目录
https://arxiv.org/abs/2310.11441
SoM(Set-of-Mark)提示是一种新的提示机制,具体来说,就是在图像的不同区域上添加一组视觉标记。通过在输入图像上覆盖数字、字母、掩码或框等各种格式的标记,SoM帮助模型更好地理解和定位图像中的语义上有意义的区域。这样做的目的是增强模型在视觉内容上的定位能力,使其能够更准确地将答案与相应的图像区域关联起来。
也就是改了图的。
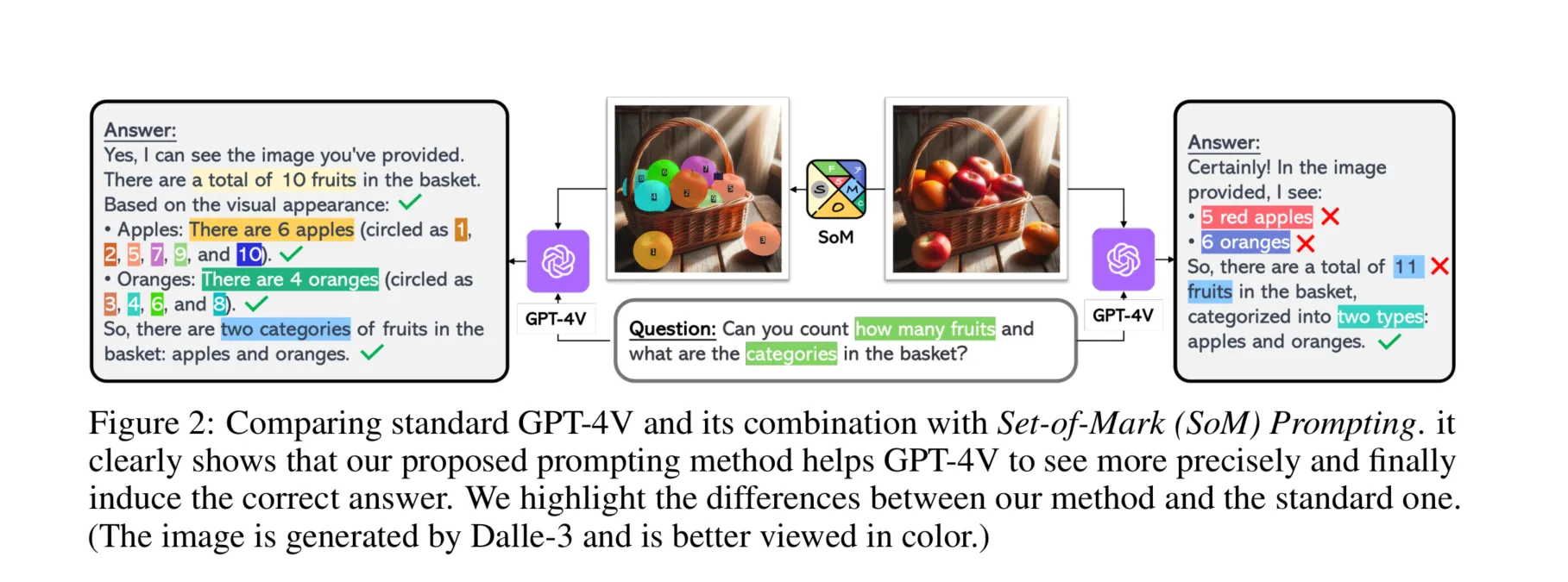
Set-of-Mark 提示
本节介绍了 Set-of-Mark 提示方法,并解释了如何将其应用于提示LMMs,特别是GPT-4V。
2.1 问题定义
通常,LMMs 接收一个图像 和一个长度为 的文本查询 作为输入,并生成一个长度为 的文本输出序列 ,公式如下:
鉴于当前用于LMMs的LLMs的多功能性,输入和输出文本可以由不同类型的字符(例如,字母和数字)组成,并且可以是多语言的。许多研究工作试图改进输入文本 的提示工程,以赋予LLMs更多的推理能力 [46, 52]。
与LLMs的提示工程相反,本研究的目标是开发一种针对输入图像的新提示方法,以释放LMMs的视觉定向能力。换句话说,我们努力使LMM具备逐个位置进行观察的能力。这需要提示策略具有两个基本特性:
- 该方法应能够将图像划分为一组语义上有意义的区域,以与文本输出对齐,这种能力被称为定向。
- 投射到输入图像上的辅助信息应既可被LMM解释,又可被其描述在文本输出中。
考虑到这一点,我们开发了Set-of-Mark提示,这是一种简单的提示方法,通过在图像的有意义区域上覆盖多个标记来实现。这一操作将输入图像 增强为标记图像 ,而保持LMMs的其他输入不变,如图2所示。数学上,公式(1)变为:
尽管 SoM 可以直接应用于所有LMMs,但我们发现并非所有LMMs都具备“说出”这些标记的能力。实际上,我们发现只有GPT-4V在装备了SoM时,显示出明显的定向能力,并显著优于其他LMMs。接下来,我们将解释如何在SoM中将图像分区域并标记图像区域。
2.2 图像分区
给定一个输入图像,我们需要提取有意义的且语义一致的区域。理想情况下,提取过程应是自动或半自动的,以避免用户的额外负担。为此,我们采用了一套图像分割工具。为了支持不同的使用场景,分割工具需要具备以下特性:


本文作者:Dong
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 CC BY-NC。本作品采用《知识共享署名-非商业性使用 4.0 国际许可协议》进行许可。您可以在非商业用途下自由转载和修改,但必须注明出处并提供原作者链接。 许可协议。转载请注明出处!