目录
创新点
DINOv1 创新点
- 图像语义分割能力:DINOv1 自监督训练得到的视觉Transformer在最后一层中自然地包含了图像中对象边界的语义信息,这种特性在之前的卷积网络和有监督学习中并不明显。
- 无需微调的分类性能:DINOv1 的特征在不经过微调的情况下可以通过简单的k-NN分类器在ImageNet上获得78.3%的top-1精度,表明其特征表现力非常强大。
- 动量教师机制:DINOv1采用了一种称为“动量教师”的方法,该方法通过指数移动平均(EMA)更新教师网络参数,帮助避免模式崩塌问题,提高模型的稳定性。
- 多裁剪训练(Multi-crop training):该技术通过将图像裁剪成不同大小的片段并进行多样化数据增强,让学生网络学习局部与全局特征的关系,从而进一步提升模型的表征能力。
- Centering和Sharpening防止模式崩塌:DINOv1 采用了Centering和Sharpening方法,分别通过减去平均值和加入temperature参数,确保模型生成的特征具有多样性,从而有效避免模式崩塌。
DINOv2 创新点
- 基于改进的数据集和去重策略:DINOv2 引入了数据源去重和自监督图像检索方法,确保训练数据的多样性和质量,从而生成适用于各种视觉任务的通用特征。
- 图像级和Patch级目标函数:DINOv2结合了图像级别和Patch级别的目标函数,这种多尺度的特征学习使得模型能同时捕捉整体和细节信息,提高了特征的鲁棒性和准确性。
- 权重解绑与正则化方法(KoLeo Regularizer):通过解开图像级和Patch级别目标函数的权重绑定,以及使用KoLeo正则化方法,确保了特征向量在批次内的均匀分布,提高了模型的泛化能力。
- 高效计算优化:DINOv2 通过Fast and memory-efficient attention、Nested tensors和Efficient stochastic depth等技术提升了自注意力计算的速度和内存使用效率,同时使用FSDP(Fully-Sharded Data Parallel)实现了大模型的高效并行训练。
- 分辨率自适应策略:DINOv2在预训练的最后阶段将图像分辨率提高,使得模型在处理像素级任务时具有更高的精度。这样的方法只在最后阶段使用,以减少计算成本。
- 蒸馏技术优化:DINOv2对小型架构引入了从更大模型进行知识蒸馏的过程,通过大模型向小模型传授特征,有效提高了小模型在多个视觉任务上的表现。
DINOv2
DINOv2(Distillation with No Labels v2)是一种自监督视觉特征学习方法,旨在无需人工标注即可学习鲁棒的视觉特征。它是由Meta AI Research团队提出,延续了之前DINO框架的核心思想,并针对大规模数据和模型训练做了优化。DINOv2在多种视觉任务(如图像分类、语义分割、深度估计等)上表现优异,并且无需微调便能在众多任务上接近或超过弱监督的基线模型。下面我将详细介绍DINOv2的训练过程。
1. 数据集和数据处理
DINOv2使用了一个大规模且多样化的图像数据集(LVD-142M)进行训练。LVD-142M数据集包括超过1.4亿张精心挑选的图像,涵盖了多个视觉任务的子领域,如分类、细粒度分类、分割、深度估计等。数据集构建包括以下步骤:
- 数据筛选和去重:从海量非结构化数据源中筛选出高质量的图像,并使用特征相似度和去重算法去除重复图像。
- 自监督检索:使用自监督学习的视觉特征将非结构化数据中的图像与已标注数据集进行匹配,从而生成一个更加多样化的数据集。
2. 自监督训练框架
DINOv2使用一种组合了多种损失函数的自监督方法,包括DINO和iBOT框架中的损失,并结合了SwAV中的正则化手段,以适应大规模数据和模型训练。主要组件包括:
- 图像级别目标:通过学生网络和教师网络的跨熵损失来对图像特征进行对齐。学生和教师分别从相同图像的不同裁剪中提取类标记(class token),并通过DINO头部进行特征预测。
- Patch级别目标:对学生网络中的部分patch进行掩码处理,使其只接收部分输入,而教师网络则使用完整图像来生成patch特征。通过这种方式,模型可以在patch级别上学习细粒度特征。
- KoLeo正则化:使用一种基于Kozachenko-Leonenko微分熵估计的正则化方法,以确保特征空间中的点均匀分布,增加特征的多样性。
- 优化高分辨率处理:在训练后期提高图像分辨率,以增强对小目标的理解,从而在下游任务如语义分割中表现更好。
3. 模型训练细节和优化
DINOv2在训练大规模模型和数据时进行了多个层面的优化,以提高训练效率和稳定性:
- 高效注意力机制:实现了自定义版本的FlashAttention,用于减少内存占用和加速自注意力层的计算。
- 序列打包(Sequence Packing):通过将不同大小的图像裁剪序列打包成单个长序列并在自注意力层应用块对角掩码,避免多次前向和反向传播,从而加速训练过程。
- 完全分片数据并行(FSDP):模型和优化器参数被分片至不同的GPU上进行并行训练,降低了单个GPU的内存负载,显著提升了训练效率。
4. 知识蒸馏
DINOv2使用了从大模型向小模型的知识蒸馏(Knowledge Distillation)过程,即先训练一个大模型(例如,具有1B参数的ViT模型),再将其输出特征传递给较小的学生模型,使小模型能有效继承大模型的特性。在DINOv2中,学生模型通过模仿教师模型的输出分布进行训练,从而在减少计算资源的同时保持高性能。
5. 实验和评估
DINOv2在多个计算机视觉基准上进行了测试,包括图像分类、实例检索、视频理解和语义分割等任务,表现出了与弱监督方法(如CLIP)相媲美的性能。更重要的是,DINOv2 的特征在多数任务上无需微调即可直接应用,使其在多样性和鲁棒性方面具有显著优势。
总结来说,DINOv2凭借改进的自监督训练方法、有效的模型和数据扩展策略以及知识蒸馏技术,成功实现了高效、鲁棒的视觉特征学习,为多种下游任务提供了有力支持。
DINOv1
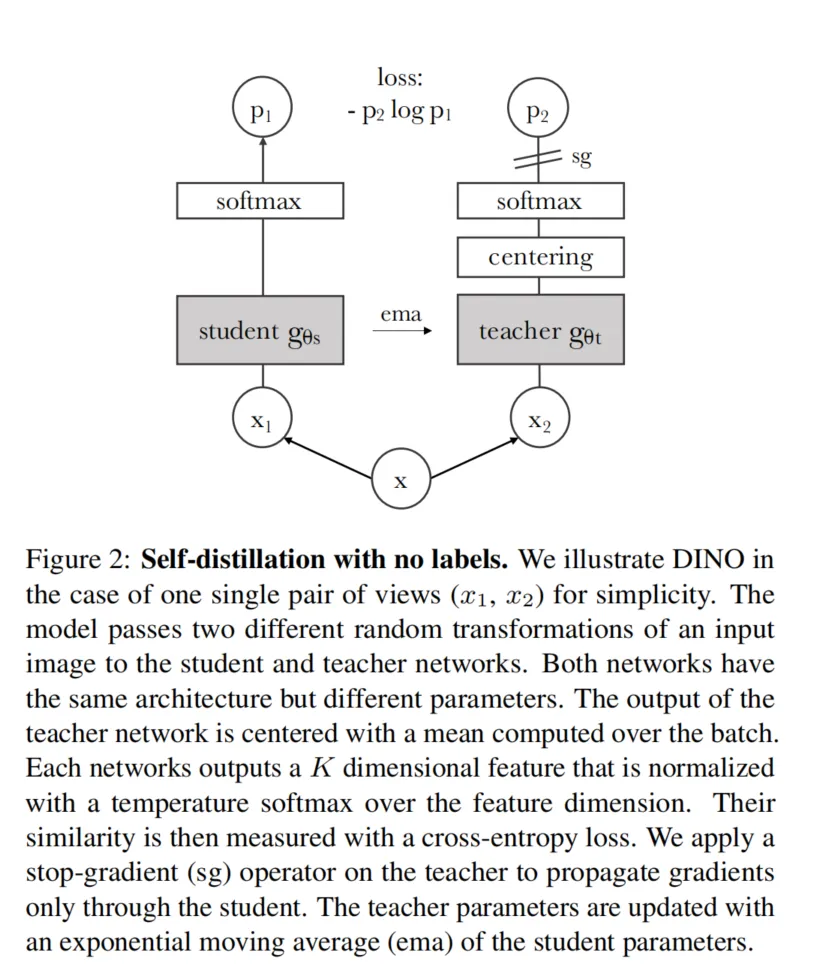
DINOv1(Distillation with No Labels)是一种自监督学习方法,专为视觉变换器(Vision Transformer, ViT)和卷积神经网络(Convolutional Neural Networks, CNN)设计。该方法的主要创新在于它不需要任何人工标签,通过自监督方式来学习特征。DINOv1的核心概念是使用自蒸馏技术,通过教师模型的输出指导学生模型的学习,使学生模型逐渐逼近教师模型的输出表现。以下是DINOv1的详细训练过程:
1. 网络架构
DINOv1训练过程涉及两个相同架构但参数独立的网络,分别是学生网络(student network)和教师网络(teacher network)。在训练过程中:
- 学生网络:这是一个待训练的模型,通过反向传播来更新参数。目标是让学生网络的输出接近教师网络。
- 教师网络:与学生网络架构相同,但参数更新不通过反向传播,而是使用学生网络参数的指数移动平均(EMA)进行更新,以确保教师网络的稳定性和鲁棒性。
2. 视图生成与数据增强
DINOv1从输入图像生成多种视图,包括两种全局视图和若干局部视图。全局视图是较大尺寸的图像裁剪,覆盖了原始图像的大部分区域(如50%以上),而局部视图则是较小的裁剪区域。视图生成和增强的主要目的是提高模型的泛化能力并且防止模型过拟合到特定区域。具体步骤为:
- 多视图增强:随机选择不同的图像增强方法(如旋转、翻转、颜色抖动、高斯模糊等),生成两种全局视图和多种局部视图。
- 局部与全局配对:学生网络同时处理所有视图,而教师网络只处理全局视图。这样可以实现局部与全局之间的特征对齐,并有助于模型学习不同尺度的图像特征。
3. 自蒸馏与无标签知识蒸馏
DINOv1通过自蒸馏(self-distillation)过程进行训练,其核心是在没有标签的情况下利用教师模型的输出指导学生模型的学习。自蒸馏的流程包括:
- 温度参数控制:在学生和教师网络输出之前,使用温度参数对网络输出进行软化(softmax处理),从而调节模型对特征的敏感度。
- 目标中心化与锐化:教师网络的输出会进行中心化处理,并通过锐化过程来强化显著特征,以确保模型的输出不过于平滑。学生网络则直接使用教师网络的中心化与锐化输出作为目标,逐渐逼近这些目标。
- 停止梯度传播:为了避免教师网络被反向传播更新,DINOv1在教师网络的输出上使用了停止梯度(stop-gradient)操作,保证梯度仅通过学生网络更新。
- 交叉熵损失:学生网络输出与教师网络的目标输出之间通过交叉熵损失计算,学生网络的参数则通过梯度下降不断更新以最小化该损失。
4. 教师网络的指数移动平均更新
在DINOv1中,教师网络的参数更新采用学生网络参数的指数移动平均(EMA)。具体公式为: [ \theta_t = \lambda \theta_t + (1 - \lambda) \theta_s ] 其中,(\theta_t)和(\theta_s)分别表示教师和学生网络的参数,(\lambda)是指数移动平均系数,通常从一个接近于1的值逐渐减小。这样,教师网络参数的更新变得更加平滑,有助于提高模型稳定性。
5. 避免模型坍缩
DINOv1在训练过程中使用了一种自适应中心化和温度调节的方式来避免模型坍缩,即模型输出趋于恒定。这种机制通过对比不同视图的输出来促使模型产生多样性特征。具体方法包括:
- 输出中心化:防止某一维度输出主导模型输出,确保特征向量在多维度上均匀分布。
- 锐化机制:增加温度调节,使模型输出具有足够的差异性,从而避免所有输出向均匀分布坍缩。
6. 评估与实验
在实验中,DINOv1利用在ImageNet等大型图像数据集上训练的特征进行评估。通常采用冻结特征线性分类、k近邻(k-NN)分类等方式对模型的学习效果进行评估。结果表明,DINOv1在无需标签的条件下,取得了接近或超过有监督学习的性能,尤其在图像分类、检索等任务中表现突出。
总结
DINOv1的训练过程通过自蒸馏、自适应中心化和锐化等技术实现了无标签下的视觉特征学习,其在视觉变换器(ViT)上的效果尤其显著。DINOv1的自监督特性使其能够从未标注的数据中自动学习出物体边界、语义分割等特征,为多种下游视觉任务提供高质量特征。


本文作者:Dong
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 CC BY-NC。本作品采用《知识共享署名-非商业性使用 4.0 国际许可协议》进行许可。您可以在非商业用途下自由转载和修改,但必须注明出处并提供原作者链接。 许可协议。转载请注明出处!