[数据结构与算法] 最长公共子序列 LCS问题 python
最长公共子序列(LCS)是一个在一个序列集合中(通常为两个序列)用来查找所有序列中最长子序列的问题。这与查找最长公共子串的问题不同的地方是:子序列不需要在原序列中占用连续的位置 。最长公共子序列问题是一个经典的计算机科学问题,也是数据比较程序,比如Diff工具,和生物信息学应用的基础。它也被广泛地应用在版本控制,比如Git用来调和文件之间的改变。
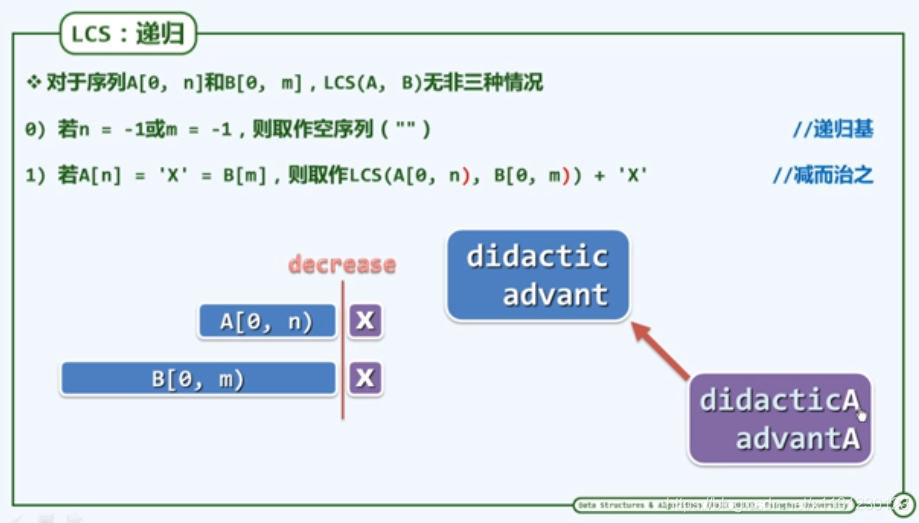
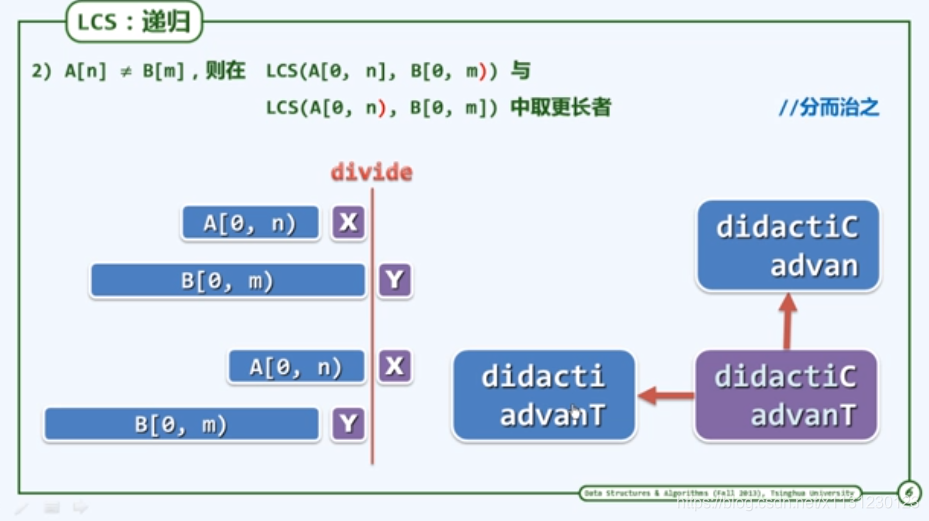
使用递归解决LCS问题
https://www.bilibili.com/video/av49361421?p=30
python实现
python展开代码def lcs_dp(input_x, input_y):
# input_y as column, input_x as row
dp = [([0] * (len(input_y) + 1)) for i in range(len(input_x) + 1)]
for i in range(1, len(input_x) + 1):
for j in range(1, len(input_y) + 1):
if input_x[i - 1] == input_y[j - 1]:
dp[i][j] = dp[i - 1][j - 1] + 1 # 这是一个规律 必定是左上角数字加1
else: # 不相等
dp[i][j] = max(dp[i - 1][j], dp[i][j - 1]) # 这是一个规律 必定是左边或者上面最大的数字
for dp_line in dp:
print(dp_line)
return dp[-1][-1]
x = list("412387ty")
y = list("g123ZX6789yt")
print(lcs_dp(x, y))
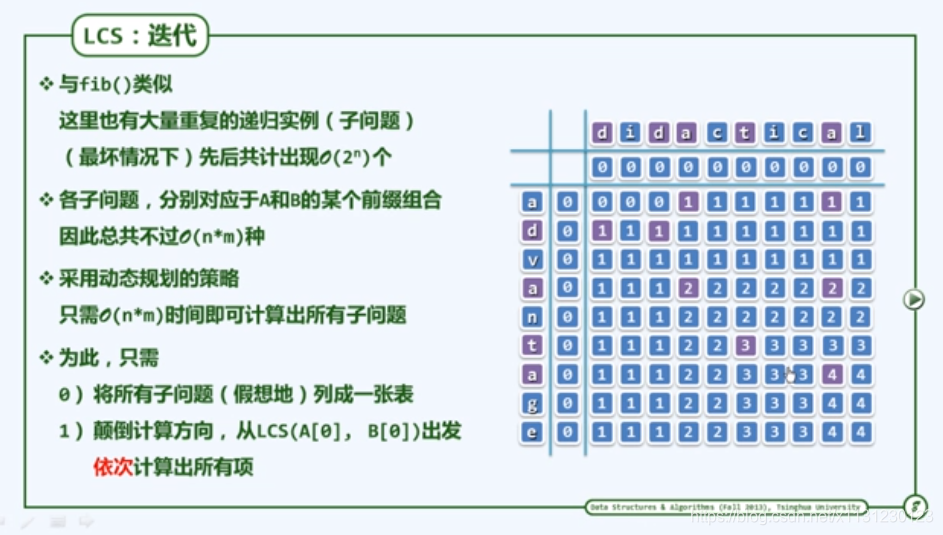
上面的代码的结果如下图,代码主要依据了2个规律给了矩阵。
对于给的x和y(x = list("412387ty")
y = list("g123ZX6789yt"))
这个最长公共子序列的解是多解的,如何给出所有符合的字符串?
下面代码给出了答案。
程序里加了一个subdp这样这个二维数组用于保存子序列。在矩阵从左到右从上到下这样一个Z字的更新过程中,在遇到相同点的时候:如果是新出来的节点,subdp这个二维列表在是直接在每一行(代表一个最长公共子序列)的最后面append此时相等的元素;如果是一样长的节点(多解),subdp这个二维列表会深度复制目前查找到的所有最长公共子序列,修改最后一个元素为此时相等的元素,然后作为新路径存入subdp。
python展开代码import copy
def lcs_dp(input_x, input_y):
# input_y as column, input_x as row
dp = [([0] * (len(input_y) + 1)) for i in range(len(input_x) + 1)]
num = 0
subdp = [[]]
subdp_temp=[]
for i in range(1, len(input_x) + 1):
for j in range(1, len(input_y) + 1):
if input_x[i - 1] == input_y[j - 1]:
dp[i][j] = dp[i - 1][j - 1] + 1 # 这是一个规律 必定是左上角数字加1
if num >= dp[i][j]:
# 这里的点是再次遇到一样的分支
for dp_i in range(len(subdp)):
subdp_temp=copy.deepcopy(subdp[dp_i])
subdp_temp[-1]=input_x[i - 1]
subdp.append(subdp_temp)
else:
for dp_i in range(len(subdp)):
subdp[dp_i].append(input_x[i - 1])
num = dp[i][j]
else: # 不相等
dp[i][j] = max(dp[i - 1][j], dp[i][j - 1]) # 这是一个规律 必定是左边或者上面最大的数字
for dp_line in dp:
print(dp_line)
return dp[-1][-1], subdp
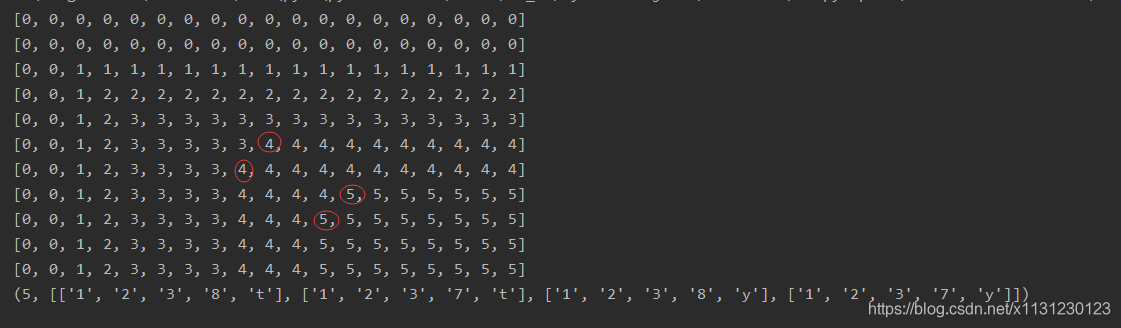
x = list("412387tyuu")
y = list("g123ZX6789ytopopop")
print(lcs_dp(x, y))
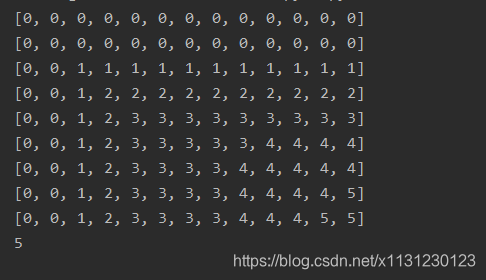
结果如下图
如果对你有用的话,可以打赏哦
打赏


本文作者:Dong
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 CC BY-NC。本作品采用《知识共享署名-非商业性使用 4.0 国际许可协议》进行许可。您可以在非商业用途下自由转载和修改,但必须注明出处并提供原作者链接。 许可协议。转载请注明出处!