目录
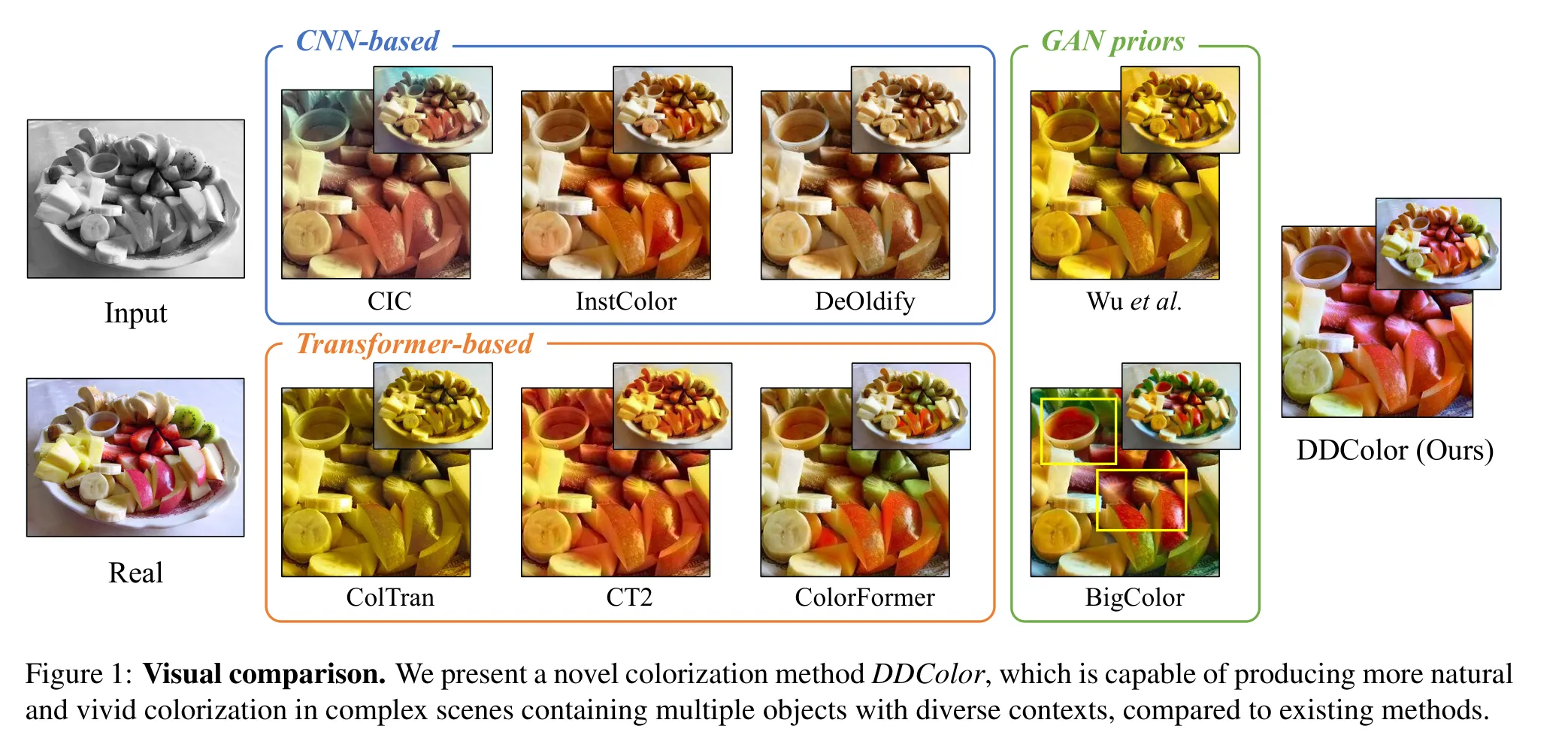
随着深度学习的兴起,自动上色引起了很多关注,目标是在复杂的图像语义(如形状、纹理和上下文)中生成合适的颜色。一些早期方法尝试使用卷积神经网络(CNN)预测每个像素的颜色分布。不幸的是,这些基于CNN的方法由于缺乏对图像语义的全面理解,通常会产生不正确或不饱和的上色结果(图1中的CIC、InstColor和DeOldify)。为了更好地理解语义信息,一些方法借助生成对抗网络(GANs),利用它们丰富的表示作为上色的生成先验。然而,由于GAN先验的表示空间有限,它们无法处理具有复杂结构和语义的图像,导致不合适的上色结果或不愉快的伪影(图1中的Wu等和BigColor)。
随着自然语言处理(NLP)的巨大成功,Transformer已经扩展到许多计算机视觉任务。最近,一些工作将Transformer的非局部注意力机制引入图像上色。尽管取得了令人满意的结果,这些方法要么训练了几个独立的子网,导致累积误差(图1中的ColTran),要么在单尺度图像特征图上执行颜色注意操作,在处理复杂图像上下文时会导致明显的颜色晕染(图1中的CT2和ColorFormer)。此外,这些方法通常依赖于手工制作的数据集级别的经验分布先验,如[45]中的颜色掩码和[47]中的语义-颜色映射,这些都是繁琐且难以推广的。
在本文中,我们提出了一种新颖的上色方法,即DDColor,旨在实现语义合理且视觉生动的上色。我们的方法利用了一个编码器-解码器结构,其中编码器提取图像特征,双解码器恢复空间分辨率。与先前方法采用额外网络或手工计算的先验来优化颜色概率不同,我们的方法使用基于查询的Transformer作为颜色解码器,以端到端的方式学习语义感知的颜色查询。通过使用多尺度图像特征进行颜色查询学习,我们的方法显着减轻了颜色晕染,并显着改善了复杂上下文和小物体的着色(见图1)。此外,我们提出了一种新的色彩度损失,以提高生成结果的颜色丰富度。
我们的主要贡献总结如下:
- 我们提出了一种带有双解码器的端到端网络,用于自动图像上色,确保了生动且语义一致的结果。
- 我们的方法包括一种新颖的颜色解码器,从视觉特征中学习颜色查询而无需依赖手工制作的先验。此外,我们的像素解码器提供多尺度语义表示来指导颜色查询的优化,有效减少了颜色晕染效应。
- 综合实验表明,我们的方法在与基线相比实现了最先进的性能,并表现出良好的泛化能力。
3. 方法
3.1 概述
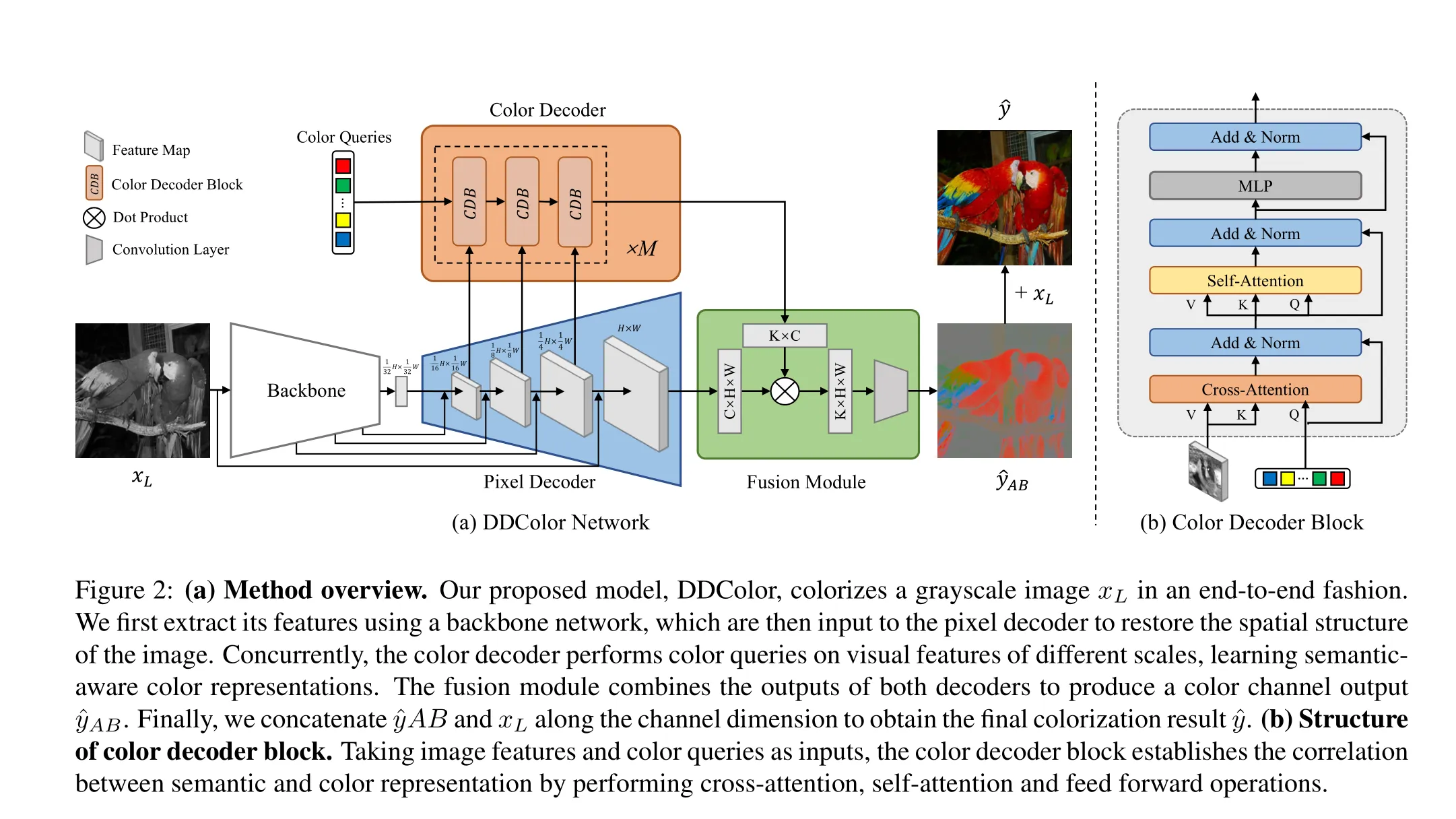
给定一个灰度输入图像 ,我们的上色网络预测缺失的两个颜色通道 ,其中 通道分别表示在 CIELAB 色彩空间中的明度和色度。网络采用编码器-解码器框架,如图2(a)所示。
我们利用一个backbone network作为编码器,从灰度图像中提取高级语义信息。backbone network旨在提取图像语义嵌入,这是上色视频化的关键。在本研究中,我们选择ConvNeXt [29],这是用于图像分类的最前沿模型。以 作为输入,backbone network 输出4个分辨率为 、、 和 的中间特征图。前三个特征图通过快捷连接传递到pixel decoder,而最后的特征图作为pixel decoder的输入。至于backbone network的结构,有几种选择,比如 ResNet[17]、Swin-Transformer[28] 等,只要网络能够生成分层表示。
我们的框架的解码器部分由像素解码器和色彩解码器组成。像素解码器使用一系列堆叠的上采样层来恢复图像特征的空间分辨率。每个上采样层与编码器的相应阶段有快捷连接。色彩解码器利用多尺度图像特征逐渐优化基于语义的颜色查询。最后,由两个解码器生成的图像和颜色特征融合生成彩色输出。
在接下来的部分中,我们将详细描述这些模块以及用于上色视频化的损失函数。
3.2 双重解码器
3.2.1 像素解码器
像素解码器由四个阶段组成,逐步扩大图像分辨率。每个阶段包括一个上采样层和一个快捷层。具体来说,不同于以前的方法使用反卷积 [34] 或插值 [30],我们采用 PixelShuffle [37] 作为上采样层。该层将形状为 的低分辨率特征图重新排列为形状为 的高分辨率特征图。快捷层使用卷积通过快捷连接整合来自编码器相应阶段的特征。
我们的方法通过逐步上采样过程捕获了完整的图像特征金字塔,这超出了某些基于transformer方法的能力 [24, 45]。这些多尺度特征进一步用作色彩解码器的输入,以指导颜色查询的优化。像素解码器的最终输出是图像嵌入 ,其空间分辨率与输入图像相同。
3.2.2 色彩解码器
许多现有的上色视频化方法依赖于额外的先验来实现生动的结果。例如,一些方法 [46, 13] 利用来自预训练的GAN的生成先验,而其他方法使用经验分布统计 [45] 或训练集的预构建语义-颜色对 [47]。然而,这些方法需要大量的预构建工作,并且在各种场景中可能具有有限的适用性。为了减少对手动设计先验的依赖,我们提出了一种新颖的基于查询的色彩解码器。
色彩解码器块。色彩解码器由一堆块组成,每个块接收视觉特征和颜色查询作为输入。色彩解码器块(CDB)基于修改过的transformer解码器设计,如图2(b)所示。
为了基于视觉语义信息学习一组自适应颜色查询,我们创建可学习的色彩嵌入记忆,以存储颜色表示序列:
这些颜色嵌入在训练阶段初始化为零,并在第一个CDB中用作颜色查询。我们首先通过cross-attention层建立语义表示与颜色嵌入之间的关联:
其中 是层索引, 是第 层的 维颜色嵌入。, 是图像特征,它们经过 和 变换,分别表示。 和 是图像特征的空间分辨率,, , 和 是线性变换。
通过上述cross-attention操作,颜色嵌入表示由图像特征丰富。然后,我们利用标准transformer层来变换颜色嵌入,如下:
其中 表示multi-head self-attention [42], 表示前馈网络, 是层归一化 [3]。值得注意的是,在所提出的CDB中,cross-attention在self-attention之前进行。这是因为在应用第一个self-attention层之前,颜色查询是零初始值且语义上独立。
扩展到多尺度。以前基于transformer的上色视频化方法通常在单一尺度图像特征图上执行颜色关注,未能充分捕捉低级语义线索,在处理复杂背景时可能导致颜色渗出。相反,多尺度特征已在许多计算机视觉任务中广泛探索,如物体检测 [26] 和实例分割 [16]。这些特征也可以提升上色的性能(详见Sec 4.3中的对比实验)。
为了平衡计算复杂度和表示能力,我们选择了三种不同尺度的图像特征。具体来说,我们使用pixel decoder生成的中间视觉特征,在色彩解码器中使用1/16、1/8和1/4的下采样率。我们将每组的3个CDB分组,在每组中,多尺度特征按顺序输入到CDB中。我们以轮转方式重复此组M次。总共,色彩解码器由3M个CDB组成。我们可以将色彩解码器公式化如下:
其中 和 是三种不同尺度的视觉特征。
在色彩解码器中使用多尺度特征可以建模颜色查询与视觉嵌入之间的关系,使得颜色嵌入对语义信息更敏感,进一步实现更准确的语义边界识别和减少颜色渗出。
3.3 融合模块
融合模块是一个轻量级模块,通过结合像素解码器和色彩解码器的输出生成彩色结果。如图2所示,融合模块的输入为每像素图像嵌入 ,其中 是嵌入维度,以及来自色彩解码器的语义感知颜色嵌入 ,其中 是颜色查询的数量。
融合模块将这两个嵌入聚合形成增强的特征 ,使用一个简单的点积。然后应用一个 卷积层生成最终输出 ,其表示AB颜色通道:
最后,通过将输出 与灰度输入 拼接,获得上色结果 。
3.4 目标
在训练阶段,采用以下四种损失:
像素损失。像素损失 是上色图像 和真实图像 之间的L1距离,提供像素级监督并鼓励生成类似于真实图像的输出。
感知损失。为了确保生成的图像 在语义上合理,我们使用感知损失 来最小化它与真实图像 之间的语义差异。这是通过使用预训练的 VGG16 [38] 从两个图像中提取特征来实现的。
对抗损失。添加一个 PatchGAN [23] 判别器来区分预测结果和真实图像,促使生成器生成无法区分的图像。令 表示对抗损失。
色彩丰富度损失。我们引入了一种新的色彩丰富度损失 ,其灵感来源于色彩丰富度分数 [15]。该损失鼓励模型生成更加丰富和视觉愉悦的图像。公式如下:
其中 和 分别表示颜色平面中像素云的标准差和均值,如 [15] 中所述。
生成器的全目标公式如下:
其中 和 是不同项的平衡权重。


本文作者:Dong
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 CC BY-NC。本作品采用《知识共享署名-非商业性使用 4.0 国际许可协议》进行许可。您可以在非商业用途下自由转载和修改,但必须注明出处并提供原作者链接。 许可协议。转载请注明出处!