【深度学习】LLaMA-Factory部署Qwen2-VL-72B-Instruct-GPTQ-Int4
目录
部署 Qwen2-VL-72B-Instruct-GPTQ-Int4 模型
在之前的文章 【深度学习】LLaMA-Factory部署Qwen2-VL 中,已经介绍了如何部署未量化的模型。本篇将讨论如何部署量化过的模型,即 Qwen2-VL-72B-Instruct-GPTQ-Int4。
1. 环境准备
安装 AutoGPTQ 依赖
在部署 Qwen2-VL-72B-Instruct-GPTQ-Int4 模型前,首先需要安装 AutoGPTQ。可以参考 AutoGPTQ 安装方法。
执行以下命令启动 Docker 容器:
bash展开代码docker run -it --rm --gpus=all -v /root/xiedong/:/xiedong/ --net host --shm-size 16G --name llamafactory4 kevinchina/deeplearning:llamafactory20240926 bash
设置 CUDA 环境变量:
bash展开代码echo 'export TORCH_CUDA_ARCH_LIST="7.2;7.5;8.0;8.6;8.7;9.0+PTX"' >> ~/.bashrc
source ~/.bashrc
TORCH_CUDA_ARCH_LIST 是用于控制 PyTorch 在编译 CUDA 扩展时支持的 CUDA 计算能力的环境变量。根据不同的 NVIDIA GPU 架构,设置相应的计算能力版本:
- 计算能力 5.x:Maxwell 架构 (如 GTX 980)
- 计算能力 6.x:Pascal 架构 (如 GTX 1080)
- 计算能力 8.x:Ampere 架构 (如 A100)
安装 AutoGPTQ
克隆 AutoGPTQ 仓库并安装依赖:
bash展开代码git clone https://github.com/PanQiWei/AutoGPTQ.git && cd AutoGPTQ
pip install .
编译过程如下图所示:

安装成功后,如下图所示:
2. 部署 Hugging Face Optimum 库
Hugging Face 的 Optimum 库专为硬件加速模型的训练和推理设计,支持在不同硬件上优化模型部署。可以通过以下命令从源码安装:
bash展开代码python -m pip install git+https://github.com/huggingface/optimum.git
安装成功图示:
3. 部署 Qwen2-VL-72B-Instruct-GPTQ-Int4
切换到应用目录:
bash展开代码cd /app
编辑 sft_xd_seal.yaml 配置文件:
bash展开代码vim examples/inference/sft_xd_seal.yaml
将以下内容写入文件:
yaml展开代码model_name_or_path: /xiedong/Qwen2-VL-72B-Instruct-GPTQ-Int4
# adapter_name_or_path: output/saves/qwen2_vl-7b/lora/sft_xd
template: qwen2_vl
finetuning_type: lora
启动 OpenAPI 接口服务
编辑完配置文件后,使用以下命令启动 OpenAPI 接口服务:
bash展开代码llamafactory-cli api examples/inference/sft_xd_seal.yaml
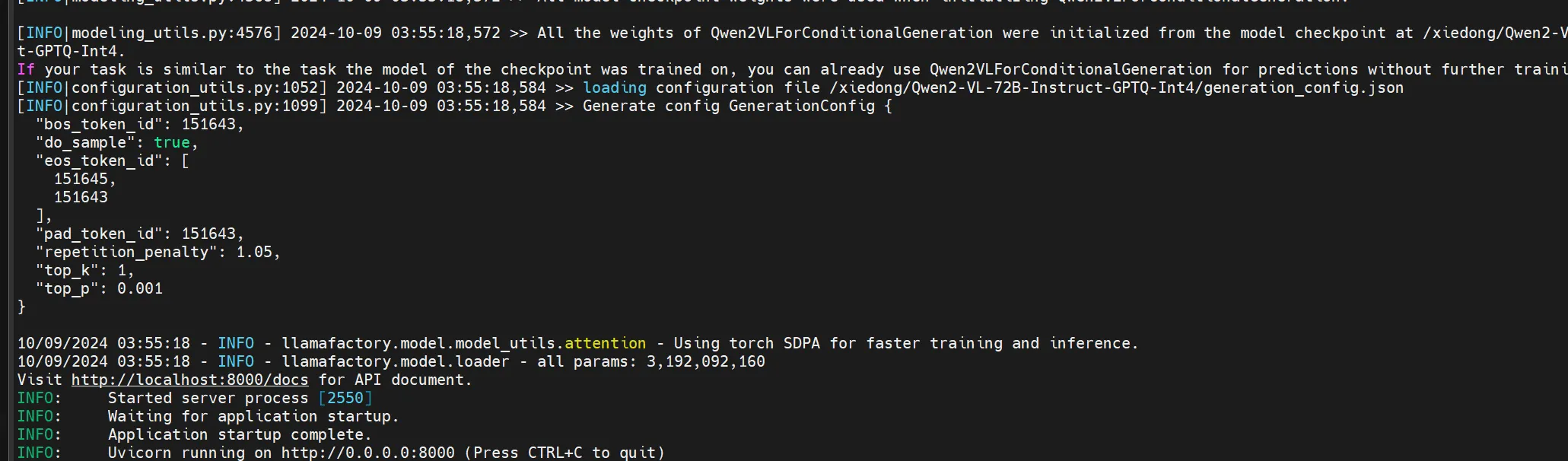
成功部署后,日志如下所示:
bash展开代码[INFO|modeling_utils.py:4568] 2024-10-09 03:55:18,572 >> All model checkpoint weights were used when initializing Qwen2VLForConditionalGeneration. [INFO|modeling_utils.py:4576] 2024-10-09 03:55:18,572 >> All the weights of Qwen2VLForConditionalGeneration were initialized from the model checkpoint at /xiedong/Qwen2-VL-72B-Instruct-GPTQ-Int4. ... INFO: Uvicorn running on http://0.0.0.0:8000 (Press CTRL+C to quit)
部署成功的图示:
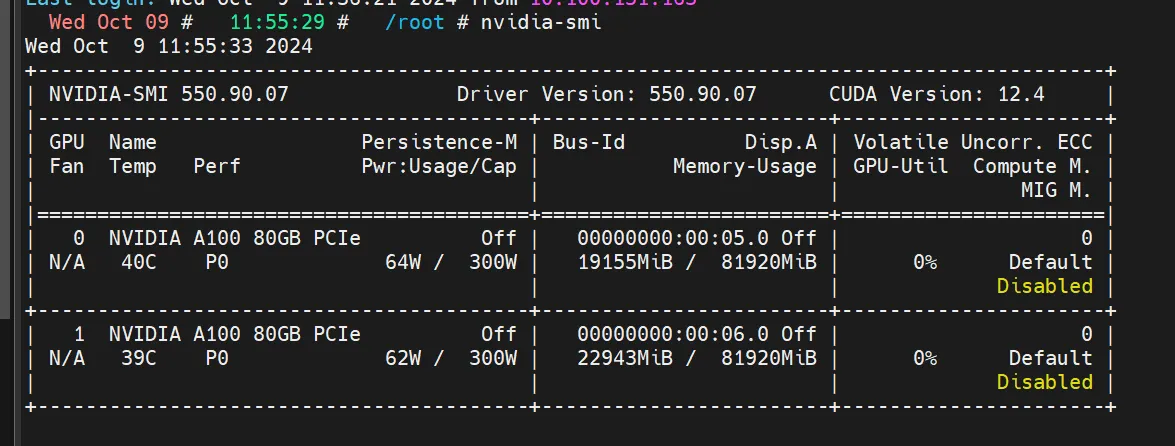
4. 显存占用情况
成功部署后的显存占用图如下所示:
5. OpenAI API 调用示例
以下是一个使用 OpenAI API 进行多模态推理的代码示例:
python展开代码from openai import OpenAI
client = OpenAI(api_key='YOUR_API_KEY', base_url='http://101.136.22.140:8000/v1')
model_name = client.models.list().data[0].id
response = client.chat.completions.create(
model=model_name,
messages=[{
'role': 'user',
'content': [{
'type': 'text',
'text': 'Describe the image please',
}, {
'type': 'image_url',
'image_url': {
'url': 'https://raw.githubusercontent.com/open-mmlab/mmdeploy/main/tests/data/tiger.jpeg',
},
}],
}],
temperature=0.8,
top_p=0.8
)
print(response)
print(response.choices[0].message.content)
访问成功后的返回结果如下图所示:
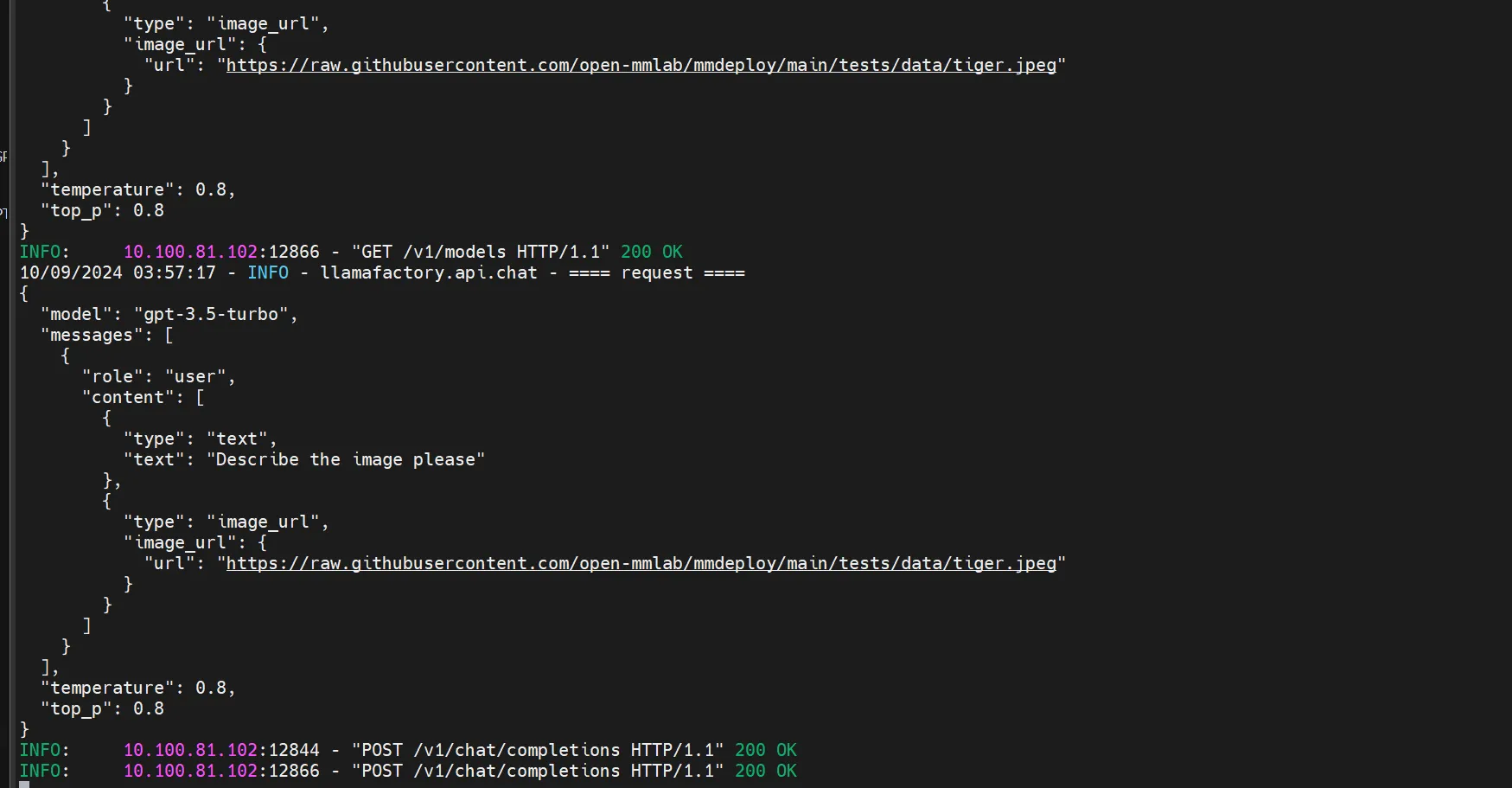
6. 上传我的镜像给大家用
bash展开代码docker push kevinchina/deeplearning:llamafactory20241009
如果对你有用的话,可以打赏哦
打赏


本文作者:Dong
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 CC BY-NC。本作品采用《知识共享署名-非商业性使用 4.0 国际许可协议》进行许可。您可以在非商业用途下自由转载和修改,但必须注明出处并提供原作者链接。 许可协议。转载请注明出处!
目录