用了IVF_FLAT索引类型,metric_type设置为IP,即使用内积作为距离度量。
Milvus还支持其他索引类型和度量类型,更多信息请参考浮动向量索引和度量类型。
创建集合
一旦密集向量和索引参数设置完成,就可以创建一个包含密集向量的集合。以下示例使用create_collection方法创建名为my_dense_collection的集合。
python展开代码client.create_collection(
collection_name="my_dense_collection",
schema=schema,
index_params=index_params
)
插入数据
创建集合后,使用insert方法将包含密集向量的数据插入集合。确保插入的密集向量的维度与添加密集向量字段时定义的维度值一致。
python展开代码data = [
{"dense_vector": [0.1, 0.2, 0.3, 0.7]},
{"dense_vector": [0.2, 0.3, 0.4, 0.8]},
]
client.insert(
collection_name="my_dense_collection",
data=data
)
执行相似性搜索
基于密集向量的语义搜索是Milvus的核心功能之一,允许您根据向量之间的距离快速找到与查询向量最相似的数据。要执行相似性搜索,准备查询向量和搜索参数,然后调用search方法。
python展开代码search_params = {
"params": {"nprobe": 10}
}
query_vector = [0.1, 0.2, 0.3, 0.7]
res = client.search(
collection_name="my_dense_collection",
data=[query_vector],
anns_field="dense_vector",
search_params=search_params,
limit=5,
output_fields=["pk"]
)
print(res)
# Output
# data: ["[{'id': '453718927992172271', 'distance': 0.7599999904632568, 'entity': {'pk': '453718927992172271'}}, {'id': '453718927992172270', 'distance': 0.6299999952316284, 'entity': {'pk': '453718927992172270'}}]"]
二进制向量
二进制向量是一种特殊的数据表示形式,它将传统的高维浮点向量转换为仅包含0和1的二进制向量。这种转换不仅压缩了向量的大小,还降低了存储和计算成本,同时保持了语义信息。当对于非关键特征的精度要求不高时,二进制向量能够有效保留原始浮点向量的大部分完整性和实用性。
二进制向量在许多应用中都有广泛的用途,尤其是在计算效率和存储优化至关重要的场合。在大规模AI系统中,如搜索引擎或推荐系统,实时处理海量数据是关键。通过减少向量的大小,二进制向量有助于降低延迟和计算成本,而不会显著牺牲精度。此外,二进制向量在资源受限的环境中也非常有用,如移动设备和嵌入式系统,在这些环境下内存和处理能力有限。通过使用二进制向量,可以在这些受限环境中实现复杂的AI功能,同时保持高性能。
概述
二进制向量是一种将复杂对象(如图像、文本或音频)编码为固定长度二进制值的方法。在Milvus中,二进制向量通常表示为位数组或字节数组。例如,一个8维的二进制向量可以表示为[1, 0, 1, 1, 0, 0, 1, 0]。
二进制向量具有以下特点:
- 高效存储:每个维度只需1位存储,大大减少了存储空间。
- 快速计算:可以使用按位操作(如XOR)快速计算向量之间的相似度。
- 固定长度:无论原始文本的长度如何,向量的长度始终保持不变,使得索引和检索更方便。
- 简单直观:直接反映关键词的存在,适用于某些专门的检索任务。
二进制向量可以通过多种方法生成。在文本处理方面,可以使用预定义的词汇表,根据单词的存在与否设置相应的位。在图像处理中,可以使用感知哈希算法(如pHash)生成图像的二进制特征。在机器学习应用中,可以对模型输出进行二值化以获取二进制向量表示。
二进制向量化后,数据可以存储在Milvus中进行管理和向量检索。
在Milvus中使用二进制向量
- 添加向量字段
要在Milvus中使用二进制向量,首先在创建集合时定义一个向量字段来存储二进制向量。该过程包括:
- 设置数据类型为支持的二进制向量数据类型,即
BINARY_VECTOR。 - 使用
dim参数指定向量的维度。请注意,dim必须是8的倍数,因为二进制向量在插入时必须转换为字节数组。每8个布尔值(0或1)将被打包为1个字节。例如,若dim=128,则需要16字节数组进行插入。
python展开代码from pymilvus import MilvusClient, DataType
client = MilvusClient(uri="http://localhost:19530")
schema = client.create_schema(
auto_id=True,
enable_dynamic_fields=True,
)
schema.add_field(field_name="pk", datatype=DataType.VARCHAR, is_primary=True, max_length=100)
schema.add_field(field_name="binary_vector", datatype=DataType.BINARY_VECTOR, dim=128)
在此示例中,添加了一个名为binary_vector的向量字段,用于存储二进制向量。该字段的数据类型是BINARY_VECTOR,维度为128。
- 设置向量字段索引参数
为了加速检索,必须为二进制向量字段创建索引。索引可以显著提高大规模向量数据的检索效率。
python展开代码index_params = client.prepare_index_params()
index_params.add_index(
field_name="binary_vector",
index_name="binary_vector_index",
index_type="BIN_IVF_FLAT",
metric_type="HAMMING",
params={"nlist": 128}
)
在上面的示例中,创建了一个名为binary_vector_index的索引,用于binary_vector字段,使用BIN_IVF_FLAT索引类型。metric_type设置为HAMMING,表示使用汉明距离来衡量相似度。
Milvus支持多种二进制向量索引类型,具体详情请参考Binary Vector Indexes。此外,Milvus还支持其他二进制向量的相似度度量方法,更多信息请参见Metric Types。
- 创建集合
完成二进制向量和索引设置后,可以创建包含二进制向量的集合。以下示例使用create_collection方法创建一个名为my_binary_collection的集合。
python展开代码client.create_collection(
collection_name="my_binary_collection",
schema=schema,
index_params=index_params
)
- 插入数据
创建集合后,使用insert方法将包含二进制向量的数据插入到集合中。需要注意的是,二进制向量应该以字节数组的形式提供,其中每个字节表示8个布尔值。
例如,对于一个128维的二进制向量,需要16个字节的数组(因为128位 ÷ 8位/字节 = 16字节)。以下是插入数据的示例代码:
python展开代码def convert_bool_list_to_bytes(bool_list):
if len(bool_list) % 8 != 0:
raise ValueError("布尔列表的长度必须是8的倍数")
byte_array = bytearray(len(bool_list) // 8)
for i, bit in enumerate(bool_list):
if bit == 1:
index = i // 8
shift = i % 8
byte_array[index] |= (1 << shift)
return bytes(byte_array)
bool_vectors = [
[1, 0, 0, 1, 1, 0, 1, 1, 0, 1, 0, 1, 0, 1, 0, 0] + [0] * 112,
[0, 1, 0, 1, 0, 1, 0, 0, 1, 1, 0, 0, 1, 1, 0, 1] + [0] * 112,
]
data = [{"binary_vector": convert_bool_list_to_bytes(bool_vector) for bool_vector in bool_vectors}]
client.insert(
collection_name="my_binary_collection",
data=data
)
- 进行相似度搜索
相似度搜索是Milvus的核心功能之一,它允许你根据向量之间的距离快速找到与查询向量最相似的数据。要使用二进制向量进行相似度搜索,准备查询向量和搜索参数,然后调用search方法。
在搜索操作中,二进制向量也必须以字节数组的形式提供。确保查询向量的维度与定义时指定的dim匹配,并且每8个布尔值被转换为1个字节。
python展开代码search_params = {
"params": {"nprobe": 10}
}
query_bool_list = [1, 0, 0, 1, 1, 0, 1, 1, 0, 1, 0, 1, 0, 1, 0, 0] + [0] * 112
query_vector = convert_bool_list_to_bytes(query_bool_list)
res = client.search(
collection_name="my_binary_collection",
data=[query_vector],
anns_field="binary_vector",
search_params=search_params,
limit=5,
output_fields=["pk"]
)
print(res)
搜索结果将返回与查询向量最相似的数据。
更多关于相似度搜索的参数,请参考[Basic ANN Search]**。
稀疏向量
稀疏向量是信息检索和自然语言处理中的一种重要数据表示方法。尽管密集向量因其出色的语义理解能力而广受欢迎,但在需要精确匹配关键字或短语的应用中,稀疏向量通常能够提供更准确的结果。
概述
稀疏向量是一种高维向量的特殊表示方式,其中大多数元素为零,只有少数维度具有非零值。这一特点使得稀疏向量在处理大规模、高维且稀疏的数据时尤为有效。常见的应用包括:
文本分析:将文档表示为词袋向量,每个维度对应一个单词,只有在文档中出现的单词才具有非零值。
推荐系统:用户-项目交互矩阵,每个维度表示一个用户对某个项目的评分,而大多数用户只与少数项目有交互。
图像处理:局部特征表示,只关注图像中的关键点,从而生成高维稀疏向量。
如下面的示意图所示,密集向量通常表示为连续的数组,其中每个位置都有一个值(例如,[0.3, 0.8, 0.2, 0.3, 0.1])。而稀疏向量则仅存储非零元素及其索引,通常表示为键值对(例如,[{2: 0.2}, ..., {9997: 0.5}, {9999: 0.7}])。这种表示方式显著减少了存储空间并提高了计算效率,尤其是在处理极高维度数据时(例如,10,000维)。
稀疏向量表示
稀疏向量可以通过多种方法生成,例如在文本处理中使用TF-IDF(词频-逆文档频率)和BM25。此外,Milvus提供了便捷的方法来帮助生成和处理稀疏向量。详情请参考嵌入(Embeddings)。
对于文本数据,Milvus还提供了全文搜索功能,使您可以直接在原始文本数据上进行向量搜索,而无需使用外部嵌入模型来生成稀疏向量。更多信息,请参阅全文搜索(Full Text Search)。
在向量化后,数据可以存储在Milvus中进行管理和向量检索。下面的图示说明了基本流程。
在Milvus中使用稀疏向量
除了稀疏向量,Milvus还支持密集向量和二进制向量。密集向量适用于捕捉深层语义关系,而二进制向量则在快速相似度比较和内容去重等场景中表现优异。更多信息,请参阅密集向量(Dense Vector)和二进制向量(Binary Vector)。
Milvus支持以以下格式表示稀疏向量:
稀疏矩阵(使用scipy.sparse类)
python展开代码from scipy.sparse import csr_matrix
# 创建稀疏矩阵
row = [0, 0, 1, 2, 2, 2]
col = [0, 2, 2, 0, 1, 2]
data = [1, 2, 3, 4, 5, 6]
sparse_matrix = csr_matrix((data, (row, col)), shape=(3, 3))
# 使用稀疏矩阵表示稀疏向量
sparse_vector = sparse_matrix.getrow(0)
字典列表(格式为{维度索引: 值, ...})
python展开代码# 使用字典表示稀疏向量
sparse_vector = [{1: 0.5, 100: 0.3, 500: 0.8, 1024: 0.2, 5000: 0.6}]
元组迭代器列表(格式为[(维度索引, 值)])
python展开代码# 使用元组列表表示稀疏向量
sparse_vector = [[(1, 0.5), (100, 0.3), (500, 0.8), (1024, 0.2), (5000, 0.6)]]
添加向量字段
在Milvus中使用稀疏向量时,创建集合时需要定义一个字段来存储稀疏向量。此过程包括:
- 设置数据类型为支持的稀疏向量数据类型:SPARSE_FLOAT_VECTOR。
- 无需指定维度。
python展开代码from pymilvus import MilvusClient, DataType
client = MilvusClient(uri="http://localhost:19530")
client.drop_collection(collection_name="my_sparse_collection")
schema = client.create_schema(
auto_id=True,
enable_dynamic_fields=True,
)
schema.add_field(field_name="pk", datatype=DataType.VARCHAR, is_primary=True, max_length=100)
schema.add_field(field_name="sparse_vector", datatype=DataType.SPARSE_FLOAT_VECTOR)
在这个例子中,添加了一个名为sparse_vector的向量字段来存储稀疏向量。该字段的数据类型是SPARSE_FLOAT_VECTOR。
为向量字段设置索引参数
为稀疏向量创建索引的过程与密集向量类似,但在指定的索引类型(index_type)、距离度量(metric_type)和索引参数(params)上有所不同。
python展开代码index_params = client.prepare_index_params()
index_params.add_index(
field_name="sparse_vector",
index_name="sparse_inverted_index",
index_type="SPARSE_INVERTED_INDEX",
metric_type="IP",
params={"drop_ratio_build": 0.2},
)
在上面的示例中:
- 为稀疏向量创建了一个类型为SPARSE_INVERTED_INDEX的索引。对于稀疏向量,可以指定SPARSE_INVERTED_INDEX或SPARSE_WAND。详细信息请参阅稀疏向量索引。
- 对于稀疏向量,metric_type仅支持IP(内积),用于度量两个稀疏向量之间的相似度。更多关于相似度的信息,请参阅度量类型(Metric Types)。
drop_ratio_build是一个针对稀疏向量的可选索引参数。它控制在索引构建过程中排除的较小向量值的比例。例如,使用{"drop_ratio_build": 0.2}时,最小的20%向量值将在索引创建时被排除,从而减少搜索时的计算工作量。
创建集合
完成稀疏向量和索引设置后,您可以创建一个包含稀疏向量的集合。下面的示例使用create_collection方法创建一个名为my_sparse_collection的集合。
python展开代码client.create_collection(
collection_name="my_sparse_collection",
schema=schema,
index_params=index_params
)
插入数据
创建集合后,可以插入包含稀疏向量的数据。
python展开代码sparse_vectors = [
{"sparse_vector": {1: 0.5, 100: 0.3, 500: 0.8}},
{"sparse_vector": {10: 0.1, 200: 0.7, 1000: 0.9}},
]
client.insert(
collection_name="my_sparse_collection",
data=sparse_vectors
)
执行相似度搜索
使用稀疏向量进行相似度搜索时,准备查询向量和搜索参数。
python展开代码# 准备搜索参数
search_params = {
"params": {"drop_ratio_search": 0.2}, # 额外的可选搜索参数
}
# 准备查询向量
query_vector = [{1: 0.2, 50: 0.4, 1000: 0.7}]
在此示例中,drop_ratio_search是稀疏向量的可选参数,允许在搜索过程中对查询向量中的小值进行微调。例如,使用{"drop_ratio_search": 0.2}时,查询向量中的最小20%值将被忽略。
然后,使用search方法执行相似度搜索:
python展开代码res = client.search(
collection_name="my_sparse_collection",
data=query_vector,
limit=3,
output_fields=["pk"],
search_params=search_params,
)
print(res)
# 输出
# data: ["[{'id': '453718927992172266', 'distance': 0.6299999952316284, 'entity': {'pk': '453718927992172266'}}, {'id': '453718927992172265', 'distance': 0.10000000149011612, 'entity': {'pk': '453718927992172265'}}]"]
字符串字段
在Milvus中,VARCHAR 是用于存储字符串类型数据的数据类型,适合存储可变长度的字符串。它可以存储单字节和多字节字符,最大长度为60,535个字符。定义VARCHAR字段时,必须指定最大长度参数max_length。VARCHAR字符串类型提供了一种高效且灵活的方式来存储和管理文本数据,特别适合处理长度不同的字符串。
添加VARCHAR字段
在Milvus中使用字符串数据时,需要在创建集合时定义一个VARCHAR字段。此过程包括:
- 设置数据类型为支持的字符串数据类型,即
VARCHAR。 - 使用
max_length参数指定字符串类型的最大长度,最大值不得超过60,535个字符。
python展开代码from pymilvus import MilvusClient, DataType
client = MilvusClient(uri="http://localhost:19530")
# 定义 schema
schema = client.create_schema(
auto_id=False,
enable_dynamic_fields=True,
)
schema.add_field(field_name="varchar_field1", datatype=DataType.VARCHAR, max_length=100)
schema.add_field(field_name="varchar_field2", datatype=DataType.VARCHAR, max_length=200)
schema.add_field(field_name="pk", datatype=DataType.INT64, is_primary=True)
schema.add_field(field_name="embedding", datatype=DataType.FLOAT_VECTOR, dim=3)
在这个例子中,我们添加了两个VARCHAR字段:varchar_field1和varchar_field2,它们的最大长度分别为100和200个字符。建议根据数据特点设置max_length,确保能够容纳最长的数据,同时避免过度分配空间。此外,我们还添加了一个主键字段pk和一个向量字段embedding。
主键字段和向量字段在创建集合时是必须的。主键字段唯一标识每个实体,而向量字段对于相似度搜索至关重要。更多详细信息,请参考主键字段与AutoID、稠密向量、二进制向量或稀疏向量。
设置索引参数
为VARCHAR字段设置索引参数是可选的,但它可以显著提高检索效率。
在以下示例中,我们为varchar_field1创建了一个AUTOINDEX,意味着Milvus将根据数据类型自动创建适当的索引。更多信息,请参考自动索引(AUTOINDEX)。
python展开代码index_params = client.prepare_index_params()
index_params.add_index(
field_name="varchar_field1",
index_type="AUTOINDEX",
index_name="varchar_index"
)
除了AUTOINDEX,您还可以指定其他标量索引类型,如INVERTED或BITMAP。有关支持的索引类型,请参见标量索引。
此外,在创建集合之前,您还必须为向量字段创建索引。在此示例中,我们使用AUTOINDEX简化了向量索引的设置。
python展开代码# 添加向量索引
index_params.add_index(
field_name="embedding",
index_type="AUTOINDEX", # 使用自动索引简化复杂的索引设置
metric_type="COSINE" # 指定相似度度量类型,选项包括L2、COSINE或IP
)
创建集合
一旦定义了schema和索引,您就可以创建一个包含字符串字段的集合。
python展开代码# 创建集合
client.create_collection(
collection_name="your_collection_name",
schema=schema,
index_params=index_params
)
插入数据
创建集合后,您可以插入包含字符串字段的数据。
python展开代码data = [
{"varchar_field1": "Product A", "varchar_field2": "High quality product", "pk": 1, "embedding": [0.1, 0.2, 0.3]},
{"varchar_field1": "Product B", "varchar_field2": "Affordable price", "pk": 2, "embedding": [0.4, 0.5, 0.6]},
{"varchar_field1": "Product C", "varchar_field2": "Best seller", "pk": 3, "embedding": [0.7, 0.8, 0.9]},
]
client.insert(
collection_name="my_varchar_collection",
data=data
)
在此示例中,我们插入了包含VARCHAR字段(varchar_field1和varchar_field2)、主键字段(pk)和向量表示(embedding)的数据。为确保插入的数据与schema中的字段匹配,建议提前检查数据类型,以避免插入错误。
如果在定义schema时设置了enable_dynamic_fields=True,Milvus允许您插入未提前定义的字符串字段。然而,请注意,这可能会增加查询和管理的复杂性,并可能影响性能。更多信息,请参见动态字段。
搜索和查询
添加了字符串字段后,您可以在搜索和查询操作中使用它们进行过滤,从而获得更精确的搜索结果。
过滤查询
添加字符串字段后,您可以在查询中使用这些字段进行过滤。例如,您可以查询所有varchar_field1等于"Product A"的实体:
python展开代码filter = 'varchar_field1 == "Product A"'
res = client.query(
collection_name="my_varchar_collection",
filter=filter,
output_fields=["varchar_field1", "varchar_field2"]
)
print(res)
# 输出
# data: ["{'varchar_field1': 'Product A', 'varchar_field2': 'High quality product', 'pk': 1}"]
此查询表达式返回所有匹配的实体,并输出它们的varchar_field1和varchar_field2字段。更多有关过滤查询的信息,请参考元数据过滤。
带字符串过滤的向量搜索
除了基本的标量字段过滤外,您还可以将向量相似度搜索与标量字段过滤器结合。例如,以下代码展示了如何将标量字段过滤器添加到向量搜索中:
python展开代码filter = 'varchar_field1 == "Product A"'
res = client.search(
collection_name="my_varchar_collection",
data=[[0.3, -0.6, 0.1]],
limit=5,
search_params={"params": {"nprobe": 10}},
output_fields=["varchar_field1", "varchar_field2"],
filter=filter
)
print(res)
# 输出
# data: ["[{'id': 1, 'distance': -0.06000000238418579, 'entity': {'varchar_field1': 'Product A', 'varchar_field2': 'High quality product'}}]"]
在此示例中,我们首先定义一个查询向量,并在搜索时添加过滤条件varchar_field1 == "Product A"。这确保了搜索结果不仅与查询向量相似,还与指定的字符串过滤条件匹配。更多信息,请参见元数据过滤。
数字字段
数字字段用于在Milvus中存储非向量的数值数据。这些字段通常用于描述与向量数据相关的附加信息,例如年龄、价格等。通过使用这些数据,可以更好地描述向量,并提高数据过滤和条件查询的效率。
数字字段在许多场景中尤其有用。例如,在电子商务推荐中,可以使用价格字段进行过滤;在用户画像分析中,年龄范围可以帮助细化结果。结合向量数据,数字字段可以帮助系统提供相似度搜索,同时更精确地满足个性化用户需求。
支持的数字字段类型
Milvus支持多种数字字段类型,以满足不同的数据存储和查询需求:
| 类型 | 描述 |
|---|---|
| BOOL | 布尔类型,用于存储真或假,适合描述二元状态。 |
| INT8 | 8位整数,适合存储小范围的整数数据。 |
| INT16 | 16位整数,适合中等范围的整数数据。 |
| INT32 | 32位整数,理想用于存储一般整数数据,如产品数量或用户ID。 |
| INT64 | 64位整数,适合存储大范围数据,如时间戳或标识符。 |
| FLOAT | 32位浮点数,适合需要一般精度的数据,如评分或温度。 |
| DOUBLE | 64位双精度浮点数,适合高精度数据,如财务信息或科学计算。 |
添加数字字段
要在Milvus中使用数字字段,需要在集合模式中定义相关字段,将数据类型设置为支持的类型,例如BOOL或INT8。有关支持的数字字段类型的完整列表,请参见支持的数字字段类型。
以下示例展示了如何定义包含数字字段年龄和价格的模式:
python展开代码from pymilvus import MilvusClient, DataType
client = MilvusClient(uri="http://localhost:19530")
schema = client.create_schema(
auto_id=False,
enable_dynamic_fields=True,
)
schema.add_field(field_name="age", datatype=DataType.INT64)
schema.add_field(field_name="price", datatype=DataType.FLOAT)
schema.add_field(field_name="pk", datatype=DataType.INT64, is_primary=True)
schema.add_field(field_name="embedding", datatype=DataType.FLOAT_VECTOR, dim=3)
在创建集合时,主字段和向量字段是必需的。主字段唯一标识每个实体,而向量字段对相似度搜索至关重要。有关更多详细信息,请参见主字段与AutoID、稠密向量、二进制向量或稀疏向量。
设置索引参数
为数字字段设置索引参数是可选的,但可以显著提高检索效率。
在以下示例中,我们为年龄数字字段创建了一个AUTOINDEX,允许Milvus根据数据类型自动创建适当的索引。有关更多信息,请参见AUTOINDEX。
python展开代码index_params = client.prepare_index_params()
index_params.add_index(
field_name="age",
index_type="AUTOINDEX",
index_name="inverted_index"
)
除了AUTOINDEX外,您还可以指定其他数字字段索引类型。有关支持的索引类型,请参见标量索引。
此外,在创建集合之前,您必须为向量字段创建索引。在此示例中,我们使用AUTOINDEX简化向量索引设置。
python展开代码# 添加向量索引
index_params.add_index(
field_name="embedding",
index_type="AUTOINDEX", # 使用自动索引简化复杂的索引设置
metric_type="COSINE" # 指定相似度度量类型,选项包括L2、COSINE或IP
)
创建集合
一旦模式和索引定义完成,您可以创建一个包含数字字段的集合。
python展开代码# 创建集合
client.create_collection(
collection_name="your_collection_name",
schema=schema,
index_params=index_params
)
插入数据
创建集合后,您可以插入包含数字字段的数据。
python展开代码data = [
{"age": 25, "price": 99.99, "pk": 1, "embedding": [0.1, 0.2, 0.3]},
{"age": 30, "price": 149.50, "pk": 2, "embedding": [0.4, 0.5, 0.6]},
{"age": 35, "price": 199.99, "pk": 3, "embedding": [0.7, 0.8, 0.9]},
]
client.insert(
collection_name="my_scalar_collection",
data=data
)
在此示例中,我们插入了包含年龄、价格、主字段pk和向量表示(embedding)的数据。为确保插入的数据与模式中定义的字段匹配,建议提前检查数据类型以避免错误。
如果在定义模式时设置了enable_dynamic_fields=True,Milvus允许您插入未提前定义的数字字段。然而,请注意,这可能会增加查询和管理的复杂性,从而影响性能。有关更多信息,请参见动态字段。
搜索和查询
添加数字字段后,您可以在搜索和查询操作中使用它们进行过滤,以实现更精确的搜索结果。
过滤查询
在添加数字字段后,您可以在查询中使用它们进行过滤。例如,您可以查询所有年龄在30到40之间的实体:
python展开代码filter = "30 <= age <= 40"
res = client.query(
collection_name="my_scalar_collection",
filter=filter,
output_fields=["age", "price"]
)
print(res)
# 输出
# data: ["{'age': 30, 'price': np.float32(149.5), 'pk': 2}", "{'age': 35, 'price': np.float32(199.99), 'pk': 3}"]
此查询表达式返回所有匹配的实体,并输出它们的年龄和价格字段。有关过滤查询的更多信息,请参见元数据过滤。
结合数字过滤的向量搜索
除了基本的数字字段过滤外,您还可以将向量相似度搜索与数字字段过滤结合起来。例如,以下代码展示了如何在向量搜索中添加数字字段过滤条件:
python展开代码filter = "25 <= age <= 35"
res = client.search(
collection_name="my_scalar_collection",
data=[[0.3, -0.6, 0.1]],
limit=5,
search_params={"params": {"nprobe": 10}},
output_fields=["age", "price"],
filter=filter
)
print(res)
# 输出
# data: ["[{'id': 1, 'distance': -0.06000000238418579, 'entity': {'age': 25, 'price': 99.98999786376953}}, {'id': 2, 'distance': -0.12000000476837158, 'entity': {'age': 30, 'price': 149.5}}, {'id': 3, 'distance': -0.18000000715255737, 'entity': {'age': 35, 'price': 199.99000549316406}}]"]
在此示例中,我们首先定义了一个查询向量,并在搜索时添加了过滤条件25 <= age <= 35。这确保搜索结果不仅与查询向量相似,还满足指定的年龄范围。有关更多信息,请参见元数据过滤。
JSON 字段
JSON(JavaScript对象表示法)是一种轻量级的数据交换格式,提供了一种灵活的方式来存储和查询复杂的数据结构。在Milvus中,您可以使用JSON字段存储与向量数据一起的附加结构化信息,从而实现结合向量相似性与结构化过滤的高级搜索和查询。
JSON字段非常适合需要元数据以优化检索结果的应用。例如,在电子商务中,产品向量可以通过类别、价格和品牌等属性进行增强。在推荐系统中,用户向量可以与偏好和人口统计信息结合。以下是一个典型的JSON字段示例:
json展开代码{
"category": "electronics",
"price": 99.99,
"brand": "BrandA"
}
添加JSON字段
要在Milvus中使用JSON字段,需要在集合模式中定义相关字段类型,将数据类型设置为支持的JSON类型,即JSON。
以下是如何定义包含JSON字段的集合模式的示例:
python展开代码from pymilvus import MilvusClient, DataType
client = MilvusClient(uri="http://localhost:19530")
schema = client.create_schema(
auto_id=False,
enable_dynamic_fields=True,
)
schema.add_field(field_name="metadata", datatype=DataType.JSON)
schema.add_field(field_name="pk", datatype=DataType.INT64, is_primary=True)
schema.add_field(field_name="embedding", datatype=DataType.FLOAT_VECTOR, dim=3)
在此示例中,我们添加了一个名为metadata的JSON字段,用于存储与向量数据相关的附加元数据,例如产品类别、价格和品牌信息。
主字段和向量字段在创建集合时是必需的。主字段唯一标识每个实体,而向量字段对相似度搜索至关重要。有关更多详细信息,请参见主字段与AutoID、稠密向量、二进制向量或稀疏向量。
创建集合
在创建集合时,您必须为向量字段创建索引,以确保检索性能。在此示例中,我们使用AUTOINDEX来简化索引设置。有关更多详细信息,请参见AUTOINDEX。
python展开代码index_params = client.prepare_index_params()
index_params.add_index(
field_name="embedding",
index_type="AUTOINDEX",
metric_type="COSINE"
)
使用定义的模式和索引参数创建集合:
python展开代码client.create_collection(
collection_name="my_json_collection",
schema=schema,
index_params=index_params
)
插入数据
创建集合后,您可以插入包含JSON字段的数据。
python展开代码# 要插入的数据
data = [
{
"metadata": {"category": "electronics", "price": 99.99, "brand": "BrandA"},
"pk": 1,
"embedding": [0.12, 0.34, 0.56]
},
{
"metadata": {"category": "home_appliances", "price": 249.99, "brand": "BrandB"},
"pk": 2,
"embedding": [0.56, 0.78, 0.90]
},
{
"metadata": {"category": "furniture", "price": 399.99, "brand": "BrandC"},
"pk": 3,
"embedding": [0.91, 0.18, 0.23]
}
]
# 将数据插入集合
client.insert(
collection_name="your_collection_name",
data=data
)
在此示例中:
- 每个数据条目包括一个主字段(pk),以及作为JSON字段的元数据,用于存储产品类别、价格和品牌等信息。
- embedding是一个三维向量字段,用于向量相似度搜索。
搜索和查询
JSON字段允许在搜索时进行标量过滤,增强了Milvus的向量搜索能力。您可以基于JSON属性与向量相似性进行查询。
过滤查询
您可以根据JSON属性过滤数据,例如匹配特定值或检查数字是否在某个范围内。
python展开代码filter = 'metadata["category"] == "electronics" and metadata["price"] < 150'
res = client.query(
collection_name="my_json_collection",
filter=filter,
output_fields=["metadata"]
)
print(res)
# 输出
# data: ["{'metadata': {'category': 'electronics', 'price': 99.99, 'brand': 'BrandA'}, 'pk': 1}"]
在上述查询中,Milvus过滤出metadata字段类别为“electronics”且价格低于150的实体,返回符合这些条件的实体。
结合JSON过滤的向量搜索
通过将向量相似性与JSON过滤结合,您可以确保检索到的数据不仅在语义上匹配,还满足特定的业务条件,从而使搜索结果更加精确并符合用户需求。
python展开代码filter = 'metadata["brand"] == "BrandA"'
res = client.search(
collection_name="my_json_collection",
data=[[0.3, -0.6, 0.1]],
limit=5,
search_params={"params": {"nprobe": 10}},
output_fields=["metadata"],
filter=filter
)
print(res)
# 输出
# data: ["[{'id': 1, 'distance': -0.2479381263256073, 'entity': {'metadata': {'category': 'electronics', 'price': 99.99, 'brand': 'BrandA'}}}]"]
在此示例中,Milvus返回与查询向量最相似的前5个实体,metadata字段包含品牌“BrandA”。
此外,Milvus支持高级JSON过滤运算符,如JSON_CONTAINS、JSON_CONTAINS_ALL和JSON_CONTAINS_ANY,这可以进一步增强查询能力。有关更多详细信息,请参见元数据过滤。
限制
- 索引限制:由于数据结构的复杂性,不支持对JSON字段进行索引。
- 数据类型匹配:如果JSON字段的键值是整数或浮点数,则只能与另一个整数或浮点数键或INT32/64或FLOAT32/64字段进行比较。如果键值是字符串(VARCHAR),则只能与另一个字符串键进行比较。
- 命名限制:在命名JSON键时,建议仅使用字母、数字字符和下划线,因为其他字符可能在过滤或搜索时导致问题。
- 处理字符串值:对于字符串值(VARCHAR),Milvus按原样存储JSON字段字符串,而不进行语义转换。例如:'a"b'、"a'b"、'a\'b'和"a\"b"按输入存储;然而,'a'b'和"a"b"被视为无效。
- 处理嵌套字典:JSON字段值中的任何嵌套字典都被视为字符串。
数组字段
数组类型用于存储包含多个相同数据类型值的字段。它提供了一种灵活的方式来存储具有多个元素的属性,特别适用于需要保存一组相关数据的场景。在Milvus中,您可以将数组字段与向量数据一起存储,从而满足更复杂的查询和过滤需求。
例如,在音乐推荐系统中,数组字段可以存储歌曲的标签列表;在用户行为分析中,它可以存储用户对歌曲的评分。以下是一个典型的数组字段示例:
json展开代码{
"tags": ["pop", "rock", "classic"],
"ratings": [5, 4, 3]
}
在这个示例中,tags和ratings都是数组字段。tags字段是一个字符串数组,表示歌曲的流派,如流行、摇滚和经典,而ratings字段是一个整数数组,表示用户对歌曲的评分,范围从1到5。这些数组字段提供了一种灵活的方式来存储多值数据,使得在查询和过滤时进行详细分析变得更加容易。
添加数组字段
要在Milvus中使用数组字段,在创建集合模式时定义相关字段类型。该过程包括:
- 将数据类型设置为支持的数组数据类型,即ARRAY。
- 使用element_type参数指定数组中元素的数据类型。可以是Milvus支持的任何标量数据类型,如VARCHAR或INT64。数组中的所有元素必须具有相同的数据类型。
- 使用max_capacity参数定义数组的最大容量,即它可以包含的最大元素数量。
以下是如何定义包含数组字段的集合模式的示例:
python展开代码from pymilvus import MilvusClient, DataType
client = MilvusClient(uri="http://localhost:19530")
schema = client.create_schema(
auto_id=False,
enable_dynamic_fields=True,
)
# 添加一个元素类型为VARCHAR的数组字段
schema.add_field(field_name="tags", datatype=DataType.ARRAY, element_type=DataType.VARCHAR, max_capacity=10)
# 添加一个元素类型为INT64的数组字段
schema.add_field(field_name="ratings", datatype=DataType.ARRAY, element_type=DataType.INT64, max_capacity=5)
# 添加主键字段
schema.add_field(field_name="pk", datatype=DataType.INT64, is_primary=True)
# 添加向量字段
schema.add_field(field_name="embedding", datatype=DataType.FLOAT_VECTOR, dim=3)
在这个示例中:
- tags是一个字符串数组,element_type设置为VARCHAR,表示数组中的元素必须是字符串。max_capacity设置为10,意味着数组最多可以包含10个元素。
- ratings是一个整数数组,element_type设置为INT64,表示元素必须是整数。max_capacity设置为5,允许最多5个评分。
我们还添加了一个主键字段pk和一个向量字段embedding。
主键字段和向量字段在创建集合时是必需的。主键字段唯一标识每个实体,而向量字段对于相似度搜索至关重要。有关更多详细信息,请参考主键字段与AutoID、密集向量、二进制向量或稀疏向量。
设置索引参数
为数组字段设置索引参数是可选的,但可以显著提高检索效率。
在以下示例中,我们为tags字段创建了一个AUTOINDEX,这意味着Milvus将根据数据类型自动创建适当的标量索引。
python展开代码# 准备索引参数
index_params = client.prepare_index_params() # 准备IndexParams对象
index_params.add_index(
field_name="tags", # 要索引的数组字段名称
index_type="AUTOINDEX", # 索引类型
index_name="inverted_index" # 索引名称
)
除了AUTOINDEX,您还可以指定其他标量索引类型,如INVERTED或BITMAP。有关支持的索引类型,请参考标量索引。
此外,您必须在创建集合之前为向量字段创建索引。在此示例中,我们使用AUTOINDEX来简化向量索引设置。
python展开代码# 添加向量索引
index_params.add_index(
field_name="embedding",
index_type="AUTOINDEX", # 使用自动索引以简化复杂的索引设置
metric_type="COSINE" # 指定相似度度量类型,如L2、COSINE或IP
)
创建集合
使用定义的模式和索引参数创建集合:
python展开代码client.create_collection(
collection_name="my_array_collection",
schema=schema,
index_params=index_params
)
插入数据
创建集合后,您可以插入包含数组字段的数据。
python展开代码data = [
{
"tags": ["pop", "rock", "classic"],
"ratings": [5, 4, 3],
"pk": 1,
"embedding": [0.12, 0.34, 0.56]
},
{
"tags": ["jazz", "blues"],
"ratings": [4, 5],
"pk": 2,
"embedding": [0.78, 0.91, 0.23]
},
{
"tags": ["electronic", "dance"],
"ratings": [3, 3, 4],
"pk": 3,
"embedding": [0.67, 0.45, 0.89]
}
]
client.insert(
collection_name="my_array_collection",
data=data
)
在这个示例中:
- 每个数据条目包含一个主键字段(pk),而tags和ratings是用于存储标签和评分的数组字段。
- embedding是一个三维向量字段,用于向量相似度搜索。
搜索和查询
数组字段在搜索时支持标量过滤,增强了Milvus的向量搜索能力。您可以基于数组字段的属性进行查询,同时进行向量相似度搜索。
过滤查询
您可以根据数组字段的属性过滤数据,例如访问特定元素或检查数组元素是否满足某个条件。
python展开代码filter = 'ratings[0] < 4'
res = client.query(
collection_name="my_array_collection",
filter=filter,
output_fields=["tags", "ratings", "embedding"]
)
print(res)
在此查询中,Milvus过滤掉评分数组第一个元素小于4的实体,返回符合条件的实体。
结合数组过滤的向量搜索
通过将向量相似度与数组过滤结合,您可以确保检索到的数据不仅在语义上相似,还符合特定条件,从而使搜索结果更准确,更符合业务需求。
python展开代码filter = 'tags[0] == "pop"'
res = client.search(
collection_name="my_array_collection",
data=[[0.3, -0.6, 0.1]],
limit=5,
search_params={"params": {"nprobe": 10}},
output_fields=["tags", "ratings", "embedding"],
filter=filter
)
print(res)
在这个示例中,Milvus返回与查询向量最相似的前5个实体,同时确保tags数组的第一个元素为"pop"。
此外,Milvus支持高级数组过滤操作符,如ARRAY_CONTAINS、ARRAY_CONTAINS_ALL、ARRAY_CONTAINS_ANY和ARRAY_LENGTH,以进一步增强查询能力。有关更多详细信息,请参考元数据过滤。
限制
- 数据类型:数组字段中的所有元素必须具有相同的数据类型,如element_type所指定的。
- 数组容量:数组字段中的元素数量必须小于或等于创建数组时定义的最大容量,如max_capacity所指定的。
- 字符串处理:数组字段中的字符串值按原样存储,不进行语义转义或转换。例如,'a"b'、"a'b"、'a'b'和"a"b"按输入存储,而'a'b'和"a"b"被视为无效值。
动态字段
在集合的模式中定义的所有字段必须包含在要插入的实体中。如果希望某些字段为可选字段,可以考虑启用动态字段。本主题描述了如何启用和使用动态字段。
概述
在Milvus中,可以通过设置集合中每个字段的名称和数据类型来创建集合模式。当向模式中添加字段时,请确保该字段包含在您打算插入的实体中。如果希望某些字段为可选字段,启用动态字段是一种选择。
动态字段是一个名为$meta的保留字段,其类型为JavaScript对象表示法(JSON)。在实体中未在模式中定义的任何字段将作为键值对存储在此保留的JSON字段中。
对于启用了动态字段的集合,可以像使用模式中明确定义的字段一样,使用动态字段中的键进行标量过滤。
启用动态字段
使用“立即创建集合”方法创建的集合默认启用动态字段。您也可以在创建具有自定义设置的集合时手动启用动态字段。
python展开代码from pymilvus import MilvusClient
client = MilvusClient(uri="http://localhost:19530")
client.create_collection(
collection_name="my_dynamic_collection",
dimension=5,
# highlight-next-line
enable_dynamic_field=True
)
使用动态字段
当在集合中启用动态字段时,所有未在模式中定义的字段及其值将作为键值对存储在动态字段中。
例如,假设您的集合模式仅定义了两个字段,分别为id和vector,并启用了动态字段。现在,将以下数据集插入到此集合中。
json展开代码[
{id: 0, vector: [0.3580376395471989, -0.6023495712049978, 0.18414012509913835, -0.26286205330961354, 0.9029438446296592], color: "pink_8682"},
{id: 1, vector: [0.19886812562848388, 0.06023560599112088, 0.6976963061752597, 0.2614474506242501, 0.838729485096104], color: "red_7025"},
{id: 2, vector: [0.43742130801983836, -0.5597502546264526, 0.6457887650909682, 0.7894058910881185, 0.20785793220625592], color: "orange_6781"},
{id: 3, vector: [0.3172005263489739, 0.9719044792798428, -0.36981146090600725, -0.4860894583077995, 0.95791889146345], color: "pink_9298"},
{id: 4, vector: [0.4452349528804562, -0.8757026943054742, 0.8220779437047674, 0.46406290649483184, 0.30337481143159106], color: "red_4794"},
{id: 5, vector: [0.985825131989184, -0.8144651566660419, 0.6299267002202009, 0.1206906911183383, -0.1446277761879955], color: "yellow_4222"},
{id: 6, vector: [0.8371977790571115, -0.015764369584852833, -0.31062937026679327, -0.562666951622192, -0.8984947637863987], color: "red_9392"},
{id: 7, vector: [-0.33445148015177995, -0.2567135004164067, 0.8987539745369246, 0.9402995886420709, 0.5378064918413052], color: "grey_8510"},
{id: 8, vector: [0.39524717779832685, 0.4000257286739164, -0.5890507376891594, -0.8650502298996872, -0.6140360785406336], color: "white_9381"},
{id: 9, vector: [0.5718280481994695, 0.24070317428066512, -0.3737913482606834, -0.06726932177492717, -0.6980531615588608], color: "purple_4976"}
]
上述数据集包含10个实体,每个实体包括字段id、vector和color。在这里,color字段未在模式中定义。由于集合启用了动态字段,color字段将作为键值对存储在动态字段中。
插入数据
以下代码演示了如何将此数据集插入到集合中。
python展开代码data = [
{"id": 0, "vector": [0.3580376395471989, -0.6023495712049978, 0.18414012509913835, -0.26286205330961354, 0.9029438446296592], "color": "pink_8682"},
{"id": 1, "vector": [0.19886812562848388, 0.06023560599112088, 0.6976963061752597, 0.2614474506242501, 0.838729485096104], "color": "red_7025"},
{"id": 2, "vector": [0.43742130801983836, -0.5597502546264526, 0.6457887650909682, 0.7894058910881185, 0.20785793220625592], "color": "orange_6781"},
{"id": 3, "vector": [0.3172005263489739, 0.9719044792798428, -0.36981146090600725, -0.4860894583077995, 0.95791889146345], "color": "pink_9298"},
{"id": 4, "vector": [0.4452349528804562, -0.8757026943054742, 0.8220779437047674, 0.46406290649483184, 0.30337481143159106], "color": "red_4794"},
{"id": 5, "vector": [0.985825131989184, -0.8144651566660419, 0.6299267002202009, 0.1206906911183383, -0.1446277761879955], "color": "yellow_4222"},
{"id": 6, "vector": [0.8371977790571115, -0.015764369584852833, -0.31062937026679327, -0.562666951622192, -0.8984947637863987], "color": "red_9392"},
{"id": 7, "vector": [-0.33445148015177995, -0.2567135004164067, 0.8987539745369246, 0.9402995886420709, 0.5378064918413052], "color": "grey_8510"},
{"id": 8, "vector": [0.39524717779832685, 0.4000257286739164, -0.5890507376891594, -0.8650502298996872, -0.6140360785406336], "color": "white_9381"},
{"id": 9, "vector": [0.5718280481994695, 0.24070317428066512, -0.3737913482606834, -0.06726932177492717, -0.6980531615588608], "color": "purple_4976"}
]
res = client.insert(
collection_name="my_dynamic_collection",
data=data
)
print(res)
# 输出
# {'insert_count': 10, 'ids': [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]}
使用动态字段进行查询和搜索
Milvus支持在查询和搜索过程中使用过滤表达式,允许您指定要包含在结果中的字段。以下示例演示了如何使用动态字段通过color字段(未在模式中定义)执行查询和搜索。
python展开代码query_vector = [0.3580376395471989, -0.6023495712049978, 0.18414012509913835, -0.26286205330961354, 0.9029438446296592]
res = client.search(
collection_name="my_dynamic_collection",
data=[query_vector],
limit=5,
# highlight-start
filter='color like "red%"',
output_fields=["color"]
# highlight-end
)
print(res)
# 输出
# data: ["[{'id': 1, 'distance': 0.6290165185928345, 'entity': {'color': 'red_7025'}}, {'id': 4, 'distance': 0.5975797176361084, 'entity': {'color': 'red_4794'}}, {'id': 6, 'distance': -0.24996188282966614, 'entity': {'color': 'red_9392'}}]"]
在上述代码示例中使用的过滤表达式中,color like "red%"和likes > 50条件指定color字段的值必须以“red”开头。在示例数据中,只有两个实体满足此条件。因此,当limit(topK)设置为3或更少时,将返回这两个实体。
json展开代码[
{
"id": 4,
"distance": 0.3345786594834839,
"entity": {
"vector": [0.4452349528804562, -0.8757026943054742, 0.8220779437047674, 0.46406290649483184, 0.30337481143159106],
"color": "red_4794",
"likes": 122
}
},
{
"id": 6,
"distance": 0.6638239834383389,
"entity": {
"vector": [0.8371977790571115, -0.015764369584852833, -0.31062937026679327, -0.562666951622192, -0.8984947637863987],
"color": "red_9392",
"likes": 58
}
}
]
架构设计实操
信息检索(IR)系统,也称为搜索,对于各种AI应用至关重要,如增强检索生成(RAG)、图像搜索和产品推荐。开发IR系统的第一步是设计数据模型,这涉及分析业务需求、确定信息的组织方式以及对数据进行索引,以便使其在语义上可搜索。
Milvus支持通过集合架构定义数据模型。集合组织非结构化数据,如文本和图像,以及它们的向量表示,包括用于语义搜索的稠密向量和稀疏向量。此外,Milvus还支持存储和过滤称为“标量”的非向量数据类型。标量类型包括BOOL、INT8/16/32/64、FLOAT/DOUBLE、VARCHAR、JSON和数组。
示例数据架构设计用于搜索新闻文章
搜索系统的数据模型设计涉及分析业务需求并将信息抽象为架构表达的数据模型。例如,要搜索一段文本,必须通过“嵌入”将字面字符串转换为向量,从而实现向量搜索。除了这个基本要求,可能还需要存储其他属性,如发布时间戳和作者。这些元数据允许通过过滤来细化语义搜索,仅返回在特定日期后或由特定作者发布的文本。它们还可能需要与主文本一起检索,以便在应用程序中呈现搜索结果。为了组织这些文本片段,每个片段应分配一个唯一标识符,以整数或字符串形式表示。这些元素对于实现复杂的搜索逻辑至关重要。
一个设计良好的架构很重要,因为它抽象了数据模型,并决定是否可以通过搜索实现业务目标。此外,由于插入到集合中的每一行数据都需要遵循架构,这在很大程度上有助于维护数据一致性和长期质量。从技术角度来看,定义良好的架构导致列数据存储的良好组织和更清晰的索引结构,从而提高搜索性能。
示例:新闻搜索
假设我们想为一个新闻网站构建搜索功能,并且我们有一批包含文本、缩略图和其他元数据的新闻。首先,我们需要分析如何利用这些数据来支持搜索的业务需求。设想需求是基于缩略图和内容摘要检索新闻,并将作者信息和发布时间等元数据作为过滤搜索结果的标准。这些需求可以进一步细分为:
- 通过文本搜索图像,我们可以通过多模态嵌入模型将图像嵌入到向量中,该模型可以将文本和图像数据映射到同一潜在空间。
- 文章的摘要文本通过文本嵌入模型嵌入到向量中。
- 为了根据发布时间进行过滤,日期作为标量字段存储,并需要为标量字段建立索引以实现高效过滤。其他更复杂的数据结构如JSON可以存储在标量中,并对其内容进行过滤搜索(索引JSON是即将推出的功能)。
- 为了检索图像缩略图字节并在搜索结果页面上呈现,图像URL也被存储。摘要文本和标题也是如此。(如果需要,我们也可以将原始文本和图像文件数据存储为标量字段。)
- 为了改善摘要文本的搜索结果,我们设计了一种混合搜索方法。对于一种检索路径,我们使用常规嵌入模型从文本生成稠密向量,例如OpenAI的text-embedding-3-large或开源的bge-large-en-v1.5。这些模型擅长表示文本的整体语义。另一条路径是使用稀疏嵌入模型,如BM25或SPLADE,生成稀疏向量,类似于全文搜索,擅长抓取文本中的细节和个体概念。得益于其多向量特性,Milvus支持在同一数据集合中同时使用这两种模型。对多个向量的搜索可以在单个hybrid_search()操作中完成。
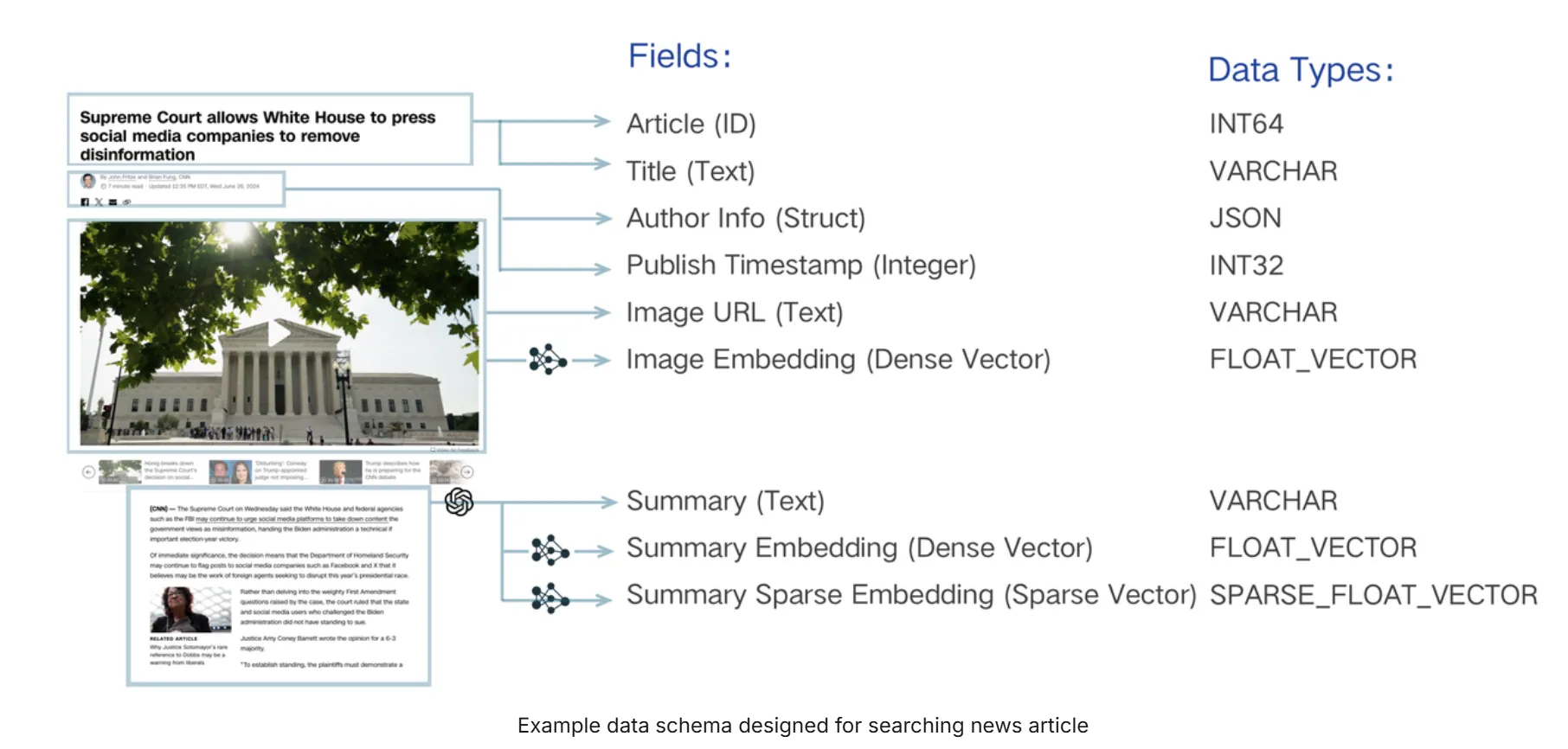
最后,我们还需要一个ID字段来标识每个独立的新闻页面,在Milvus术语中正式称为“实体”。该字段用作主键(简称“pk”)。
| 字段名称 | 类型 | 需要索引 |
|---|---|---|
| article_id (主键) | INT64 | N |
| title | VARCHAR | N |
| author_info | JSON | N (即将支持) |
| publish_ts | INT32 | Y |
| image_url | VARCHAR | N |
| image_vector | FLOAT_VECTOR | Y |
| summary | VARCHAR | N |
| summary_dense_vector | FLOAT_VECTOR | Y |
| summary_sparse_vector | SPARSE_FLOAT_VECTOR | Y |
如何实现示例架构
创建架构
首先,我们创建一个Milvus客户端实例,用于连接到Milvus服务器并管理集合和数据。
要设置架构,我们使用create_schema()创建一个架构对象,并使用add_field()向架构中添加字段。
python展开代码from pymilvus import MilvusClient, DataType
collection_name = "my_collection"
# client = MilvusClient(uri="http://localhost:19530")
client = MilvusClient(uri="./milvus_demo.db")
schema = MilvusClient.create_schema(
auto_id=False,
)
schema.add_field(field_name="article_id", datatype=DataType.INT64, is_primary=True, description="article id")
schema.add_field(field_name="title", datatype=DataType.VARCHAR, max_length=200, description="article title")
schema.add_field(field_name="author_info", datatype=DataType.JSON, description="author information")
schema.add_field(field_name="publish_ts", datatype=DataType.INT32, description="publish timestamp")
schema.add_field(field_name="image_url", datatype=DataType.VARCHAR, max_length=500, description="image URL")
schema.add_field(field_name="image_vector", datatype=DataType.FLOAT_VECTOR, dim=768, description="image vector")
schema.add_field(field_name="summary", datatype=DataType.VARCHAR, max_length=1000, description="article summary")
schema.add_field(field_name="summary_dense_vector", datatype=DataType.FLOAT_VECTOR, dim=768, description="summary dense vector")
schema.add_field(field_name="summary_sparse_vector", datatype=DataType.SPARSE_FLOAT_VECTOR, description="summary sparse vector")
您可能会注意到MilvusClient中的uri参数,它用于连接到Milvus服务器。您可以按如下方式设置参数:
- 如果您只需要一个本地向量数据库来处理小规模数据或原型设计,将uri设置为本地文件,例如../milvus.db,是最方便的方法,因为它会自动利用Milvus Lite将所有数据存储在该文件中。
- 如果您有大规模数据,例如超过一百万个向量,可以在Docker或Kubernetes上设置一个性能更好的Milvus服务器。在这种设置中,请使用服务器地址和端口作为您的uri,例如http://localhost:19530。如果您在Milvus上启用了身份验证功能,请使用“<your_username>:<your_password>”作为令牌,否则请不要设置令牌。
- 如果您使用Zilliz Cloud,这是Milvus的完全托管云服务,请调整uri和令牌,以对应Zilliz Cloud中的公共端点和API密钥。
至于MilvusClient.create_schema中的auto_id,AutoID是主字段的一个属性,用于确定是否启用主字段的自动递增。由于我们将字段article_id设置为主键并希望手动添加文章ID,因此我们将auto_id设置为False以禁用此功能。
在向架构对象添加所有字段后,我们的架构对象与上表中的条目一致。
定义索引
在定义了包含元数据和图像及摘要数据的向量字段的各种字段的架构后,下一步是准备索引参数。索引对于优化向量的搜索和检索至关重要,确保查询性能高效。在接下来的部分中,我们将为集合中指定的向量和标量字段定义索引参数。
python展开代码index_params = client.prepare_index_params()
index_params.add_index(
field_name="image_vector",
index_type="AUTOINDEX",
metric_type="IP",
)
index_params.add_index(
field_name="summary_dense_vector",
index_type="AUTOINDEX",
metric_type="IP",
)
index_params.add_index(
field_name="summary_sparse_vector",
index_type="SPARSE_INVERTED_INDEX",
metric_type="IP",
)
index_params.add_index(
field_name="publish_ts",
index_type="INVERTED",
)
一旦索引参数设置并应用,Milvus就优化了处理向量和标量数据的复杂查询。这种索引提高了集合内相似度搜索的性能和准确性,允许基于图像向量和摘要向量高效检索文章。通过利用稠密向量的AUTOINDEX、稀疏向量的SPARSE_INVERTED_INDEX和标量的INVERTED_INDEX,Milvus可以快速识别并返回最相关的结果,从而显著改善整体用户体验和数据检索过程的有效性。
有许多类型的索引和度量。有关更多信息,请参考Milvus索引类型和Milvus度量类型。
创建集合
在定义了架构和索引后,我们使用这些参数创建一个“集合”。在Milvus中,集合类似于关系数据库中的表。
python展开代码client.create_collection( collection_name=collection_name, schema=schema, index_params=index_params, )
我们可以通过描述集合来验证集合是否已成功创建。
python展开代码collection_desc = client.describe_collection(
collection_name=collection_name
)
print(collection_desc)
其他考虑事项
加载索引
在Milvus中创建集合时,您可以选择立即加载索引或在批量插入一些数据后再加载。通常,您不需要对此做出明确选择,因为上述示例显示,索引会在集合创建后自动为任何插入的数据构建。这允许插入的数据立即可搜索。然而,如果您在集合创建后进行大量插入,并且在某个时间点之前不需要搜索任何数据,您可以通过在创建集合时省略index_params来推迟索引构建,并在插入所有数据后显式调用load来构建索引。这种方法在构建大集合的索引时更高效,但在调用load()之前无法进行搜索。
如何为多租户定义数据模型
多租户的概念通常用于单个软件应用程序或服务需要为多个独立用户或组织提供服务的场景,每个用户或组织都有自己的隔离环境。这在云计算、SaaS(软件即服务)应用程序和数据库系统中经常出现。例如,云存储服务可能利用多租户允许不同公司单独存储和管理其数据,同时共享相同的基础设施。这种方法最大化了资源利用率和效率,同时确保每个租户的数据安全和隐私。
区分租户的最简单方法是将它们的数据和资源彼此隔离。每个租户要么独占特定资源,要么与其他租户共享资源,以管理Milvus实体,如数据库、集合和分区。针对这些实体有特定的方法来实现Milvus多租户。有关更多信息,请参考Milvus多租户页面。


本文作者:Dong
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 CC BY-NC。本作品采用《知识共享署名-非商业性使用 4.0 国际许可协议》进行许可。您可以在非商业用途下自由转载和修改,但必须注明出处并提供原作者链接。 许可协议。转载请注明出处!