目录
摘要
在本报告中,我们介绍了 Qwen2.5-Coder 系列,这是其前身 CodeQwen1.5 的一次重要升级。该系列包括两个模型:Qwen2.5-Coder-1.5B 和 Qwen2.5-Coder-7B。作为一个专注于代码的模型,Qwen2.5-Coder 构建于 Qwen2.5 架构之上,并在超过 5.5 万亿 个tokens的庞大语料库上继续进行预训练。通过精细的数据清洗、可扩展的合成数据生成以及平衡的数据混合,Qwen2.5-Coder 展现了令人印象深刻的代码生成能力,同时保持了通用的多样性。该模型已在广泛的代码相关任务中进行了评估,并在超过 10 个基准测试中实现了state-of-the-art (SOTA) 的性能表现,涵盖了代码生成、补全、推理和修复等任务,并在同等模型大小下持续超越更大规模的模型。我们相信,Qwen2.5-Coder 系列的发布不仅会推动代码智能领域的研究边界,还将通过其宽松的许可协议,鼓励开发者在实际应用中更广泛地采用该模型。
1 引言
随着Large Language Models (LLMs) 的快速发展(Brown, 2020; Achiam et al., 2023; Touvron et al., 2023; Dubey et al., 2024; Jiang et al., 2023; Bai et al., 2023b; Yang et al., 2024; Anthropic, 2024; OpenAI, 2024),专门用于代码处理的语言模型引起了社区的广泛关注。在预训练的LLM基础上,诸如StarCoder 系列(Li et al., 2023; Lozhkov et al., 2024)、CodeLlama 系列(Roziere et al., 2023)、DeepSeek-Coder 系列(Guo et al., 2024)、CodeQwen1.5(Bai et al., 2023a)和 CodeStral(team, 2024)等代码专用LLM,在代码评估任务中表现出色(Chen et al., 2021; Austin et al., 2021; Cassano et al., 2022; Jain et al., 2024)。然而,与最近的state-of-the-art (SOTA) 私有LLM相比,如Claude-3.5-Sonnet(Anthropic, 2024)和 GPT-4o(OpenAI, 2024),不论是开源还是私有的代码LLM仍然存在差距。
基于我们之前的工作CodeQwen1.5,我们很高兴推出Qwen2.5-Coder,这一新的语言模型系列旨在不同模型规模下的代码任务中实现顶级性能。Qwen2.5-Coder 模型源自 Qwen2.5 LLM,继承了其先进的架构和tokenizer。这些模型基于大规模数据集进行预训练,并进一步在为代码任务精心设计的指令数据集上进行微调。该系列包括具有 1.5B 和 7B 参数的模型,以及它们的指令微调版本。我们致力于促进代码LLM、代码代理以及代码助手应用领域的研究和创新。因此,我们将 Qwen2.5-Coder 模型开源给社区,以支持并加速这些领域的进展。
我们投入了大量精力构建了一个大规模的、专用于代码预训练的数据集,该数据集包含超过 5.5 万亿 个tokens。该数据集来源广泛,包括来自公共代码仓库(如GitHub)的大量代码数据,以及通过网络抓取的大规模与代码相关的文本数据。我们采用了复杂的过程来召回和清洗潜在的代码数据,并使用基于弱模型的分类器和评分器过滤掉低质量内容。我们的方法涵盖了文件级别和仓库级别的预训练,以确保全面的覆盖。为了优化性能,并在代码专业知识和一般语言理解之间取得平衡,我们精心策划了一个数据混合集,其中包括代码、数学和通用文本内容。此外,为了将模型转化为适用于下游应用的代码助手,我们开发了一个精心设计的指令微调数据集。该数据集包括大量与代码相关的问题和解决方案,来源于实际应用以及由代码专用LLM生成的合成数据,涵盖了广泛的代码任务。
本报告介绍了Qwen2.5-Coder 系列,这是 CodeQwen1.5 的升级版本,包括两个模型:Qwen2.5-Coder-1.5B 和 Qwen2.5-Coder-7B。这些专用于代码的模型基于 Qwen2.5 架构,并在超过 5.5 万亿 个tokens上进行预训练,展现了卓越的代码生成能力,同时保持了通用性。通过严格的数据处理和训练技术,Qwen2.5-Coder 在超过10个代码相关基准测试中实现了SOTA的表现,在多个任务中超越了更大规模的模型。此次模型的发布旨在推动代码智能领域的研究,并通过宽松的许可协议,促进在实际应用中的广泛采用。
2 模型架构
架构
Qwen2.5-Coder 的架构与 Qwen2.5 相同。表1展示了 Qwen2.5-Coder 两种不同模型规模(1.5B 和 7B 参数)的架构。两种规模的模型在层数方面是相同的,均为28层,且头部大小为128。然而,它们在几个关键方面有所不同。1.5B 模型的隐藏层大小为 1,536,而7B模型的隐藏层大小则为 3,584。1.5B 模型使用 12 个query heads 和 2 个key-value heads,而7B 模型使用 28 个query heads 和 4 个key-value heads,反映了其更大的容量。中间层的大小也随模型规模的增长而扩展,1.5B 模型为 8,960,7B 模型为 18,944。此外,1.5B 模型采用了embedding tying技术,而7B 模型则没有。两种模型的词汇表大小相同,均为 151,646 个tokens,并且都在 5.5 万亿 个tokens上进行了训练。
Tokenization
Qwen2.5-Coder 继承了 Qwen2.5 的词汇表,但引入了几个特殊的tokens,帮助模型更好地理解代码。表2展示了训练过程中引入的特殊tokens概述,这些tokens用于更好地捕捉不同形式的代码数据。这些tokens在代码处理流程中具有特定的用途。例如,<|endoftext|> 标记文本或序列的结束,<|fim_prefix|>、<|fim_middle|> 和 <|fim_suffix|> tokens 用于实现Fill-in-the-Middle (FIM) 技术(Bavarian et al., 2022),该技术让模型预测代码块中缺失的部分。此外,<|fim_pad|> 用于FIM操作中的填充。其他tokens还包括 <|repo_name|>,用于标识仓库名称,<|file_sep|> 用作文件分隔符,以更好地管理仓库级信息。这些tokens在帮助模型从多样化的代码结构中学习,并处理更长且更复杂的上下文时,起到了重要作用。
| 配置 | Qwen2.5-Coder 1.5B | Qwen2.5-Coder 7B |
|---|---|---|
| 隐藏层大小 | 1,536 | 3,584 |
| 层数 | 28 | 28 |
| Query Heads 数量 | 12 | 28 |
| KV Heads 数量 | 2 | 4 |
| Head 大小 | 128 | 128 |
| 中间层大小 | 8,960 | 18,944 |
| Embedding Tying | 是 | 否 |
| 词汇表大小 | 151,646 | 151,646 |
| 训练的tokens数量 | 5.5T | 5.5T |
表1:Qwen2.5-Coder 的架构。
| Token | Token ID | 描述 |
|---|---|---|
| `< | endoftext | >` |
| `< | fim_prefix | >` |
| `< | fim_middle | >` |
| `< | fim_suffix | >` |
| `< | fim_pad | >` |
| `< | repo_name | >` |
| `< | file_sep | >` |
表2:特殊tokens概述。
3 预训练
3.1 预训练数据
大规模、高质量和多样化的数据是预训练模型的基础。为此,我们构建了一个名为 Qwen2.5-Coder-Data 的数据集。该数据集包含五种关键数据类型:Source Code Data、Text-Code Grounding Data、Synthetic Data、Math Data 和 Text Data。在本节中,我们简要介绍了这些数据集的来源及其清理方法。
3.1.1 数据组成
Source Code
我们收集了截至 2024 年 2 月之前发布在 GitHub 上的公共代码仓库,涵盖了92种编程语言。与 StarCoder2 (Lozhkov et al., 2024) 和 DS-Coder (Guo et al., 2024) 类似,我们应用了一系列基于规则的过滤方法。除了原始代码之外,我们还收集了来自 Pull Requests、Commits、Jupyter Notebooks 和 Kaggle 数据集的数据,所有这些数据都经过了类似的规则清理技术处理。
Text-Code Grounding Data
我们从 Common Crawl 中精心挑选了大规模且高质量的文本代码混合数据集,内容包括代码相关文档、教程、博客等。与传统的基于 URL 的多阶段召回方法不同,我们开发了一种粗到细的分层过滤方法处理原始数据。该方法提供了两个关键优势:
- 该方法能够精确控制每个过滤器的责任,确保对每个维度的全面处理。
- 它能够自然地为数据集分配质量分数,保留在最终阶段的数据质量较高,为基于质量的数据混合提供了有价值的见解。
我们为 Text-Code Grounding Data 设计了一条清理管线,每个过滤级别都是使用较小的模型构建的,例如 fastText。尽管我们实验了更大的模型,但并未显著提升效果。一个可能的解释是,较小的模型更关注表面特征,避免了不必要的语义复杂性。
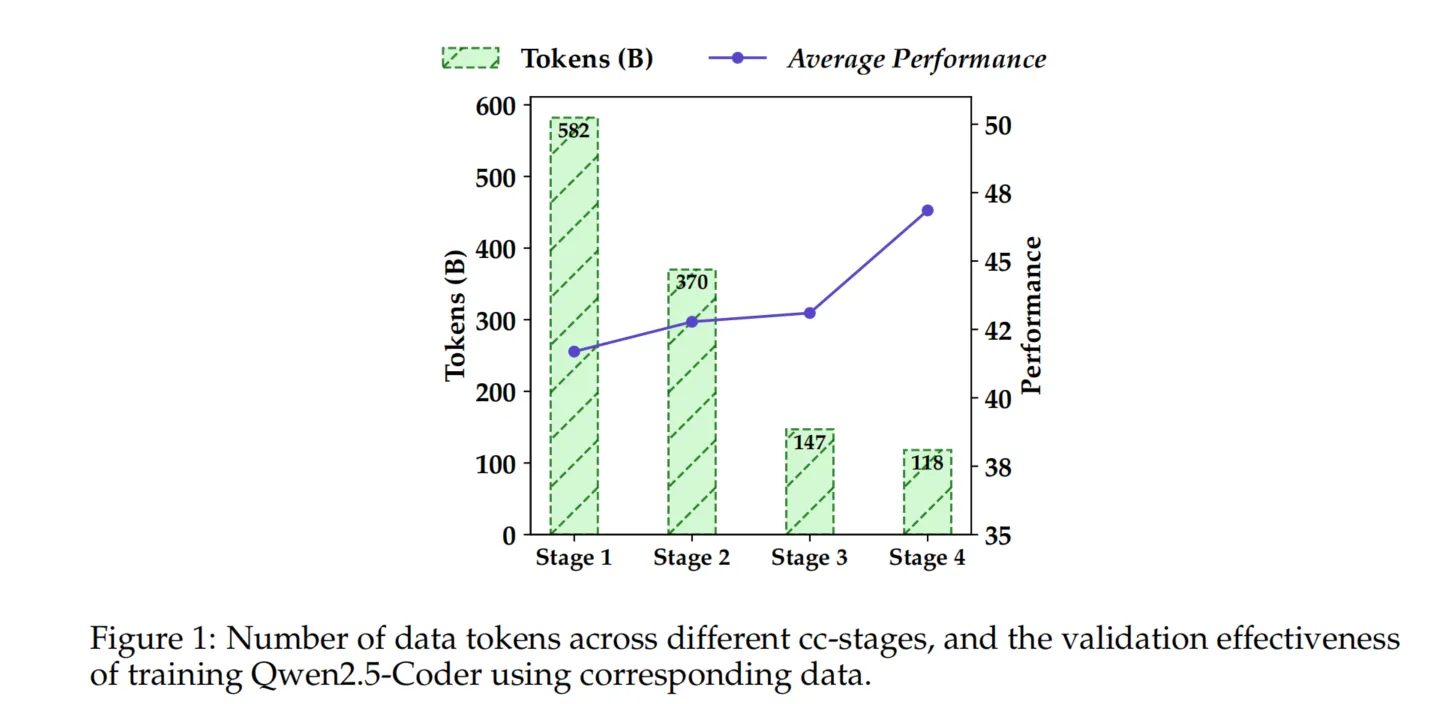
在 Qwen2.5-Coder 中,我们多次迭代地应用了该过程。如图 1 所示,每次迭代都带来了改进。通过四阶段过滤,HumanEval 和 MBPP 的平均得分从 41.6% 提高到 46.8%,证明了高质量 Text-Code Grounding Data 对代码生成的价值。
Synthetic Data
合成数据是解决训练数据预期稀缺的一种有前景的方式。我们使用 CodeQwen1.5(Qwen2.5-Coder 的前身)生成了大规模的合成数据集。为了降低在此过程中产生虚假信息的风险,我们引入了执行器来进行验证,确保只保留可执行的代码。
Math Data
为了增强 Qwen2.5-Coder 的数学能力,我们将 Qwen2.5-Math 的预训练语料库整合到了 Qwen2.5-Coder 数据集中。值得注意的是,数学数据的加入并未对模型的代码任务性能产生负面影响。有关数据收集和清理过程的详细信息,请参阅 Qwen2.5-Math 的技术报告。
Text Data
与数学数据类似,我们将 Qwen2.5 模型预训练语料库中的高质量通用自然语言数据纳入了 Qwen2.5-Coder,以保持 Qwen2.5-Coder 的通用能力。该数据在 Qwen2.5 数据集的清理阶段已经通过了严格的质量检查,因此没有进一步的处理。不过,为了避免与代码数据重叠,所有代码片段都从通用文本数据中移除,确保不同数据源的独立性。
3.1.2 数据混合
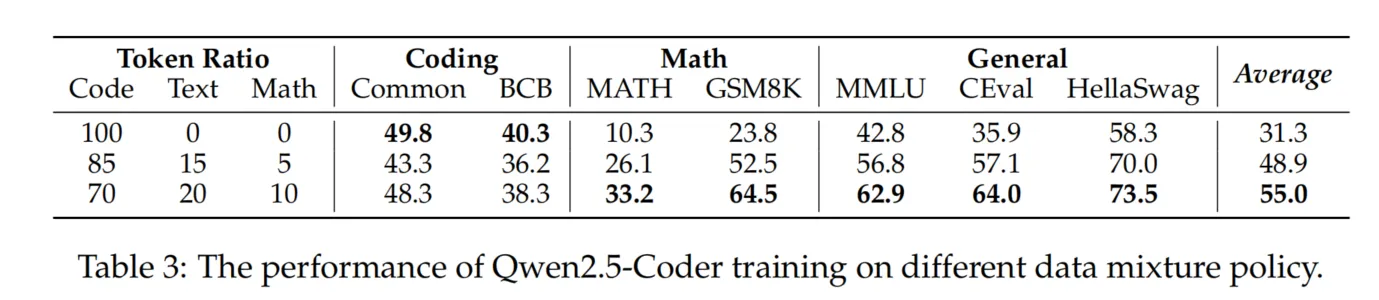
在构建一个稳健的基础模型时,平衡 Code、Math 和 Text 数据至关重要。尽管研究界此前已经探索了这种平衡,但关于其在大规模数据集上的可扩展性,现有证据有限。为了解决这一问题,我们进行了不同比例的 Code、Math 和 Text 数据的实验证明,设计了多个实验以快速确定最佳组合。具体而言,如表3所示,我们比较了三种不同的 Code
比例 —— 100:0:0、85:10:5 和 70:20:10。有趣的是,我们发现 7:2:1 的比例表现优于其他比例,甚至超越了代码比例更高的组合。一个可能的解释是,Math 和 Text 数据可能在代码性能上有所帮助,但仅当其浓度达到特定阈值时才能产生积极影响。在未来的工作中,我们计划探索更有效的比例机制,并研究这种现象背后的原因。最终,我们选择了 70% Code、20% Text 和 10% Math 的最终混合比例。最终的训练数据集包含 5.2 万亿个 tokens。

3.2 训练策略
如第 2 节所示,我们采用了三阶段训练方法来训练 Qwen2.5-Coder,包括文件级预训练、仓库级预训练和指令微调。
3.2.1 文件级预训练
文件级预训练专注于从单个代码文件中进行学习。在此阶段,最大训练序列长度设置为 8,192 个 tokens,涵盖 5.2 万亿高质量数据。训练目标包括下一 token 预测和中间填充(Fill-In-the-Middle,FIM)(Bavarian et al., 2022)。文件级 FIM 的具体格式如图 3 所示。
文件级 FIM 格式
展开代码<|fim_prefix|>{code_pre}<|fim_suffix|>{code_suf}<|fim_middle|>{code_mid}<|endoftext|>
图 3: 文件级 FIM 格式。
3.2.2 仓库级预训练
文件级预训练完成后,我们转向仓库级预训练,旨在增强模型的长上下文处理能力。在此阶段,上下文长度从 8,192 个 tokens 扩展到 32,768 个 tokens,RoPE 的基频从 10,000 调整到 1,000,000。为了进一步利用模型的外推潜力,我们应用了 YARN 机制(Peng et al., 2023),使模型能够处理最长达 131,072(132K)个 tokens 的序列。
在此阶段,我们使用了大量高质量的长代码数据(约 3000 亿 tokens),并将文件级 FIM 扩展至仓库级 FIM,其方法参考 Lozhkov et al. (2024),具体格式如图 4 所示。
仓库级 FIM 格式
展开代码<|repo_name|>{repo_name} <|file_sep|>{file_path1} {file_content1} <|file_sep|>{file_path2} {file_content2} <|file_sep|>{file_path3} <|fim_prefix|>{code_pre}<|fim_suffix|>{code_suf}<|fim_middle|>{code_fim}<|endoftext|>
图 4: 仓库级 FIM 格式。
4 后训练
4.1 指令数据的配方
多语言编程代码识别
我们对 CodeBERT 进行微调,使其能够执行语言识别模型,将文档分类为近 100 种编程语言。我们保留主流编程语言的指令数据,并随机丢弃部分长尾语言的指令数据。如果某个样本包含的代码数据很少,甚至没有代码片段,该样本可能会被归类为“无编程语言”标签。我们删除了大部分不含代码片段的样本,以保持我们的指令模型的代码生成能力。
从 GitHub 中合成指令
对于大量存在于各类网站(例如 GitHub)上的无监督数据(代码片段),我们尝试构建监督的指令数据集。具体而言,我们使用大语言模型(LLM)从 1024 个 tokens 内的代码片段中生成指令,然后使用代码 LLM 生成相应的回答(Sun et al., 2024)。最后,我们使用 LLM 评分器过滤低质量数据,得到最终的指令-回答对。针对不同编程语言的代码片段,我们构建了一个基于代码片段的指令数据集。为了增加指令数据集的多样性,我们反过来先从代码生成答案,然后使用 LLM 评分器过滤低质量数据,获得最终的三元组。同样,针对不同编程语言的代码片段,我们可以使用代码片段构建一个带有通用代码的指令数据集。为了充分发挥我们提出方法的潜力,我们还在初始指令数据集中加入了开源指令数据集。最终,我们将三部分指令数据集组合起来用于监督微调。
多语言代码指令数据
为了弥合不同编程语言之间的差距,我们提出了一个多语言多智能体协作框架,用于生成多语言指令语料库。我们引入了语言特定的智能体,其中一组专用智能体为特定编程语言服务。这些智能体以现有有限的多语言指令语料库中派生的语言特定指令数据为初始数据。多语言数据生成过程可以分为以下几步:
- 语言特定智能体:我们创建了一组专用智能体,每个智能体专注于一种特定编程语言。这些智能体以从精选代码片段中派生的语言特定指令数据为初始数据。
- 协作讨论协议:多个语言特定智能体通过结构化对话生成新的指令和解决方案。该过程可以增强现有语言能力或为新编程语言生成指令。
- 自适应记忆系统:每个智能体维护一个动态记忆库,存储其生成的历史记录,以避免生成相似的样本。
- 跨语言讨论:我们实施了一种新的知识蒸馏技术,使智能体能够跨语言边界共享见解和模式,从而促进对编程概念的更全面理解。
- 协同评估指标:我们开发了一种新的指标来量化模型内不同编程语言之间知识共享和协同的程度。
- 自适应指令生成:该框架包括一个机制,用于根据不同语言间识别出的知识差距动态生成新的指令。
指令数据的基于清单的评分
为了全面评估生成的指令对的质量,我们为每个样本引入了多个评分点:
- 问题与答案的一致性:问题与答案是否一致且正确,适用于微调。
- 问题与答案的相关性:问题与答案是否与计算机领域相关。
- 问题与答案的难度:问题与答案是否具有足够的挑战性。
- 代码是否存在:问题或答案中是否提供了代码。
- 代码正确性:评估提供的代码是否没有语法错误和逻辑缺陷。
- 代码质量:考察代码的变量命名是否合适、缩进是否规范、以及是否遵循最佳实践。
- 代码清晰度:评估代码的清晰度与可理解性,判断是否使用了有意义的变量名、适当的注释、并遵循一致的编码风格。
- 代码注释:评估代码中注释的存在及其对代码功能解释的有用性。
- 易学性:判断该指令对学习基础编程概念的学生是否具有教育价值。
在获得所有评分()后,我们可以通过以下公式得到最终得分:
其中 为一系列预定义的权重。
多语言代码验证沙盒
为了进一步验证代码语法的正确性,我们对所有提取的编程语言代码片段(例如 Python、Java 和 C++)进行代码静态检查。我们将代码片段解析为抽象语法树,并过滤掉解析节点存在错误的代码片段。我们创建了一个支持主要编程语言的多语言沙盒,用于代码静态检查。此外,这个多语言沙盒是一个综合平台,旨在验证多种编程语言的代码片段的正确性。它自动根据特定编程语言的样本生成相关的单元测试,并评估提供的代码片段是否能成功通过这些测试。特别地,只有自包含的代码片段(例如算法问题)才会被送入多语言沙盒进行验证。
该多语言验证沙盒主要由五个部分组成:
-
语言支持模块:
- 实现对多种语言的支持(例如 Python、Java、C++、JavaScript)
- 维护语言特定的解析和执行环境
- 处理每种支持语言的语法和语义分析
-
示例代码库:
- 存储每种支持语言的多样化代码样本
- 按语言、难度级别和编程概念组织样本
- 由语言专家定期更新和维护
-
单元测试生成器:
- 分析样本代码以识别关键功能和边界情况
- 基于预期行为自动生成单元测试
- 生成覆盖多种输入场景和预期输出的测试用例
-
代码执行引擎:
- 提供隔离环境,安全地执行代码片段
- 支持并行执行多个测试用例
- 处理资源分配和超时机制
-
结果分析器:
- 将代码片段的输出与单元测试的预期结果进行比较
- 生成关于测试用例成功与失败的详细报告
- 根据失败的测试用例提供改进建议
4.2 训练策略
Coarse-to-fine Fine-tuning(粗到细微调)
我们首先合成了数千万个低质量但多样化的指令样本来微调基础模型。在第二阶段,我们采用数百万个高质量的指令样本,通过拒绝采样(rejection sampling)和监督微调(supervised fine-tuning)来提高指令模型的性能。对于同一个查询(query),我们使用大型语言模型(LLM)生成多个候选项,然后利用LLM对候选项进行评分,选择最优解进行监督微调。
Mixed Tuning(混合调优)
由于大多数指令数据长度较短,我们使用FIM格式(Fill-in-the-Middle)构造指令对,以保持基础模型的长上下文处理能力。受到编程语言语法规则和实际场景中用户习惯的启发,我们利用tree-sitter-languages解析代码片段,提取基本逻辑块作为中间代码进行填充。例如,抽象语法树(AST)以树的形式表示Python代码的结构,树中的每个节点代表源代码中的一个构造。树的层次结构反映了代码中构造的语法嵌套,包含各种元素,如表达式、语句和函数。通过遍历和操作AST,我们可以随机提取多层节点,并使用同一文件的代码上下文来揭示被遮蔽的节点。最终,我们通过大量的标准SFT数据(监督微调数据)和少量的FIM指令样本来优化指令模型。
5 数据去污染
为了确保Qwen2.5-Coder不会因测试集泄露而产生虚高的结果,我们对所有数据进行了去污染处理,包括预训练和后训练的数据集。我们移除了关键数据集,如HumanEval、MBPP、GSM8K和MATH。过滤过程使用了10-gram重叠方法,删除了所有与测试数据在字符串级别有10-gram重叠的训练数据。
6 基础模型的评估
对于基础模型,我们在代码生成、代码补全、代码推理、数学推理、自然语言理解和长上下文建模六个关键方面进行了全面且公正的评估。为了确保所有结果的可复现性,我们公开了所有评估代码1。在模型对比中,我们选择了最流行和最强大的开源语言模型,包括StarCoder2和DeepSeek-Coder系列。以下是本节评估中使用的工具列表。
6.1 代码生成
HumanEval 和 MBPP
代码生成是代码模型处理更复杂任务的基本能力。我们选择了两个流行的代码生成基准测试。
评估工具的公开链接
| 工具 | 公共链接 |
|---|---|
| Qwen2.5-Coder-1.5B | https://hf.co/qwen/Qwen/Qwen2.5-Coder-1.5B |
| Qwen2.5-Coder-7B | https://hf.co/qwen/Qwen/Qwen2.5-Coder-7B |
| CodeQwen1.5-7B-Base | https://huggingface.co/Qwen/CodeQwen1.5-7B |
| StarCoder2-3B | https://hf.co/bigcode/starcoder2-3b |
| StarCoder2-7B | https://hf.co/bigcode/starcoder2-7b |
| StarCoder2-15B | https://hf.co/bigcode/starcoder2-15b |
| DS-Coder-1.3B-Base | https://hf.co/deepseek-ai/deepseek-coder-1.3b-base |
| DS-Coder-6.7B-Base | https://hf.co/deepseek-ai/deepseek-coder-6.7b-base |
| DS-Coder-33B-Base | https://hf.co/deepseek-ai/deepseek-coder-33b-base |
| DS-Coder-V2-Lite-Base | https://hf.co/deepseek-ai/DeepSeek-Coder-V2-Lite-Base |
| DS-Coder-V2-Base | https://hf.co/deepseek-ai/DeepSeek-Coder-V2-Base |
表4:本节中发布和使用的所有评估工具。
模型评估结果
HumanEval、MBPP 和 BigCodeBench 的模型表现
表5展示了各个模型在 HumanEval、MBPP 和 BigCodeBench-Complete 任务中的表现。这些基准测试用于评估代码生成能力,其中 HumanEval 包含164个手工编写的编程任务,每个任务提供Python函数签名和文档字符串作为输入;而 MBPP 包含974个由众包贡献者创建的编程问题,每个问题包括问题描述(文档字符串)、函数签名和三个测试用例。为了确保评估的准确性,EvalPlus 对 HumanEval 进行了扩展,增加了80倍的独特测试用例,并修正了其中不准确的参考答案,生成 HumanEval+。同样,MBPP+ 增加了原始MBPP的35倍测试用例。
此外,MBPP的3-shot评估特别适合用于监控模型在训练过程中的收敛情况。训练初期模型往往不稳定,导致指标显著波动,而3-shot的简单例子能够有效缓解这一问题。因此,我们也报告了MBPP 3-shot的表现结果。
如下表5所示,Qwen2.5-Coder在基本的代码生成任务中表现出色,在相同模型大小的开源模型中实现了最先进的结果,甚至超过了一些更大规模的模型。特别是,Qwen2.5-Coder-7B-Base 在所有五个指标上均超越了之前表现最佳的密集模型 DS-Coder-33B-Base。
表5:各种模型在 HumanEval、MBPP 和 BigCodeBench-Complete 任务中的性能表现
| 模型 | 参数量 | HumanEval (HE) | HumanEval+ (HE+) | MBPP | MBPP+ | BigCodeBench (3-shot) | BigCodeBench (Full) | BigCodeBench (Hard) |
|---|---|---|---|---|---|---|---|---|
| 1B+ 模型 | ||||||||
| StarCoder2-3B | 3B | 31.7 | 27.4 | 60.2 | 49.1 | - | 21.4 | 4.7 |
| DS-Coder-1.3B | 1.3B | 34.8 | 26.8 | 55.6 | 46.9 | 46.2 | 26.1 | 3.4 |
| Qwen2.5-Coder-1.5B | 1.5B | 43.9 | 36.6 | 69.2 | 58.6 | 59.2 | 34.6 | 9.5 |
| 6B+ 模型 | ||||||||
| StarCoder2-7B | 7B | 35.4 | 29.9 | 54.4 | 45.6 | - | 27.7 | 8.8 |
| StarCoder2-15B | 15B | 46.3 | 37.8 | 66.2 | 53.1 | - | 38.4 | 12.2 |
| DS-Coder-6.7B-Base | 6.7B | 47.6 | 39.6 | 70.2 | 56.6 | 60.6 | 41.1 | 11.5 |
| DS-Coder-V2-Lite-Base | 2.4/16B | 40.9 | 34.1 | 71.9 | 59.4 | - | 30.6 | 8.1 |
| CodeQwen1.5-7B-Base | 7B | 51.8 | 45.7 | 72.2 | 60.2 | 61.8 | 45.6 | 15.6 |
| Qwen2.5-Coder-7B-Base | 7B | 61.6 | 53.0 | 76.9 | 62.9 | 68.8 | 45.8 | 16.2 |
| 20B+ 模型 | ||||||||
| DS-Coder-33B-Base | 33B | 54.9 | 47.6 | 74.2 | 60.7 | 66.0 | 49.1 | 20.3 |
如表5所示,Qwen2.5-Coder 在 BigCodeBench-Complete 上继续展现出强劲的表现,证明了该模型在处理复杂指令跟随任务中的广泛泛化能力。
多编程语言评估
上述评估主要集中在Python语言上。然而,我们期望一个强大的代码模型不仅在Python上表现优秀,还能够在多种编程语言中展现出色的能力,以满足软件开发过程中不断变化的复杂需求。为了更全面地评估Qwen2.5-Coder在处理多编程语言方面的能力,我们选择了 MultiPL-E 基准,评估了其中八种主流编程语言,包括Python、C++、Java、PHP、TypeScript、C#、Bash和JavaScript。
表6:不同模型在MultiPL-E多编程语言任务中的性能表现
| 模型 | 参数量 | Python | C++ | Java | PHP | TS | C# | Bash | JS | 平均分 |
|---|---|---|---|---|---|---|---|---|---|---|
| 1B+ 模型 | ||||||||||
| StarCoder2-3B | 3B | 31.7 | 30.4 | 29.8 | 32.9 | 39.6 | 34.8 | 13.9 | 35.4 | 31.1 |
| DS-Coder-1.3B-Base | 1.3B | 34.8 | 31.1 | 32.3 | 24.2 | 28.9 | 36.7 | 10.1 | 28.6 | 28.3 |
| Qwen2.5-Coder-1.5B | 1.5B | 42.1 | 42.9 | 38.6 | 41.0 | 49.1 | 46.2 | 20.3 | 49.1 | 41.1 |
| 6B+ 模型 | ||||||||||
| StarCoder2-7B | 7B | 35.4 | 40.4 | 38.0 | 30.4 | 34.0 | 46.2 | 13.9 | 36.0 | 34.3 |
| StarCoder2-15B | 15B | 46.3 | 47.2 | 46.2 | 39.1 | 42.1 | 53.2 | 15.8 | 43.5 | 41.7 |
| DS-Coder-6.7B-Base | 6.7B | 49.4 | 50.3 | 43.0 | 38.5 | 49.7 | 50.0 | 28.5 | 48.4 | 44.7 |
| DS-Coder-V2-Lite-Base | 2.4/16B | 40.9 | 45.9 | 34.8 | 47.2 | 48.4 | 41.7 | 19.6 | 44.7 | 40.4 |
| CodeQwen1.5-7B-Base | 7B | 51.8 | 52.2 | 42.4 | 46.6 | 52.2 | 55.7 | 36.7 | 49.7 | 48.4 |
| Qwen2.5-Coder-7B-Base | 7B | 61.6 | 62.1 | 53.2 | 59.0 | 64.2 | 60.8 | 38.6 | 60.3 | 57.5 |
| 20B+ 模型 | ||||||||||
| DS-Coder-33B-Base | 33B | 56.1 | 58.4 | 51.9 | 44.1 | 52.8 | 51.3 | 32.3 | 55.3 | 50.3 |
如表6所示,Qwen2.5-Coder在多编程语言的评估中同样取得了最先进的结果,其能力在各语言间表现均衡,且在八种语言中的五种上得分超过了60%。
6.2 代码补全
HumanEval Infilling
许多开发者辅助工具依赖于根据前后代码片段自动补全代码的能力。Qwen2.5-Coder 采用了 Fill-In-the-Middle (FIM) 训练策略,正如 Bavarian 等人(2022年)所介绍的那样,这使得模型能够生成上下文一致的代码。为了评估其代码补全的能力,我们使用了 HumanEval Infilling 基准测试(Allal 等人,2023年)。该基准测试挑战模型准确预测从 HumanEval 衍生任务中的缺失代码部分。我们在 Python、Java 和 JavaScript 语言上使用了单行补全设置,重点在给定上下文中预测单行代码。性能通过 Exact Match(精确匹配)指标进行衡量,即模型生成的第一行代码与参考代码完全匹配的比例。
表7展示了 Qwen2.5-Coder 在模型大小方面超越了其他模型的表现。具体而言,Qwen2.5-Coder-1.5B 平均性能提升了3.7%,与许多参数量超过6B的模型表现相当。此外,Qwen2.5-Coder-7B-Base 成为6B以上参数模型中的领先者,其性能甚至与 33B 参数量 的 DS-Coder-33B-Base 模型相媲美。值得注意的是,我们没有将 DS-Coder-v2-236B 纳入对比,因为它的设计重点并非代码补全任务。
表7:各模型在 HumanEval Infilling 任务中的表现
| 模型 | 参数量 | Python | Java | JavaScript | 平均分 |
|---|---|---|---|---|---|
| 1B+ 模型 | |||||
| StarCoder2-3B | 3B | 70.9 | 84.4 | 81.8 | 79.0 |
| DS-Coder-1.3B-Base | 1.3B | 72.8 | 84.3 | 81.7 | 79.6 |
| Qwen2.5-Coder-1.5B | 1.5B | 77.0 | 85.6 | 85.0 | 82.5 |
| 6B+ 模型 | |||||
| StarCoder2-7B | 7B | 70.8 | 86.0 | 84.4 | 80.4 |
| StarCoder2-15B | 15B | 78.1 | 87.4 | 84.1 | 81.3 |
| DS-Coder-6.7B-Base | 6.7B | 78.1 | 87.4 | 84.1 | 83.2 |
| DS-Coder-V2-Lite-Base | 2.4/16B | 78.7 | 87.8 | 85.9 | 84.1 |
| CodeQwen1.5-7B-Base | 7B | 75.8 | 85.7 | 85.0 | 82.2 |
| Qwen2.5-Coder-7B-Base | 7B | 79.7 | 88.5 | 87.6 | 85.3 |
| 20B+ 模型 | |||||
| DS-Coder-33B-Base | 33B | 80.1 | 89.0 | 86.8 | 85.3 |
6.3 代码推理
代码是一种高度抽象的逻辑语言,基于代码的推理能力能够帮助我们判断模型是否真正理解代码背后的逻辑流程。我们选择了 CRUXEval(Gu 等人,2024年)作为基准测试,它包含800个Python函数及其对应的输入输出示例。CRUXEval 包含两个不同的任务:CRUXEval-I,模型需要根据给定的输入预测输出;CRUXEval-O,模型需要根据已知的输出预测输入。在这两个任务中,我们都使用了 Chain-of-Thought (CoT) 方法,要求大型语言模型在模拟执行过程中依次输出推理步骤。
如表8所示,Qwen2.5-Coder 在 CRUXEval-I 上获得了 56.5 分,在 CRUXEval-O 上获得了 56.0 分,这得益于我们在代码清理过程中对可执行代码质量的关注。
表8:各模型在 CRUXEval 的 Input-CoT 和 Output-CoT 设置下的表现
| 模型 | 参数量 | CRUXEval-I (Input-CoT) | CRUXEval-O (Output-CoT) |
|---|---|---|---|
| 1B+ 模型 | |||
| StarCoder2-3B | 3B | 42.1 | 29.2 |
| DS-Coder-1.3B-Base | 1.3B | 32.1 | 28.2 |
| Qwen2.5-Coder-1.5B | 1.5B | 43.8 | 34.6 |
| 6B+ 模型 | |||
| StarCoder2-7B | 7B | 39.5 | 35.1 |
| StarCoder2-15B | 15B | 46.1 | 47.6 |
| DS-Coder-6.7B-Base | 6.7B | 39.0 | 41.0 |
| DS-Coder-V2-Lite-Base | 2.4/16B | 53.4 | 46.1 |
| CodeQwen1.5-7B-Base | 7B | 44.8 | 40.1 |
| Qwen2.5-Coder-7B-Base | 7B | 56.5 | 56.0 |
| 20B+ 模型 | |||
| DS-Coder-33B-Base | 33B | 50.6 | 48.8 |
| DS-Coder-V2-Base | 21/236B | 62.7 | 67.4 |
Qwen2.5-Coder 在代码推理任务中展现出了极具竞争力的表现,尤其是在 CRUXEval 上显示了强大的推理能力。
6.4 数学推理
数学与编程一直有着紧密的联系。数学是编程的基础学科,而编程在数学领域中则是一个重要的工具。因此,我们期望一个强大且开放的代码模型在数学方面也能展现出色的能力。为评估 Qwen2.5-Coder 的数学表现,我们选择了五个流行的基准测试,包括 MATH(Hendrycks 等人,2021年)、GSM8K(Cobbe 等人,2021年)、MMLU-STEM(Hendrycks 等人,2020年)和 TheoremQA(Chen 等人,2023年)。如表9所示,Qwen2.5-Coder 在数学方面展现了强大的优势,可能归因于两个关键因素:首先是基于 Qwen2.5 强大的基础模型,其次是训练过程中对代码和数学数据的精心混合,确保了这两者之间的平衡表现。
表9:各种模型在 MATH、GSM8K、MMLU STEM 和 TheoremQA 四个数学基准测试中的表现
| 模型 | 参数量 | MATH (4-shot) | GSM8K (4-shot) | MMLU STEM (5-shot) | TheoremQA (5-shot) |
|---|---|---|---|---|---|
| 1B+ 模型 | |||||
| StarCoder2-3B | 3B | 10.8 | 21.6 | 34.9 | 12.1 |
| DS-Coder-1.3B-Base | 1.3B | 4.6 | 4.4 | 24.5 | 8.9 |
| Qwen2.5-Coder-1.5B | 1.5B | 30.9 | 65.8 | 49.0 | 21.4 |
| 6B+ 模型 | |||||
| StarCoder2-7B | 7B | 14.6 | 32.7 | 39.8 | 16.0 |
| StarCoder2-15B | 15B | 23.7 | 57.7 | 49.2 | 20.5 |
| DS-Coder-6.7B-Base | 6.7B | 10.3 | 21.3 | 34.2 | 13.6 |
| DS-Coder-V2-Lite-Base | 2.4/16B | 39.0 | 67.1 | 58.5 | 29.3 |
| CodeQwen1.5-7B-Base | 7B | 10.6 | 37.7 | 39.6 | 15.8 |
| Qwen2.5-Coder-7B-Base | 7B | 46.6 | 83.9 | 67.6 | 34.0 |
| 20B+ 模型 | |||||
| DS-Coder-33B-Base | 33B | 14.4 | 35.4 | 39.5 | 17.5 |
从表9中可以看到,Qwen2.5-Coder-1.5B 在1B+模型中表现最佳,而 Qwen2.5-Coder-7B-Base 在6B+和20B+模型中均展现了领先的数学推理能力,尤其是在GSM8K和MMLU STEM基准测试中表现突出。
6.5 MMLU 基准测试
MMLU(Massive Multitask Language Understanding)是一个用于评估通用知识的基准测试。我们评估了 Qwen2.5-Coder 在 MMLU 基准上的表现,并报告了两个设置下的结果:Base 和 Redux。
表10:不同模型在 MMLU 基准测试中的表现
| 模型 | 参数量 | MMLU Base | MMLU Redux |
|---|---|---|---|
| 1B+ 模型 | |||
| StarCoder2-3B | 3B | 36.6 | 37.0 |
| DS-Coder-1.3B-Base | 1.3B | 25.8 | 24.5 |
| Qwen2.5-Coder-1.5B | 1.5B | 53.6 | 50.9 |
| 6B+ 模型 | |||
| StarCoder2-7B | 7B | 38.8 | 38.6 |
| StarCoder2-15B | 15B | 64.1 | 48.8 |
| DS-Coder-6.7B-Base | 6.7B | 36.4 | 36.5 |
| DS-Coder-V2-Lite-Base | 2.4/16B | 60.5 | 58.3 |
| CodeQwen1.5-7B-Base | 7B | 40.5 | 41.2 |
| Qwen2.5-Coder-7B-Base | 7B | 68.0 | 66.6 |
| 20B+ 模型 | |||
| DS-Coder-33B-Base | 33B | 39.4 | 38.7 |
从表10可以看出,Qwen2.5-Coder-7B-Base 在MMLU基准测试中展现了出色的通用知识理解能力,明显超越了同类模型,并在 Redux 设置下达到了 66.6 的高分。
表11:不同模型在四个通用基准上的整体表现
| Model Size | 模型名称 | 参数量 | ARC-Challenge | TruthfulQA | WinoGrande | HellaSwag |
|---|---|---|---|---|---|---|
| 1B+ Models | StarCoder2-3B | 3B | 34.2 | 40.5 | 57.1 | 48.1 |
| DS-Coder-1.3B-Base | 1.3B | 25.4 | 42.7 | 53.3 | 39.5 | |
| Qwen2.5-Coder-1.5B | 1.5B | 45.2 | 44.0 | 60.7 | 61.8 | |
| 6B+ Models | StarCoder2-7B | 7B | 38.7 | 42.0 | 57.1 | 52.4 |
| StarCoder2-15B | 15B | 47.2 | 37.9 | 64.3 | 64.1 | |
| DS-Coder-6.7B-Base | 6.7B | 36.4 | 40.2 | 57.6 | 53.8 | |
| DS-Coder-V2-Lite-Base | 2.4/16B | 57.3 | 38.8 | 72.9 | - | |
| CodeQwen1.5-7B-Base | 7B | 35.7 | 42.2 | 59.8 | 56.0 | |
| Qwen2.5-Coder-7B-Base | 7B | 60.9 | 50.6 | 72.9 | 76.8 | |
| 20B+ Models | DS-Coder-33B-Base | 33B | 42.2 | 40.0 | 62.0 | 60.2 |
表11:不同模型在ARC-Challenge、TruthfulQA、WinoGrande和HellaSwag四个流行基准上的整体表现。
6.5 通用自然语言能力
除了数学能力之外,我们还希望尽可能保留基础模型的通用功能,例如通用知识。为了评估模型的自然语言理解能力,我们选择了MMLU (Hendrycks et al., 2021) 及其变体MMLU-Redux (Gema et al., 2024),以及其他四个基准:ARC-Challenge (Clark et al., 2018)、TruthfulQA (Lin et al., 2021)、WinoGrande (Sakaguchi et al., 2019) 和HellaSwag (Zellers et al., 2019)。与数学结果类似,表11突出显示了Qwen2.5-Coder在通用自然语言能力方面相较于其他模型的优势,进一步验证了Qwen2.5-Coder数据混合策略的有效性。
6.6 长上下文评估
长上下文处理能力对于代码类的大型语言模型(code LLMs)至关重要,这是理解代码仓库级别代码并成为代码代理的核心技能。然而,目前大多数代码模型对上下文长度的支持仍然非常有限,这阻碍了它们在实际应用中的潜力。Qwen2.5-Coder旨在进一步推进开源代码模型在长上下文建模方面的进展。为此,我们收集并构建了仓库级别的长序列代码数据用于预训练。通过仔细的数据比例配置与组织,我们使其支持最长128K tokens的输入长度。
Needle in the Code
我们设计了一个简单但基础的合成任务,名为Needle in the Code,灵感来自文本领域中的流行长上下文评估。在该任务中,我们在代码库中的不同位置插入了一个非常简单的自定义函数(我们选择Megatron 3作为致敬,感谢其对开源LLM的贡献!),并测试模型能否在代码库的末尾成功复现该函数。下图显示,Qwen2.5-Coder能够在128K长度范围内成功完成该任务。
7 指令模型评估
在对指令模型的评估中,我们严格评估了六个核心领域:代码生成、代码推理、代码编辑、text-to-SQL、数学推理和通用自然语言理解。评估的结构设计确保了各个模型之间的公平和全面比较。所有评估代码都是公开的,便于重现。为了确保广泛的比较,我们包括了一些最流行和广泛使用的开源指令微调模型,特别是来自DeepSeek-Coder系列和Codestral模型的不同版本。以下是本节中引用的所有模型版本列表。
| Artifact | Public link |
|---|---|
| Qwen2.5-Coder-1.5B-Instruct | https://hf.co/qwen/Qwen/Qwen2.5-Coder-1.5B-Instruct |
| Qwen2.5-Coder-7B-Instruct | https://hf.co/qwen/Qwen/Qwen2.5-Coder-7B-Instruct |
| CodeQwen1.5-7B-Chat | https://huggingface.co/Qwen/CodeQwen1.5-7B-Chat |
| CodeStral-22B | https://hf.co/mistralai/Codestral-22B-v0.1 |
| DS-Coder-1.3B-instruct | https://hf.co/deepseek-ai/deepseek-coder-1.3b-instruct |
| DS-Coder-6.7B-instruct | https://hf.co/deepseek-ai/deepseek-coder-6.7b-instruct |
| DS-Coder-33B-instruct | https://hf.co/deepseek-ai/deepseek-coder-33b-instruct |
| DS-Coder-V2-Lite-Instruct | https://hf.co/deepseek-ai/DeepSeek-Coder-V2-Lite-Instruct |
| DS-Coder-V2-Instruct | https://hf.co/deepseek-ai/DeepSeek-Coder-V2-Instruct |
表12:本节中发布和使用的所有模型版本。
7.1 代码生成
在Qwen2.5-Coder系列基础模型性能提升的基础上,Qwen2.5-Coder系列指令微调模型同样在代码生成任务中展示了卓越的表现。
HumanEval和MBPP
我们使用EvalPlus (Liu et al., 2023) 数据集评估了Qwen2.5-Coder系列指令微调模型的代码生成能力。如表13中的实验结果所示,Qwen2.5-Coder-7B-Instruct模型展现出了卓越的准确性,显著超越了其他具有类似参数规模的模型。令人瞩目的是,它甚至超过了参数量超过20亿的大模型,如CodeStral-22B和DS-Coder-33B-Instruct。特别值得一提的是,Qwen2.5-Coder-7B-Instruct是我们评估中唯一一个在HumanEval+任务上超越80%准确率的模型,达到了令人印象深刻的84.1%。
BigCodeBench-Instruct
BigCodeBench (Zhuo et al., 2024) 提供的指令集用于评估指令微调模型的代码生成能力。我们在BigCodeBench-Instruct上评估了Qwen2.5-Coder系列的指令微调模型。如表13所示,Qwen2.5-Coder-7B-Instruct在全集和难集上的准确率均超越了其他具有相似参数规模的指令微调模型,在全集上达到41.0%,在难集上达到18.2%,展示了Qwen2.5-Coder系列指令微调模型在代码生成能力方面的强大实力。
LiveCodeBench
LiveCodeBench (Jain et al., 2024) 是一个全面且无污染的基准,用于评估大型语言模型(LLMs)的编码能力。它不断从顶尖的编程竞赛平台(如LeetCode、AtCoder和CodeForces)收集新问题,确保一组最新和多样化的挑战。目前,该基准已包含600多个在2023年5月至2024年9月之间发布的高质量编码问题。
为了更好地展示我们模型在真实世界编程竞赛任务中的有效性,我们在LiveCodeBench (2305-2409) 数据集上对Qwen2.5-Coder系列指令微调模型进行了评估。如表13所示,Qwen2.5-Coder-7B-Instruct模型在Pass@1准确率上达到了37.6%,显著超越了其他具有相似参数规模的模型。特别值得注意的是,它还超过了参数量更大的模型,如CodeStral-22B和DS-Coder-33B-Instruct,进一步证明了Qwen2.5-Coder系列在应对复杂代码生成挑战方面的卓越能力。
多编程语言评估
Qwen2.5-Coder系列指令微调模型继承了基础模型在多编程语言任务中的高性能。为了进一步评估其能力,我们在两个特定的基准上对这些指令微调模型进行了测试:MultiPL-E (Cassano et al., 2022) 和 McEval (Chai et al., 2024)。
MultiPL-E
如表14中的评估结果所示,Qwen2.5-Coder-7B-Instruct在八种编程语言的代码生成任务中,持续超越了其他具有相同参数数量的模型,包括DS-Coder-V2-Lite-Instruct。Qwen2.5-Coder-7B-Instruct的平均准确率达到76.5%,甚至超过了参数量超过20亿的大模型,如CodeStral-22B和DS-Coder-33B-Instruct,突显了其在多编程语言代码生成任务中的强大能力。
McEval
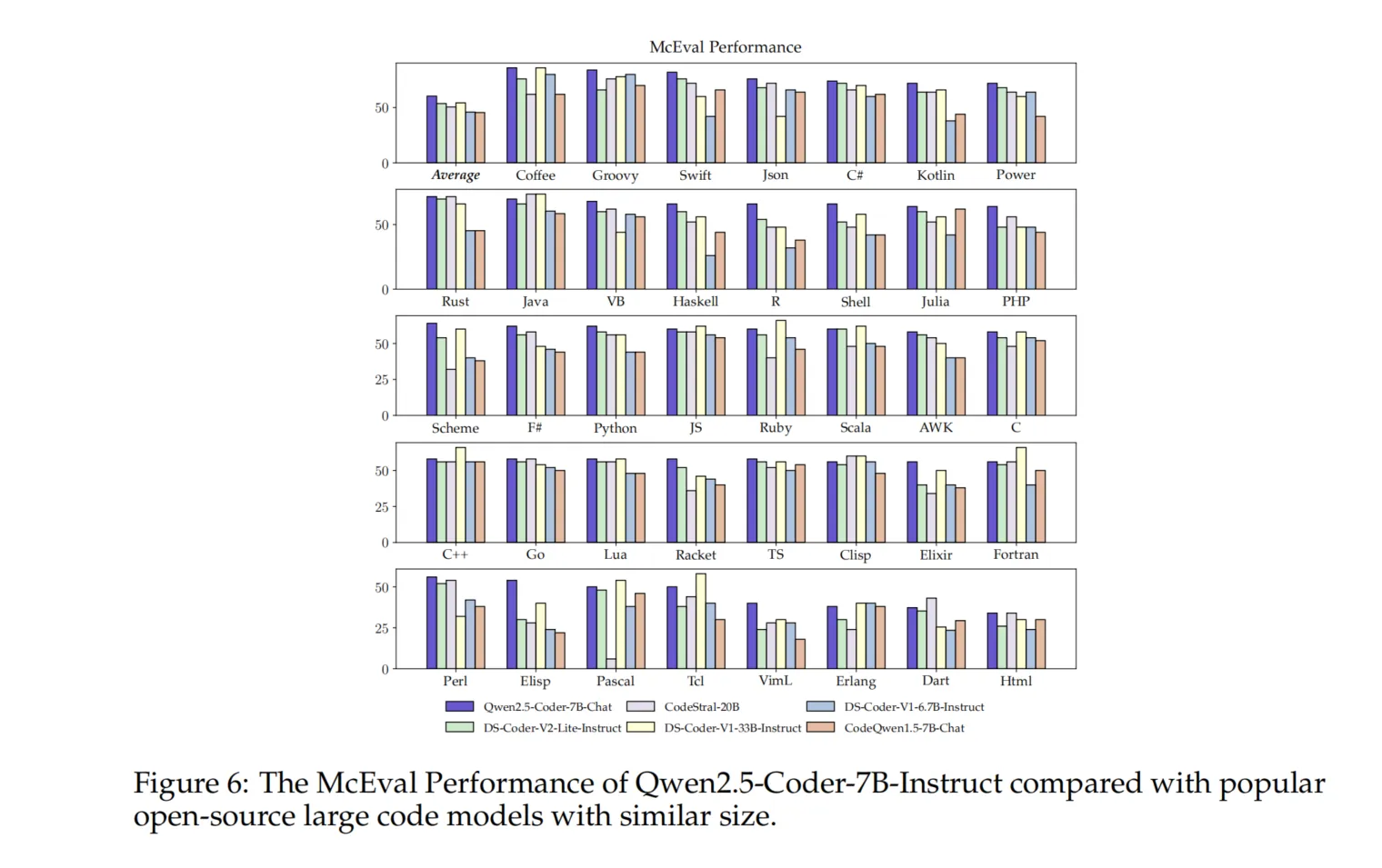
为了全面评估Qwen2.5-Coder系列模型在更广泛编程语言范围内的代码生成能力,我们在McEval (Chai et al., 2024) 基准上进行了评估,该基准涵盖了40种编程语言,包含16,000个测试用例。如图6所示,Qwen2.5-Coder-7B-Instruct模型在McEval基准中相较于其他开源模型表现出色,尤其是在广泛的编程语言上。其平均准确率不仅超越了参数量更大的模型(如DS-Coder-33B-Instruct和CodeStral-22B),还在同等参数规模的模型中展现了显著优势。
表13:不同指令模型在代码生成任务中的表现
| Model Size | HumanEval | MBPP | BigCodeBench | LiveCodeBench |
|---|---|---|---|---|
| HE | HE+ | MBPP | MBPP+ | |
| 1B+ Models | ||||
| DS-Coder-1.3B-Instruct | 1.3B | 65.2 | 61.6 | 61.6 |
| Qwen2.5-Coder-1.5B-Instruct | 1.5B | 70.7 | 66.5 | 69.2 |
| 6B+ Models | ||||
| DS-Coder-6.7B-Instruct | 6.7B | 78.6 | 70.7 | 75.1 |
| DS-Coder-V2-Lite-Instruct | 2.4/16B | 81.1 | 75.0 | 82.3 |
| CodeQwen1.5-7B-Chat | 7B | 86.0 | 79.3 | 83.3 |
| Qwen2.5-Coder-7B-Instruct | 7B | 88.4 | 84.1 | 83.5 |
| 20B+ Models | ||||
| CodeStral-22B | 22B | 78.1 | 74.4 | 73.3 |
| DS-Coder-33B-Instruct | 33B | 79.3 | 68.9 | 81.2 |
表14:不同方法在指令格式的MultiPL-E基准上的表现
| Model Size | Python | Java | C++ | C# | TS | JS | PHP | Bash | 平均值 |
|---|---|---|---|---|---|---|---|---|---|
| 1B+ Models | |||||||||
| DS-Coder-1.3B-Instruct | 1.3B | 65.2 | 51.9 | 45.3 | 55.1 | 59.7 | 52.2 | 45.3 | 12.7 |
| Qwen2.5-Coder-1.5B-Instruct | 1.5B | 71.2 | 55.7 | 50.9 | 64.6 | 61.0 | 62.1 | 59.0 | 29.1 |
| 6B+ Models | |||||||||
| DS-Coder-6.7B-Instruct | 6.7B | 78.6 | 68.4 | 63.4 | 72.8 | 67.2 | 72.7 | 68.9 | 36.7 |
| DS-Coder-V2-Lite-Instruct | 2.4/16B | 81.1 | 76.6 | 75.8 | 76.6 | 80.5 | 77.6 | 74.5 | 43.0 |
| CodeQwen1.5-7B-Chat | 7B | 83.5 | 70.9 | 72.0 | 75.9 | 76.7 |
| 77.6 | 73.9 | 41.8 | 71.6 | | Qwen2.5-Coder-7B-Instruct| 7B | 87.8 | 76.5 | 75.6 | 80.3 | 81.8 | 83.2 | 78.3 | 48.7 | 76.5 | | 20B+ Models | | | | | | | | | | | CodeStral-22B | 22B | 78.1 | 71.5 | 71.4 | 77.2 | 72.3 | 73.9 | 69.6 | 47.5 | 70.2 | | DS-Coder-33B-Instruct | 33B | 79.3 | 73.4 | 68.9 | 74.1 | 67.9 | 73.9 | 72.7 | 43.0 | 69.2 | | DS-Coder-V2-Instruct | 21/236B| 90.2 | 82.3 | 84.8 | 82.3 | 83.0 | 84.5 | 79.5 | 52.5 | 79.9 |
7.2 代码推理
为了评估 Qwen2.5-Coder 系列指令模型的代码推理能力,我们在 CRUXEval (Gu 等,2024)上进行了测试。如表15的实验结果所示,Qwen2.5-Coder-7B-Instruct 模型在 Input-CoT 和 Output-CoT 设置下的准确率分别达到了 65.8% 和 65.9%。相比 DS-Coder-V2-Lite-Instruct 模型,Qwen2.5-Coder-7B-Instruct 在 Input-CoT 准确率上提高了 12.8%,在 Output-CoT 准确率上提高了 13.0%,这是一个显著的提升。此外,Qwen2.5-Coder-7B-Instruct 还优于一些更大规模的模型,例如 CodeStral-22B 和 DS-Coder-33B-Instruct,这表明尽管其规模较小,但具有卓越的代码推理能力。
图7展示了模型规模与代码推理能力之间的关系。Qwen2.5-Coder 指令模型以较少的参数数量,显著超越了其他开源大语言模型,展现出卓越的代码推理性能。根据这一趋势,我们预计,在参数规模达到约 300 亿时,代码推理性能可能会与 GPT-4o 相媲美。
| 模型 | 参数规模 | CRUXEval 输入-CoT | 输出-CoT |
|---|---|---|---|
| 1B+ 模型 | |||
| DS-Coder-1.3B-Instruct | 1.3B | 14.8 | 28.1 |
| Qwen2.5-Coder-1.5B-Instruct | 1.5B | 45.4 | 37.5 |
| 6B+ 模型 | |||
| DS-Coder-6.7B-Instruct | 6.7B | 42.6 | 45.1 |
| DS-Coder-V2-Lite-Instruct | 2.4/16B | 53.0 | 52.9 |
| CodeQwen1.5-7B-Chat | 7B | 42.1 | 38.5 |
| Qwen2.5-Coder-7B-Instruct | 7B | 65.8 | 65.9 |
| 20B+ 模型 | |||
| CodeStral-22B | 22B | 48.0 | 60.6 |
| DS-Coder-33B-Instruct | 33B | 47.3 | 50.6 |
| DS-Coder-V2-Instruct | 21/236B | 70.0 | 75.1 |
表15: 不同指令模型在 CRUXEval 上的表现,包含 Input-CoT 和 Output-CoT 设置。
7.3 代码编辑
Aider 创建了一个代码编辑基准,用于定量测量其与大语言模型(LLMs)的协作能力。该基准基于从 Exercism 平台收集的 133 个 Python 练习,测试 Aider 和 LLMs 理解自然语言编程请求并将其转化为可执行代码的能力,要求这些代码能够成功通过单元测试。该评估不仅考察了模型的原始编码能力,还评估了模型编辑现有代码并将这些修改无缝集成到 Aider 系统中的效果,确保本地源文件的更新无误。此基准测试的综合性反映了 LLMs 的技术能力以及其任务完成的一致性。
表16展示了多个语言模型在代码编辑任务中的表现。其中,Qwen2.5-Coder-7B-Instruct 展现出了卓越的代码修复能力。尽管其规模只有 70 亿参数,但其 PASS@1 准确率达到了 50.4%,显著超越了同类模型。值得注意的是,它甚至超越了更大规模的模型,如 CodeStral-22B (220 亿参数)和 DS-Coder-33B-Instruct (330 亿参数),展示了其在代码编辑任务中的高效性和有效性。
7.4 文本到 SQL 转换
SQL 是日常软件开发和生产中的重要工具,但其陡峭的学习曲线常常阻碍非编程专家与数据库的自由交互。为了解决这一问题,提出了**文本到 SQL 转换(Text-to-SQL)**任务,旨在让模型能够自动将自然语言问题映射为结构化的 SQL 查询。此前,Text-to-SQL 的改进主要集中在结构感知学习、领域特定的预训练以及复杂的提示设计上。
通过在预训练和微调过程中使用精心设计的合成数据,我们显著提升了 Qwen2.5-Coder 在 Text-to-SQL 任务中的能力。我们选择了两个知名基准 Spider (Yu 等,2018)和 BIRD (Li 等,2024)进行全面评估。为了确保 Qwen2.5-Coder 与其他开源语言模型在该任务上的公平比较,我们按照 Chang & Fosler-Lussier (2023)的工作,使用统一的提示模板作为输入。图8展示了该提示模板,包含与数据库指令对齐的表格表示、表格内容示例、可选的附加知识以及自然语言问题。该标准化的提示模板最大限度地减少了因提示变化引起的偏差。正如图9所示,Qwen2.5-Coder 在 Text-to-SQL 任务中,超越了相同规模的其他代码模型。
7.5 数学推理和一般自然语言处理
在本节中,我们对比了 Qwen2.5-Coder-7B-Instruct 模型和 DS-Coder-V2-Lite-Instruct 模型在数学计算和一般自然语言处理任务中的表现。正如表17所示,Qwen2.5-Coder-7B-Instruct 在 12 项任务中的 11 项上超越了 DS-Coder-V2-Lite-Instruct,这进一步说明了该模型的多样性,不仅在复杂的编码任务中表现优异,在复杂的一般任务中也同样出色,充分展现了它与竞争对手的不同之处。
8 结论
本文介绍了 Qwen2.5-Coder,这是 Qwen 系列的最新成员。基于顶级开源大语言模型 Qwen2.5,通过对 Qwen2.5-1.5B 和 Qwen2.5-7B 进行大规模数据集的广泛预训练和后训练,我们开发了 Qwen2.5-Coder。为了确保预训练数据的质量,我们通过收集公共代码数据并从网络文本中提取高质量的代码相关内容,过滤掉低质量数据,精心设计了数据集。此外,我们还构建了一个精细设计的指令微调数据集,以将基础代码大语言模型转化为强大的编码助手。
展望未来,我们的研究将重点关注扩展代码大语言模型在数据规模和模型规模方面的影响。我们还将继续加强这些模型的推理能力,力求推动代码大语言模型的边界。
Footnotes
-
公开评估代码链接: https://hf.co ↩


本文作者:Dong
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 CC BY-NC。本作品采用《知识共享署名-非商业性使用 4.0 国际许可协议》进行许可。您可以在非商业用途下自由转载和修改,但必须注明出处并提供原作者链接。 许可协议。转载请注明出处!