目录
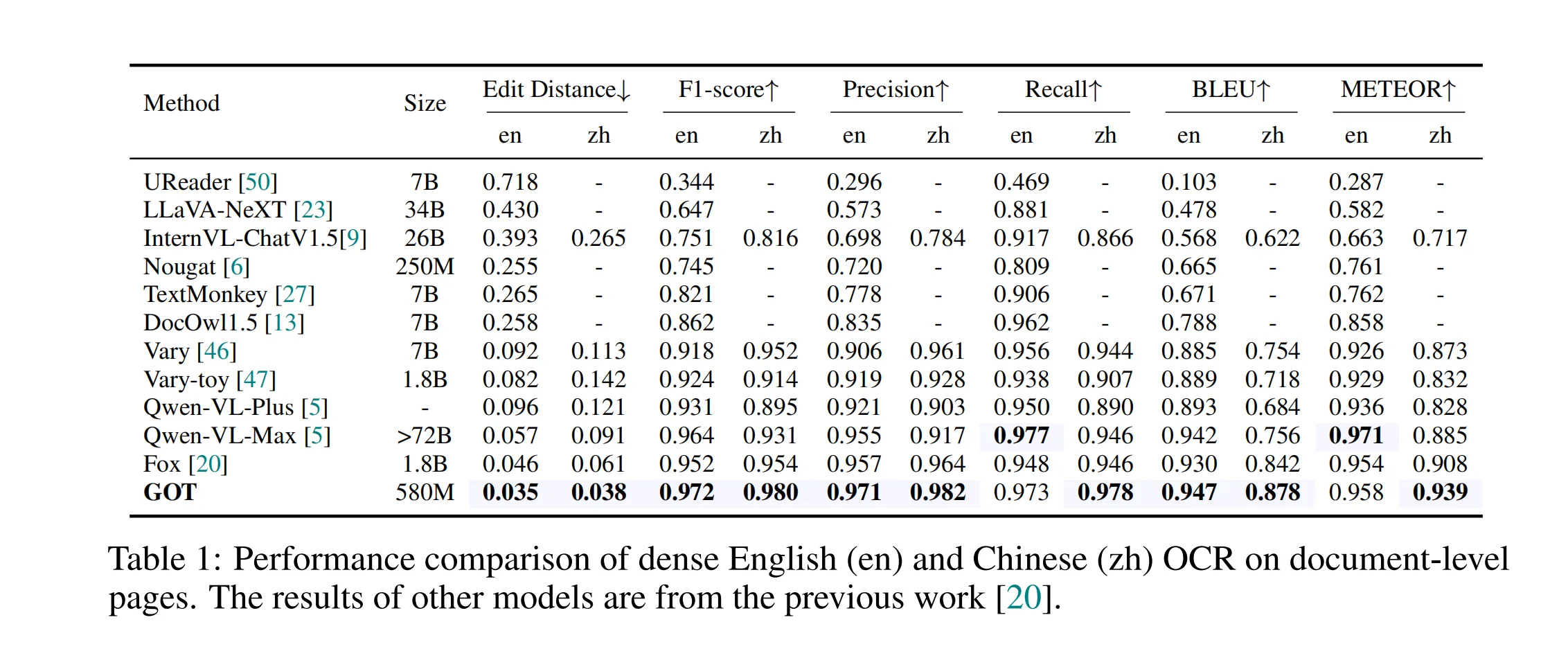
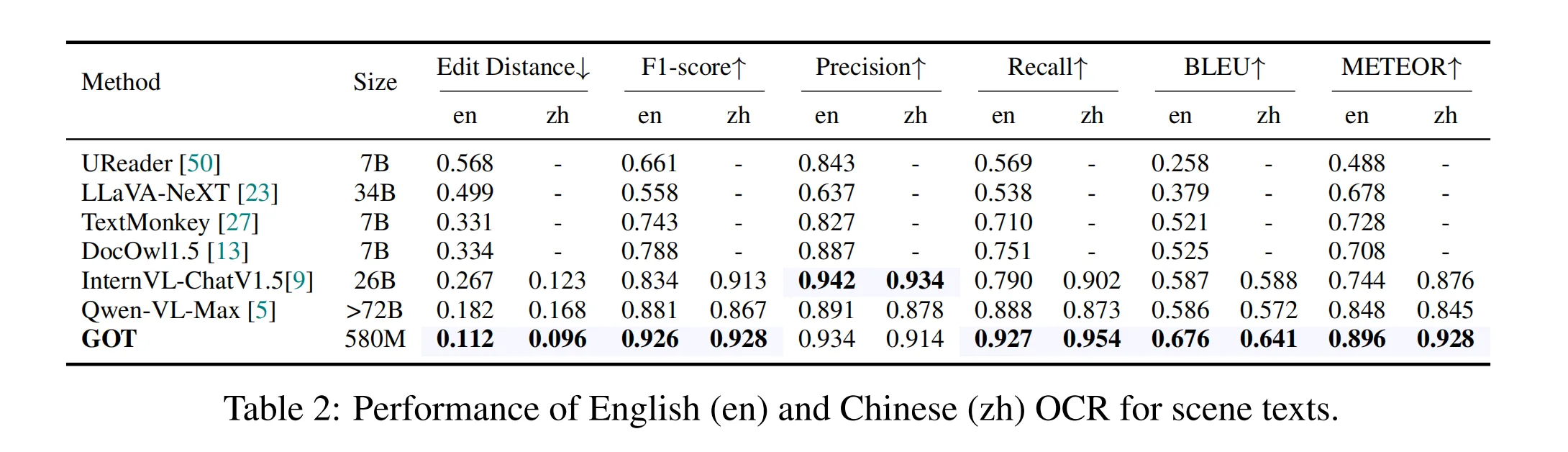
随着光学字符识别 (OCR) 技术的不断发展,传统的 OCR 系统已无法满足日益增长的智能处理需求。在《General OCR Theory》这篇论文中,作者提出了一种新的通用 OCR 理论,称之为 OCR 2.0,并开发了 GOT(General OCR Theory)模型。GOT 模型能够处理各种类型的字符,包括常规文本、数学公式、分子结构、图表、乐谱等,并支持多种 OCR 任务,如场景文本、文档级 OCR 和格式化输出。
这篇博客将对论文中的模型进行简要介绍,并详细解释如何使用 GOT OCR 2.0 进行配置,包括不同指令的使用和区别。
1. GOT OCR 2.0 简介
GOT 是一个端到端的 OCR 模型,具有如下特点:
- 统一架构:GOT 模型基于统一的编码器-解码器架构,无需复杂的多模块流程,降低了维护成本。
- 强大的通用性:GOT 支持识别更广泛的人工字符,包括乐谱、几何形状和表格等,输出结果可以是 Markdown、LaTeX 等格式。
- 多页与大图处理能力:GOT 支持动态分辨率、区域级别识别、多页 PDF 处理等功能,适应更复杂的 OCR 场景。
2. GOT OCR 配置指令详解
GOT OCR 提供了多种不同类型的 OCR 任务,用户可以根据具体需求进行配置。以下是常见的几种 OCR 模式及其指令详解:
2.1 普通文本识别(Plain Text OCR)
普通文本识别模式用于从图像中提取纯文本,无需处理复杂的格式或结构。
bash展开代码python3 GOT/demo/run_ocr_2.0.py --model-name /GOT_weights/ --image-file /an/image/file.png --type ocr
用途:适用于简单的场景,如从扫描图像中提取文本内容。
2.2 格式化文本识别(Formatted Text OCR)
格式化文本识别模式不仅提取文本,还会保留图像中的格式结构,如表格、公式等,并输出为 Markdown、LaTeX 等格式。
bash展开代码python3 GOT/demo/run_ocr_2.0.py --model-name /GOT_weights/ --image-file /an/image/file.png --type format
用途:适用于文档级别的 OCR 任务,尤其是在需要保留格式化输出的场景下,如科学论文、财务报告等。
2.3 细粒度 OCR(Fine-grained OCR)
细粒度 OCR 允许用户指定图像中的特定区域或颜色进行字符识别。可以通过坐标或颜色提示模型只识别感兴趣的区域或文本。
- 使用坐标指定区域:
bash展开代码python3 GOT/demo/run_ocr_2.0.py --model-name /GOT_weights/ --image-file /an/image/file.png --type format/ocr --box [x1,y1,x2,y2]
- 使用颜色指定区域:
bash展开代码python3 GOT/demo/run_ocr_2.0.py --model-name /GOT_weights/ --image-file /an/image/file.png --type format/ocr --color red/green/blue
用途:当需要仅识别图像的某些部分时,使用此功能可以提高效率,尤其适合标注丰富或图像内容复杂的文档。
2.4 多裁剪 OCR(Multi-crop OCR)
多裁剪模式将大图像分割为多个小块进行 OCR 处理,特别适合超大分辨率的图像或包含大量内容的页面。
bash展开代码python3 GOT/demo/run_ocr_2.0_crop.py --model-name /GOT_weights/ --image-file /an/image/file.png
用途:用于处理大图像(如高分辨率扫描图像),通过分块识别确保结果的精度。
2.5 多页 OCR(Multi-page OCR)
多页 OCR 模式用于批量处理多页文档,如 PDF 文件夹中的多张图片。无需逐页处理,自动化执行 OCR 任务。
bash展开代码python3 GOT/demo/run_ocr_2.0_crop.py --model-name /GOT_weights/ --image-file /images/path/ --multi-page
用途:适用于长文档或多页文件的 OCR 任务,提高效率。
2.6 格式化结果渲染(Render Formatted OCR Results)
该模式可以将 OCR 的格式化输出结果渲染为 HTML 格式,便于用户进行可视化查看。
bash展开代码python3 GOT/demo/run_ocr_2.0.py --model-name /GOT_weights/ --image-file /an/image/file.png --type format --render
用途:用于直观展示 OCR 的格式化输出,尤其是在需要查看 OCR 结果的排版和格式保留情况时。
3. docker
bash展开代码docker run -it --gpus all pytorch/pytorch:2.4.1-cuda12.1-cudnn9-devel bash
# 更新并安装必要的软件包
apt update && apt install -y git vim curl libgl1 libglib2.0-0 locales git-lfs
# 配置 Git LFS
curl -s https://packagecloud.io/install/repositories/github/git-lfs/script.deb.sh | bash
apt-get install git-lfs
# 设置本地化
locale-gen zh_CN.UTF-8
# 安装 Python 包
pip install -e . ninja flash-attn --no-build-isolation gradio transformers torch Pillow
# 升级 Gradio
pip install --upgrade gradio
# 清理缓存
apt clean && rm -rf /var/lib/apt/lists/*
docker push kevinchina/deeplearning:gotocr2.0webui
4. docker run
bash展开代码docker run -it --gpus all --net host kevinchina/deeplearning:gotocr2.0webui bash
5. Gradio Web UI
写个webui.py:
bash展开代码import gradio as gr
import subprocess
import os
import tempfile
from typing import List, Optional
from PIL import Image
# 定义OCR执行函数
def run_ocr(model_name: str, image_file: str, ocr_type: str, box: Optional[str] = '', color: Optional[str] = '', render: bool = False, multi_page: bool = False):
"""
运行OCR模型并返回结果。
:param model_name: 模型路径
:param image_file: 图像文件路径
:param ocr_type: OCR类型
:param box: 指定的框
:param color: 颜色过滤
:param render: 是否渲染结果
:param multi_page: 是否为多页处理
:return: OCR结果文本或渲染后的HTML内容
"""
cmd = ["python3", "GOT/demo/run_ocr_2.0.py", "--model-name", model_name, "--image-file", image_file, "--type", ocr_type]
if box:
cmd.extend(["--box", box])
if color:
cmd.extend(["--color", color])
if render:
cmd.append("--render")
if multi_page:
cmd.append("--multi-page")
try:
result = subprocess.run(cmd, capture_output=True, text=True, check=True)
if render:
# 读取渲染后的HTML文件内容
with open("./results/demo.html", "r", encoding='utf-8') as f:
html_content = f.read()
return html_content
else:
return result.stdout
except subprocess.CalledProcessError as e:
return f"Error: {e.stderr}"
# Plain Text OCR 回调函数
def plain_text_ocr(image):
with tempfile.NamedTemporaryFile(suffix=".png", delete=False) as tmp:
image.save(tmp.name)
result = run_ocr(model_name="../GOT-OCR2_0/", image_file=tmp.name, ocr_type="ocr")
os.unlink(tmp.name)
return result
# Format Text OCR 回调函数
def format_text_ocr(image):
with tempfile.NamedTemporaryFile(suffix=".png", delete=False) as tmp:
image.save(tmp.name)
result = run_ocr(model_name="../GOT-OCR2_0/", image_file=tmp.name, ocr_type="format")
os.unlink(tmp.name)
return result
# Fine-grained OCR 回调函数
def fine_grained_ocr(image, box, color):
with tempfile.NamedTemporaryFile(suffix=".png", delete=False) as tmp:
image.save(tmp.name)
ocr_type = "format/ocr" if box or color else "ocr"
result = run_ocr(model_name="../GOT-OCR2_0/", image_file=tmp.name, ocr_type=ocr_type, box=box, color=color)
os.unlink(tmp.name)
return result
# Multi-crop OCR 回调函数
def multi_crop_ocr(image):
with tempfile.NamedTemporaryFile(suffix=".png", delete=False) as tmp:
image.save(tmp.name)
cmd = ["python3", "GOT/demo/run_ocr_2.0_crop.py", "--model-name", "../GOT-OCR2_0/", "--image-file", tmp.name]
try:
result = subprocess.run(cmd, capture_output=True, text=True, check=True)
return result.stdout
except subprocess.CalledProcessError as e:
return f"Error: {e.stderr}"
finally:
os.unlink(tmp.name)
# Multi-page OCR 回调函数
def multi_page_ocr(image_gallery):
# image_gallery 是一个包含多张 PIL 图像的列表
if not image_gallery:
return "未上传任何图片。"
temp_dir = tempfile.mkdtemp()
image_paths = []
try:
for idx, img in enumerate(image_gallery):
img_path = os.path.join(temp_dir, f"page_{idx}.png")
img.save(img_path)
image_paths.append(img_path)
# 假设传递目录路径给OCR
cmd = ["python3", "GOT/demo/run_ocr_2.0_crop.py", "--model-name", "../GOT-OCR2_0/", "--image-file", temp_dir, "--multi-page"]
result = subprocess.run(cmd, capture_output=True, text=True, check=True)
return result.stdout
except subprocess.CalledProcessError as e:
return f"Error: {e.stderr}"
finally:
# 清理临时文件
for path in image_paths:
os.unlink(path)
os.rmdir(temp_dir)
# Render OCR Results 回调函数
def render_ocr(image):
with tempfile.NamedTemporaryFile(suffix=".png", delete=False) as tmp:
image.save(tmp.name)
html_content = run_ocr(model_name="../GOT-OCR2_0/", image_file=tmp.name, ocr_type="format", render=True)
os.unlink(tmp.name)
return html_content
# Helper function for uploading multiple files
def upload_file(files, current_images):
# files 是一个文件列表
images = [Image.open(file.name).convert("RGB") for file in files]
return images
# Placeholder callback functions for other tabs (if any)
def analyze_application(text, images):
# 这里可以根据具体需求实现分析逻辑
return "分析结果示例", "请求数据示例"
def empty_function():
return "执行结果示例"
# 创建Gradio界面
with gr.Blocks() as demo:
gr.Markdown("# GOT OCR 2.0 Gradio Web UI")
gr.Markdown("选择不同的OCR功能并上传相应的图像进行处理。")
with gr.Tab("Plain Text OCR"):
gr.Markdown("### 纯文本OCR")
with gr.Row():
plain_image = gr.Image(type="pil", label="上传图像")
plain_submit = gr.Button("运行OCR")
plain_output = gr.Textbox(label="OCR结果", lines=10)
plain_submit.click(fn=plain_text_ocr, inputs=plain_image, outputs=plain_output)
with gr.Tab("Format Text OCR"):
gr.Markdown("### 格式化文本OCR")
with gr.Row():
format_image = gr.Image(type="pil", label="上传图像")
format_submit = gr.Button("运行格式化OCR")
format_output = gr.Textbox(label="格式化OCR结果", lines=10)
format_submit.click(fn=format_text_ocr, inputs=format_image, outputs=format_output)
with gr.Tab("Fine-grained OCR"):
gr.Markdown("### 细粒度OCR")
with gr.Row():
fine_image = gr.Image(type="pil", label="上传图像")
with gr.Row():
box_input = gr.Textbox(label="框 (格式: [x1,y1,x2,y2])", placeholder="[100, 200, 300, 400]")
color_input = gr.Dropdown(choices=["", "red", "green", "blue"], label="颜色过滤", value="")
fine_submit = gr.Button("运行细粒度OCR")
fine_output = gr.Textbox(label="细粒度OCR结果", lines=10)
fine_submit.click(fn=fine_grained_ocr, inputs=[fine_image, box_input, color_input], outputs=fine_output)
with gr.Tab("Multi-crop OCR"):
gr.Markdown("### 多次裁剪OCR")
with gr.Row():
crop_image = gr.Image(type="pil", label="上传图像")
crop_submit = gr.Button("运行多裁剪OCR")
crop_output = gr.Textbox(label="多裁剪OCR结果", lines=10)
crop_submit.click(fn=multi_crop_ocr, inputs=crop_image, outputs=crop_output)
with gr.Tab("Multi-page OCR"):
gr.Markdown("### 多页OCR")
with gr.Row():
with gr.Column():
image_gallery = gr.Gallery(type='pil', label='图片列表(Photos)', height=250, columns=4, visible=True)
upload_button = gr.UploadButton("选择图片上传(Upload photos)", file_types=["image"], file_count="multiple")
clear_button = gr.Button("清空图片(Clear photos)")
with gr.Column():
multi_submit = gr.Button("运行多页OCR")
multi_output = gr.Textbox(label="多页OCR结果", lines=10)
# Handling image uploads and clear actions
user_images = gr.State([])
upload_button.upload(upload_file, inputs=[upload_button, user_images], outputs=image_gallery, queue=False)
clear_button.click(fn=lambda: [], inputs=None, outputs=image_gallery)
multi_submit.click(fn=multi_page_ocr, inputs=image_gallery, outputs=multi_output)
with gr.Tab("Render OCR Results"):
gr.Markdown("### 渲染OCR结果")
with gr.Row():
render_image = gr.Image(type="pil", label="上传图像")
render_submit = gr.Button("渲染OCR结果")
render_output = gr.HTML(label="渲染结果")
render_submit.click(fn=render_ocr, inputs=render_image, outputs=render_output)
gr.Markdown("© 2024 GOT OCR 2.0")
# 启动Gradio应用
demo.launch(server_name="0.0.0.0")
执行起来:
bash展开代码cd /workspace/GOT-OCR2.0/GOT-OCR-2.0-master
python webui.py
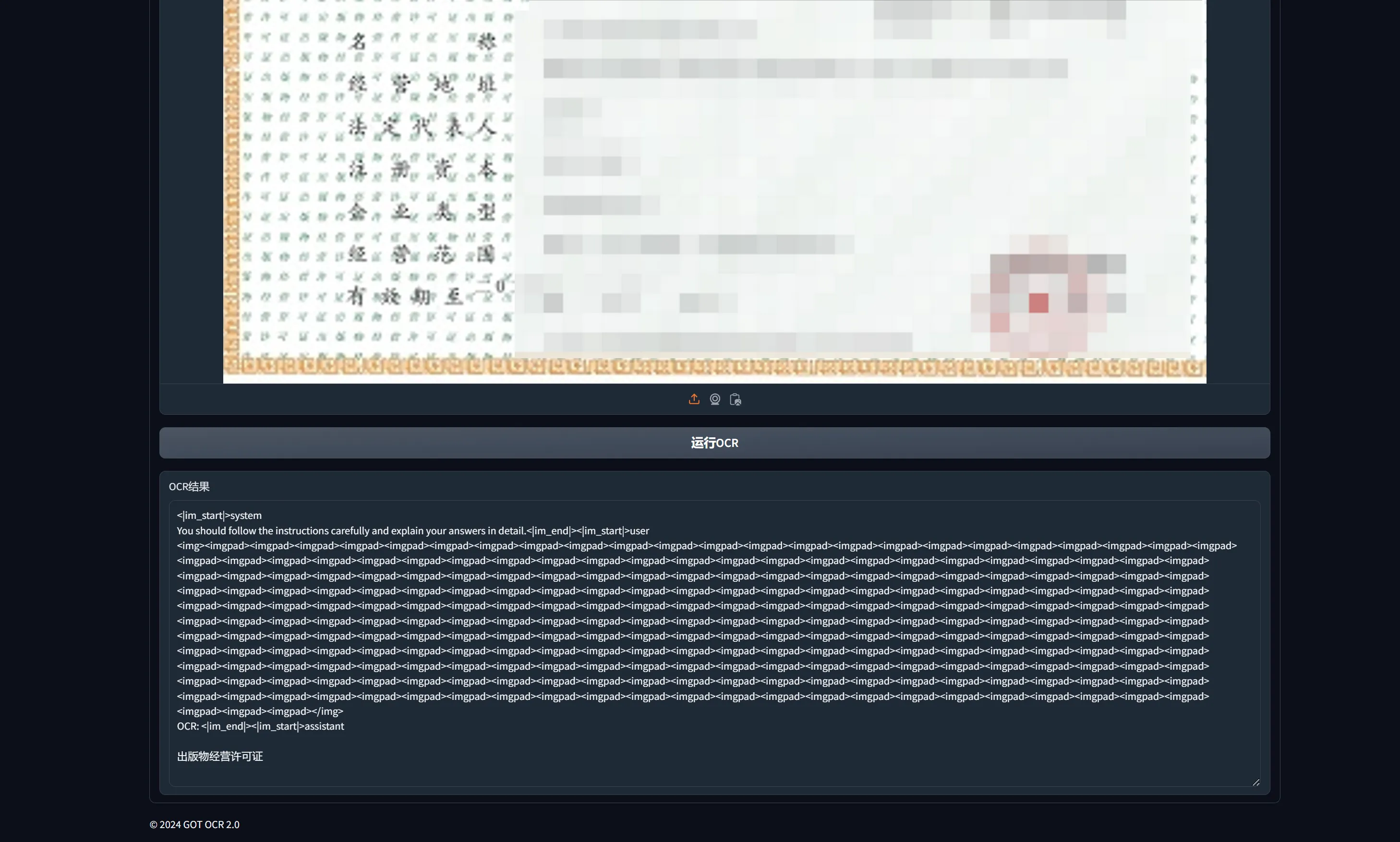
效果不是很好,对这种高级别水印基本是跪了,还是推荐qwenv2VL:


本文作者:Dong
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 CC BY-NC。本作品采用《知识共享署名-非商业性使用 4.0 国际许可协议》进行许可。您可以在非商业用途下自由转载和修改,但必须注明出处并提供原作者链接。 许可协议。转载请注明出处!